 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Tree Search for High-Dimensional Computational Design
Jan 10, 2026High-dimensional design spaces underpin a wide range of physics-based modeling and computational design tasks in science and engineering. These problems are commonly formulated as constrained black-box searches over rugged objective landscapes, where function evaluations are expensive, and gradients are unavailable or unreliable. Conventional global search engines and optimizers struggle in such settings due to the exponential scaling of design spaces, the presence of multiple local basins, and the absence of physical guidance in sampling. We present a physics-informed Monte Carlo Tree Search (MCTS) framework that extends policy-driven tree-based reinforcement concepts to continuous, high-dimensional scientific optimization. Our method integrates population-level decision trees with surrogate-guided directional sampling, reward shaping, and hierarchical switching between global exploration and local exploitation. These ingredients allow efficient traversal of non-convex, multimodal landscapes where physically meaningful optima are sparse. We benchmark our approach against standard global optimization baselines on a suite of canonical test functions, demonstrating superior or comparable performance in terms of convergence, robustness, and generalization. Beyond synthetic tests, we demonstrate physics-consistent applicability to (i) crystal structure optimization from clusters to bulk, (ii) fitting of classical interatomic potentials, and (iii) constrained engineering design problems. Across all cases, the method converges with high fidelity and evaluation efficiency while preserving physical constraints. Overall, our work establishes physics-informed tree search as a scalable and interpretable paradigm for computational design and high-dimensional scientific optimization, bridging discrete decision-making frameworks with continuous search in scientific design workflows.
Extracting Complex Topology from Multivariate Functional Approximation: Contours, Jacobi Sets, and Ridge-Valley Graphs
Aug 11, 2025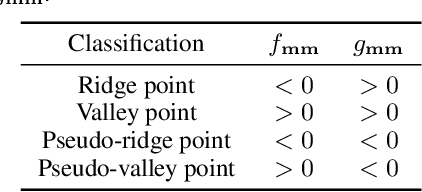
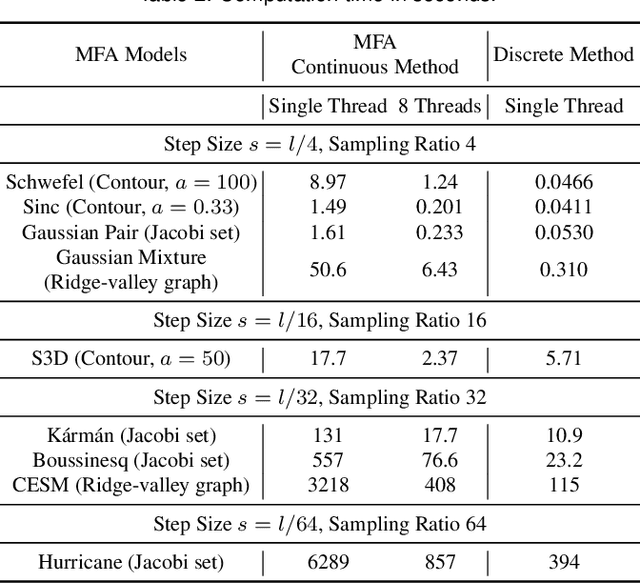
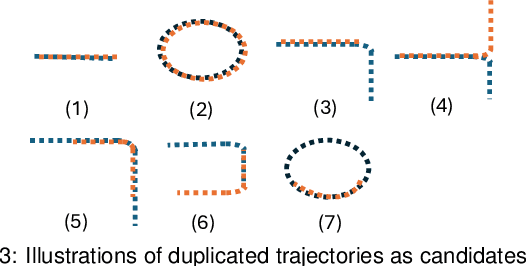
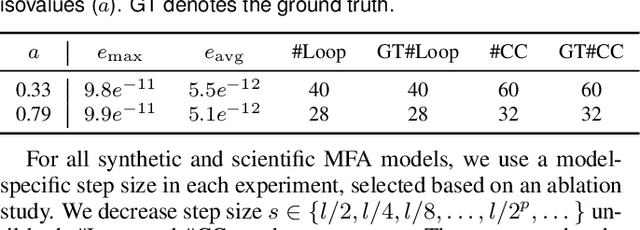
Implicit continuous models, such as functional models and implicit neural networks, are an increasingly popular method for replacing discrete data representations with continuous, high-order, and differentiable surrogates. These models offer new perspectives on the storage, transfer, and analysis of scientific data. In this paper, we introduce the first framework to directly extract complex topological features -- contours, Jacobi sets, and ridge-valley graphs -- from a type of continuous implicit model known as multivariate functional approximation (MFA). MFA replaces discrete data with continuous piecewise smooth functions. Given an MFA model as the input, our approach enables direct extraction of complex topological features from the model, without reverting to a discrete representation of the model. Our work is easily generalizable to any continuous implicit model that supports the queries of function values and high-order derivatives. Our work establishes the building blocks for performing topological data analysis and visualization on implicit continuous models.
