 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Editing: A Versatile Framework for Cross-Architecture Attention Conversion
Apr 07, 2026Key-Value (KV) cache memory and bandwidth increasingly dominate large language model inference cost in long-context and long-generation regimes. Architectures such as multi-head latent attention (MLA) and hybrid sliding-window attention (SWA) can alleviate this bound, but integrating them into existing models remains difficult. Prior methods impose fine-grained structural requirements on both source and target attention modules, which cannot meet the feasible requirement in practical deployment. We present Attention Editing, a practical framework for converting already-trained large language models (LLMs) with new attention architectures without re-pretraining from scratch. Attention editing replaces the original attention with a learnable target module and trains it using progressive distillation, consisting of (1) layer-wise teacher-forced optimization with intermediate activation supervision to prevent cold-start error accumulation, and (2) model-level distillation on next-token distributions, optionally regularized by weak feature matching. We instantiate the framework on two different target--MLA and GateSWA, a gated hybrid SWA design, and apply it to Qwen3-8B and Qwen3-30B-A3B. The resulting models maintain competitive performance while delivering substantial efficiency improvements, demonstrating that large-scale attention conversion is both feasible and robust. Notably, experiments are conducted on an Ascend 910B clusters, offering a practical training case study on domestic hardware.
Spike Imaging Velocimetry: Dense Motion Estimation of Fluids Using Spike Cameras
Apr 26, 2025


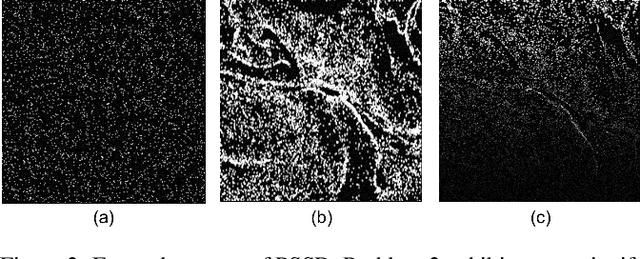
The need for accurate and non-intrusive flow measurement methods has led to the widespread adoption of Particle Image Velocimetry (PIV), a powerful diagnostic tool in fluid motion estimation. This study investigates the tremendous potential of spike cameras (a type of ultra-high-speed, high-dynamic-range camera) in PIV. We propose a deep learning framework, Spike Imaging Velocimetry (SIV), designed specifically for highly turbulent and intricate flow fields. To aggregate motion features from the spike stream while minimizing information loss, we incorporate a Detail-Preserving Hierarchical Transform (DPHT) module. Additionally, we introduce a Graph Encoder (GE) to extract contextual features from highly complex fluid flows. Furthermore, we present a spike-based PIV dataset, Particle Scenes with Spike and Displacement (PSSD), which provides labeled data for three challenging fluid dynamics scenarios. Our proposed method achieves superior performance compared to existing baseline methods on PSSD. The datasets and our implementation of SIV are open-sourced in the supplementary materials.
Inter-event Interval Microscopy for Event Cameras
Apr 08, 2025Event cameras, an innovative bio-inspired sensor, differ from traditional cameras by sensing changes in intensity rather than directly perceiving intensity and recording these variations as a continuous stream of "events". The intensity reconstruction from these sparse events has long been a challenging problem. Previous approaches mainly focused on transforming motion-induced events into videos or achieving intensity imaging for static scenes by integrating modulation devices at the event camera acquisition end. In this paper, for the first time, we achieve event-to-intensity conversion using a static event camera for both static and dynamic scenes in fluorescence microscopy. Unlike conventional methods that primarily rely on event integration, the proposed Inter-event Interval Microscopy (IEIM) quantifies the time interval between consecutive events at each pixel. With a fixed threshold in the event camera, the time interval can precisely represent the intensity. At the hardware level, the proposed IEIM integrates a pulse light modulation device within a microscope equipped with an event camera, termed Pulse Modulation-based Event-driven Fluorescence Microscopy. Additionally, we have collected IEIMat dataset under various scenes including high dynamic range and high-speed scenarios. Experimental results on the IEIMat dataset demonstrate that the proposed IEIM achieves superior spatial and temporal resolution, as well as a higher dynamic range, with lower bandwidth compared to other methods. The code and the IEIMat dataset will be made publicly available.
Towards Efficient and General-Purpose Few-Shot Misclassification Detection for Vision-Language Models
Mar 26, 2025Reliable prediction by classifiers is crucial for their deployment in high security and dynamically changing situations. However, modern neural networks often exhibit overconfidence for misclassified predictions, highlighting the need for confidence estimation to detect errors. Despite the achievements obtained by existing methods on small-scale datasets, they all require training from scratch and there are no efficient and effective misclassification detection (MisD) methods, hindering practical application towards large-scale and ever-changing datasets. In this paper, we pave the way to exploit vision language model (VLM) leveraging text information to establish an efficient and general-purpose misclassification detection framework. By harnessing the power of VLM, we construct FSMisD, a Few-Shot prompt learning framework for MisD to refrain from training from scratch and therefore improve tuning efficiency. To enhance misclassification detection ability, we use adaptive pseudo sample generation and a novel negative loss to mitigate the issue of overconfidence by pushing category prompts away from pseudo features. We conduct comprehensive experiments with prompt learning methods and validate the generalization ability across various datasets with domain shift. Significant and consistent improvement demonstrates the effectiveness, efficiency and generalizability of our approach.
Enhancing Outlier Knowledge for Few-Shot Out-of-Distribution Detection with Extensible Local Prompts
Sep 07, 2024



