 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Amortized Fitting of Scientific Signals Across Time and Ensembles via Transferable Neural Fields
Apr 21, 2026Neural fields, also known as implicit neural representations (INRs), offer a powerful framework for modeling continuous geometry, but their effectiveness in high-dimensional scientific settings is limited by slow convergence and scaling challenges. In this study, we extend INR models to handle spatiotemporal and multivariate signals and show how INR features can be transferred across scientific signals to enable efficient and scalable representation across time and ensemble runs in an amortized fashion. Across controlled transformation regimes (e.g., geometric transformations and localized perturbations of synthetic fields) and high-fidelity scientific domains-including turbulent flows, fluid-material impact dynamics, and astrophysical systems-we show that transferable features improve not only signal fidelity but also the accuracy of derived geometric and physical quantities, including density gradients and vorticity. In particular, transferable features reduce iterations to reach target reconstruction quality by up to an order of magnitude, increase early-stage reconstruction quality by multiple dB (with gains exceeding 10 dB in some cases), and consistently improve gradient-based physical accuracy.
SciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
Extracting Complex Topology from Multivariate Functional Approximation: Contours, Jacobi Sets, and Ridge-Valley Graphs
Aug 11, 2025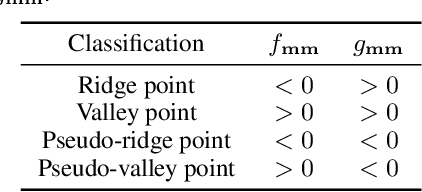
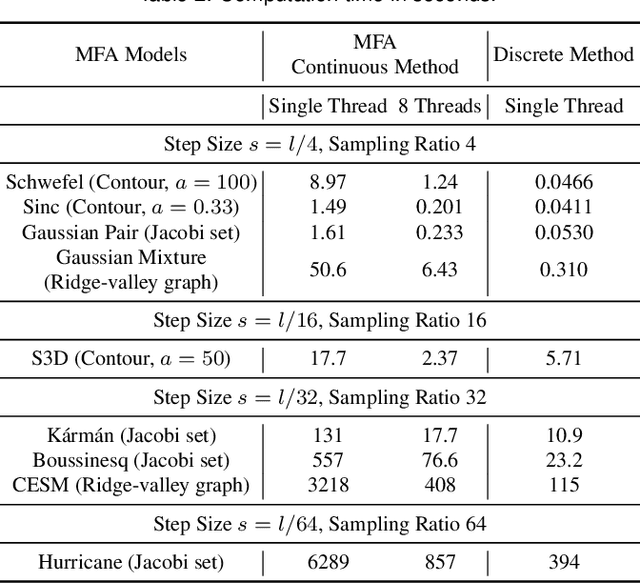
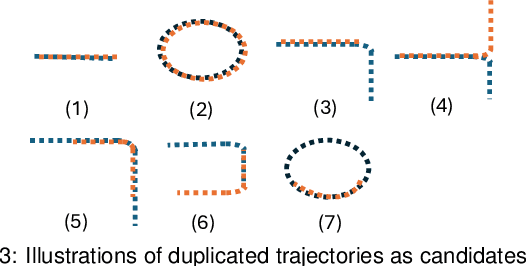
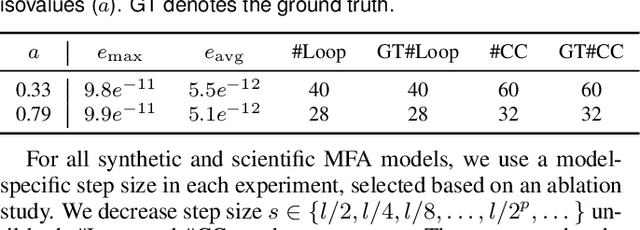
Implicit continuous models, such as functional models and implicit neural networks, are an increasingly popular method for replacing discrete data representations with continuous, high-order, and differentiable surrogates. These models offer new perspectives on the storage, transfer, and analysis of scientific data. In this paper, we introduce the first framework to directly extract complex topological features -- contours, Jacobi sets, and ridge-valley graphs -- from a type of continuous implicit model known as multivariate functional approximation (MFA). MFA replaces discrete data with continuous piecewise smooth functions. Given an MFA model as the input, our approach enables direct extraction of complex topological features from the model, without reverting to a discrete representation of the model. Our work is easily generalizable to any continuous implicit model that supports the queries of function values and high-order derivatives. Our work establishes the building blocks for performing topological data analysis and visualization on implicit continuous models.