ChatVis: Automating Scientific Visualization with a Large Language Model
Oct 07, 2024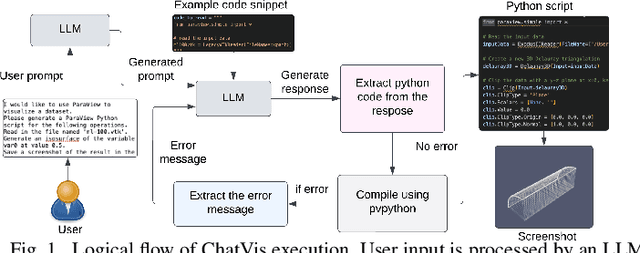

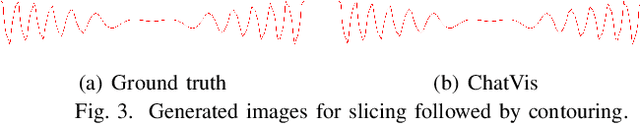

We develop an iterative assistant we call ChatVis that can synthetically generate Python scripts for data analysis and visualization using a large language model (LLM). The assistant allows a user to specify the operations in natural language, attempting to generate a Python script for the desired operations, prompting the LLM to revise the script as needed until it executes correctly. The iterations include an error detection and correction mechanism that extracts error messages from the execution of the script and subsequently prompts LLM to correct the error. Our method demonstrates correct execution on five canonical visualization scenarios, comparing results with ground truth. We also compared our results with scripts generated by several other LLMs without any assistance. In every instance, ChatVis successfully generated the correct script, whereas the unassisted LLMs failed to do so. The code is available on GitHub: https://github.com/tanwimallick/ChatVis/.
Regularized Multi-Decoder Ensemble for an Error-Aware Scene Representation Network
Jul 26, 2024



Feature grid Scene Representation Networks (SRNs) have been applied to scientific data as compact functional surrogates for analysis and visualization. As SRNs are black-box lossy data representations, assessing the prediction quality is critical for scientific visualization applications to ensure that scientists can trust the information being visualized. Currently, existing architectures do not support inference time reconstruction quality assessment, as coordinate-level errors cannot be evaluated in the absence of ground truth data. We propose a parameter-efficient multi-decoder SRN (MDSRN) ensemble architecture consisting of a shared feature grid with multiple lightweight multi-layer perceptron decoders. MDSRN can generate a set of plausible predictions for a given input coordinate to compute the mean as the prediction of the multi-decoder ensemble and the variance as a confidence score. The coordinate-level variance can be rendered along with the data to inform the reconstruction quality, or be integrated into uncertainty-aware volume visualization algorithms. To prevent the misalignment between the quantified variance and the prediction quality, we propose a novel variance regularization loss for ensemble learning that promotes the Regularized multi-decoder SRN (RMDSRN) to obtain a more reliable variance that correlates closely to the true model error. We comprehensively evaluate the quality of variance quantification and data reconstruction of Monte Carlo Dropout, Mean Field Variational Inference, Deep Ensemble, and Predicting Variance compared to the proposed MDSRN and RMDSRN across diverse scalar field datasets. We demonstrate that RMDSRN attains the most accurate data reconstruction and competitive variance-error correlation among uncertain SRNs under the same neural network parameter budgets.
Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization
Jul 16, 2023Scene representation networks (SRNs) have been recently proposed for compression and visualization of scientific data. However, state-of-the-art SRNs do not adapt the allocation of available network parameters to the complex features found in scientific data, leading to a loss in reconstruction quality. We address this shortcoming with an adaptively placed multi-grid SRN (APMGSRN) and propose a domain decomposition training and inference technique for accelerated parallel training on multi-GPU systems. We also release an open-source neural volume rendering application that allows plug-and-play rendering with any PyTorch-based SRN. Our proposed APMGSRN architecture uses multiple spatially adaptive feature grids that learn where to be placed within the domain to dynamically allocate more neural network resources where error is high in the volume, improving state-of-the-art reconstruction accuracy of SRNs for scientific data without requiring expensive octree refining, pruning, and traversal like previous adaptive models. In our domain decomposition approach for representing large-scale data, we train an set of APMGSRNs in parallel on separate bricks of the volume to reduce training time while avoiding overhead necessary for an out-of-core solution for volumes too large to fit in GPU memory. After training, the lightweight SRNs are used for realtime neural volume rendering in our open-source renderer, where arbitrary view angles and transfer functions can be explored. A copy of this paper, all code, all models used in our experiments, and all supplemental materials and videos are available at https://github.com/skywolf829/APMGSRN.
Neural Stream Functions
Jul 16, 2023We present a neural network approach to compute stream functions, which are scalar functions with gradients orthogonal to a given vector field. As a result, isosurfaces of the stream function extract stream surfaces, which can be visualized to analyze flow features. Our approach takes a vector field as input and trains an implicit neural representation to learn a stream function for that vector field. The network learns to map input coordinates to a stream function value by minimizing the inner product of the gradient of the neural network's output and the vector field. Since stream function solutions may not be unique, we give optional constraints for the network to learn particular stream functions of interest. Specifically, we introduce regularizing loss functions that can optionally be used to generate stream function solutions whose stream surfaces follow the flow field's curvature, or that can learn a stream function that includes a stream surface passing through a seeding rake. We also discuss considerations for properly visualizing the trained implicit network and extracting artifact-free surfaces. We compare our results with other implicit solutions and present qualitative and quantitative results for several synthetic and simulated vector fields.
