 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Stream Functions
Jul 16, 2023We present a neural network approach to compute stream functions, which are scalar functions with gradients orthogonal to a given vector field. As a result, isosurfaces of the stream function extract stream surfaces, which can be visualized to analyze flow features. Our approach takes a vector field as input and trains an implicit neural representation to learn a stream function for that vector field. The network learns to map input coordinates to a stream function value by minimizing the inner product of the gradient of the neural network's output and the vector field. Since stream function solutions may not be unique, we give optional constraints for the network to learn particular stream functions of interest. Specifically, we introduce regularizing loss functions that can optionally be used to generate stream function solutions whose stream surfaces follow the flow field's curvature, or that can learn a stream function that includes a stream surface passing through a seeding rake. We also discuss considerations for properly visualizing the trained implicit network and extracting artifact-free surfaces. We compare our results with other implicit solutions and present qualitative and quantitative results for several synthetic and simulated vector fields.
Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization
Jul 16, 2023Scene representation networks (SRNs) have been recently proposed for compression and visualization of scientific data. However, state-of-the-art SRNs do not adapt the allocation of available network parameters to the complex features found in scientific data, leading to a loss in reconstruction quality. We address this shortcoming with an adaptively placed multi-grid SRN (APMGSRN) and propose a domain decomposition training and inference technique for accelerated parallel training on multi-GPU systems. We also release an open-source neural volume rendering application that allows plug-and-play rendering with any PyTorch-based SRN. Our proposed APMGSRN architecture uses multiple spatially adaptive feature grids that learn where to be placed within the domain to dynamically allocate more neural network resources where error is high in the volume, improving state-of-the-art reconstruction accuracy of SRNs for scientific data without requiring expensive octree refining, pruning, and traversal like previous adaptive models. In our domain decomposition approach for representing large-scale data, we train an set of APMGSRNs in parallel on separate bricks of the volume to reduce training time while avoiding overhead necessary for an out-of-core solution for volumes too large to fit in GPU memory. After training, the lightweight SRNs are used for realtime neural volume rendering in our open-source renderer, where arbitrary view angles and transfer functions can be explored. A copy of this paper, all code, all models used in our experiments, and all supplemental materials and videos are available at https://github.com/skywolf829/APMGSRN.
Reinforcement Learning for Load-balanced Parallel Particle Tracing
Sep 13, 2021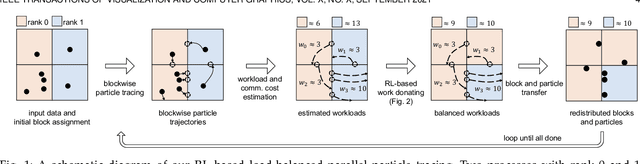



We explore an online learning reinforcement learning (RL) paradigm for optimizing parallel particle tracing performance in distributed-memory systems. Our method combines three novel components: (1) a workload donation model, (2) a high-order workload estimation model, and (3) a communication cost model, to optimize the performance of data-parallel particle tracing dynamically. First, we design an RL-based workload donation model. Our workload donation model monitors the workload of processes and creates RL agents to donate particles and data blocks from high-workload processes to low-workload processes to minimize the execution time. The agents learn the donation strategy on-the-fly based on reward and cost functions. The reward and cost functions are designed to consider the processes' workload change and the data transfer cost for every donation action. Second, we propose an online workload estimation model, in order to help our RL model estimate the workload distribution of processes in future computations. Third, we design the communication cost model that considers both block and particle data exchange costs, helping the agents make effective decisions with minimized communication cost. We demonstrate that our algorithm adapts to different flow behaviors in large-scale fluid dynamics, ocean, and weather simulation data. Our algorithm improves parallel particle tracing performance in terms of parallel efficiency, load balance, and costs of I/O and communication for evaluations up to 16,384 processors.