ChatVis: Automating Scientific Visualization with a Large Language Model
Oct 07, 2024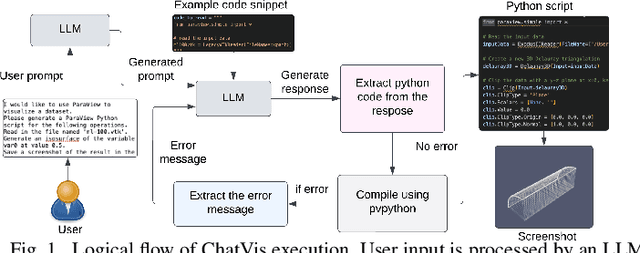

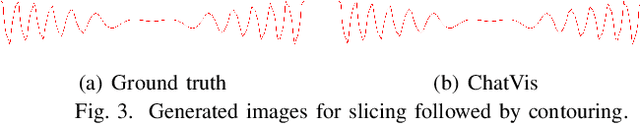

We develop an iterative assistant we call ChatVis that can synthetically generate Python scripts for data analysis and visualization using a large language model (LLM). The assistant allows a user to specify the operations in natural language, attempting to generate a Python script for the desired operations, prompting the LLM to revise the script as needed until it executes correctly. The iterations include an error detection and correction mechanism that extracts error messages from the execution of the script and subsequently prompts LLM to correct the error. Our method demonstrates correct execution on five canonical visualization scenarios, comparing results with ground truth. We also compared our results with scripts generated by several other LLMs without any assistance. In every instance, ChatVis successfully generated the correct script, whereas the unassisted LLMs failed to do so. The code is available on GitHub: https://github.com/tanwimallick/ChatVis/.
Evaluating TCFD Reporting: A New Application of Zero-Shot Analysis to Climate-Related Financial Disclosures
Feb 01, 2023
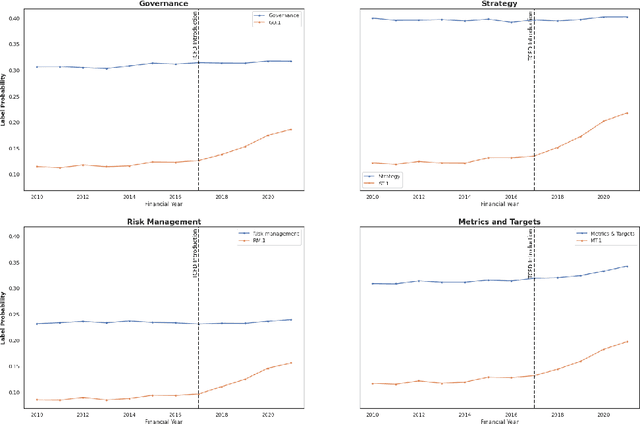
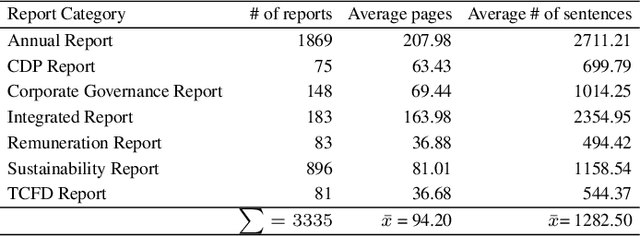
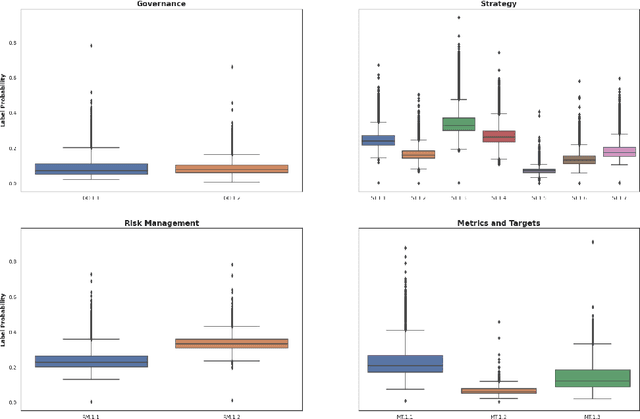
We examine climate-related disclosures in a large sample of reports published by banks that officially endorsed the recommendations of the Task Force for Climate-related Financial Disclosures (TCFD). In doing so, we introduce a new application of the zero-shot text classification. By developing a set of fine-grained TCFD labels, we show that zero-shot analysis is a useful tool for classifying climate-related disclosures without further model training. Overall, our findings indicate that corporate climate-related disclosures grew dynamically after the launch of the TCFD recommendations. However, there are marked differences in the extent of reporting by recommended disclosure topic, suggesting that some recommendations have not yet been fully met. Our findings yield important conclusions for the design of climate-related disclosure frameworks.