Reinforcement Learning for Load-balanced Parallel Particle Tracing
Sep 13, 2021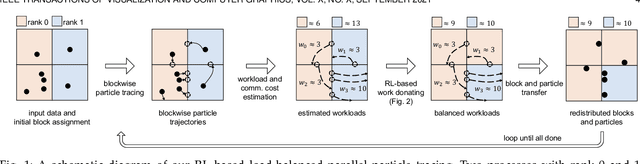



We explore an online learning reinforcement learning (RL) paradigm for optimizing parallel particle tracing performance in distributed-memory systems. Our method combines three novel components: (1) a workload donation model, (2) a high-order workload estimation model, and (3) a communication cost model, to optimize the performance of data-parallel particle tracing dynamically. First, we design an RL-based workload donation model. Our workload donation model monitors the workload of processes and creates RL agents to donate particles and data blocks from high-workload processes to low-workload processes to minimize the execution time. The agents learn the donation strategy on-the-fly based on reward and cost functions. The reward and cost functions are designed to consider the processes' workload change and the data transfer cost for every donation action. Second, we propose an online workload estimation model, in order to help our RL model estimate the workload distribution of processes in future computations. Third, we design the communication cost model that considers both block and particle data exchange costs, helping the agents make effective decisions with minimized communication cost. We demonstrate that our algorithm adapts to different flow behaviors in large-scale fluid dynamics, ocean, and weather simulation data. Our algorithm improves parallel particle tracing performance in terms of parallel efficiency, load balance, and costs of I/O and communication for evaluations up to 16,384 processors.
InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations
Aug 18, 2019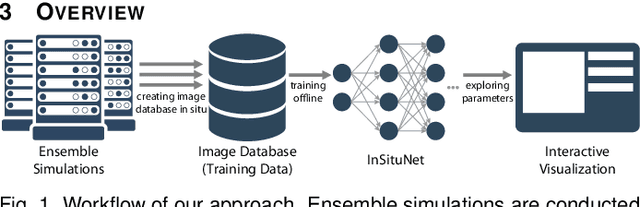
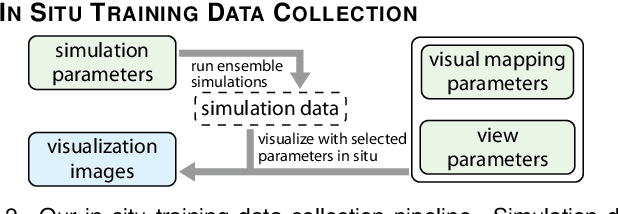
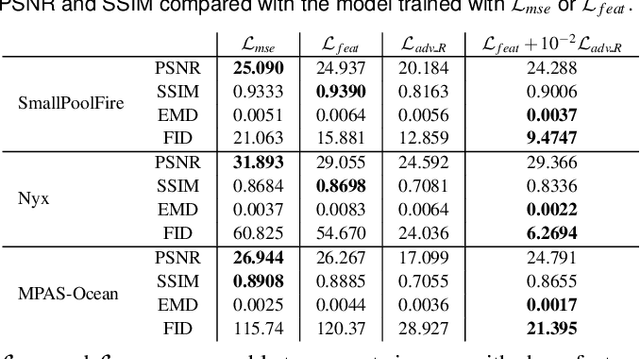
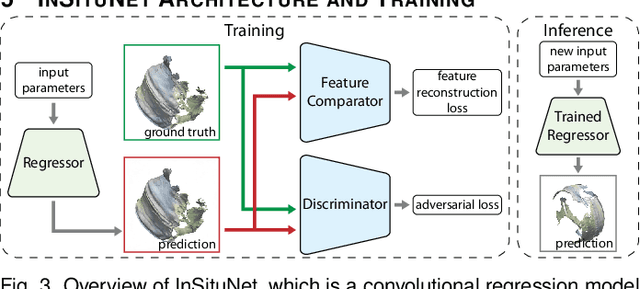
We propose InSituNet, a deep learning based surrogate model to support parameter space exploration for ensemble simulations that are visualized in situ. In situ visualization, generating visualizations at simulation time, is becoming prevalent in handling large-scale simulations because of the I/O and storage constraints. However, in situ visualization approaches limit the flexibility of post-hoc exploration because the raw simulation data are no longer available. Although multiple image-based approaches have been proposed to mitigate this limitation, those approaches lack the ability to explore the simulation parameters. Our approach allows flexible exploration of parameter space for large-scale ensemble simulations by taking advantage of the recent advances in deep learning. Specifically, we design InSituNet as a convolutional regression model to learn the mapping from the simulation and visualization parameters to the visualization results. With the trained model, users can generate new images for different simulation parameters under various visualization settings, which enables in-depth analysis of the underlying ensemble simulations. We demonstrate the effectiveness of InSituNet in combustion, cosmology, and ocean simulations through quantitative and qualitative evaluations.