Out-of-Distribution (OOD) detection, aiming to distinguish outliers from known categories, has gained prominence in practical scenarios. Recently, the advent of vision-language models (VLM) has heightened interest in enhancing OOD detection for VLM through few-shot tuning. However, existing methods mainly focus on optimizing global prompts, ignoring refined utilization of local information with regard to outliers. Motivated by this, we freeze global prompts and introduce a novel coarse-to-fine tuning paradigm to emphasize regional enhancement with local prompts. Our method comprises two integral components: global prompt guided negative augmentation and local prompt enhanced regional regularization. The former utilizes frozen, coarse global prompts as guiding cues to incorporate negative augmentation, thereby leveraging local outlier knowledge. The latter employs trainable local prompts and a regional regularization to capture local information effectively, aiding in outlier identification. We also propose regional-related metric to empower the enrichment of OOD detection. Moreover, since our approach explores enhancing local prompts only, it can be seamlessly integrated with trained global prompts during inference to boost the performance. Comprehensive experiments demonstrate the effectiveness and potential of our method. Notably, our method reduces average FPR95 by 5.17% against state-of-the-art method in 4-shot tuning on challenging ImageNet-1k dataset, even outperforming 16-shot results of previous methods.
Solve paint color effect prediction problem in trajectory optimization of spray painting robot using artificial neural network inspired by the Kubelka Munk model
Sep 06, 2024



Currently, the spray-painting robot trajectory planning technology aiming at spray painting quality mainly applies to single-color spraying. Conventional methods of optimizing the spray gun trajectory based on simulated thickness can only qualitatively reflect the color distribution, and can not simulate the color effect of spray painting at the pixel level. Therefore, it is not possible to accurately control the area covered by the color and the gradation of the edges of the area, and it is also difficult to deal with the situation where multiple colors of paint are sprayed in combination. To solve the above problems, this paper is inspired by the Kubelka-Munk model and combines the 3D machine vision method and artificial neural network to propose a spray painting color effect prediction method. The method is enabled to predict the execution effect of the spray gun trajectory with pixel-level accuracy from the dimension of the surface color of the workpiece after spray painting. On this basis, the method can be used to replace the traditional thickness simulation method to establish the objective function of the spray gun trajectory optimization problem, and thus solve the difficult problem of spray gun trajectory optimization for multi-color paint combination spraying. In this paper, the mathematical model of the spray painting color effect prediction problem is first determined through the analysis of the Kubelka-Munk paint film color rendering model, and at the same time, the spray painting color effect dataset is established with the help of the depth camera and point cloud processing algorithm. After that, the multilayer perceptron model was improved with the help of gating and residual structure and was used for the color prediction task. To verify ...
PASS++: A Dual Bias Reduction Framework for Non-Exemplar Class-Incremental Learning
Jul 19, 2024



Class-incremental learning (CIL) aims to recognize new classes incrementally while maintaining the discriminability of old classes. Most existing CIL methods are exemplar-based, i.e., storing a part of old data for retraining. Without relearning old data, those methods suffer from catastrophic forgetting. In this paper, we figure out two inherent problems in CIL, i.e., representation bias and classifier bias, that cause catastrophic forgetting of old knowledge. To address these two biases, we present a simple and novel dual bias reduction framework that employs self-supervised transformation (SST) in input space and prototype augmentation (protoAug) in deep feature space. On the one hand, SST alleviates the representation bias by learning generic and diverse representations that can transfer across different tasks. On the other hand, protoAug overcomes the classifier bias by explicitly or implicitly augmenting prototypes of old classes in the deep feature space, which poses tighter constraints to maintain previously learned decision boundaries. We further propose hardness-aware prototype augmentation and multi-view ensemble strategies, leading to significant improvements. The proposed framework can be easily integrated with pre-trained models. Without storing any samples of old classes, our method can perform comparably with state-of-the-art exemplar-based approaches which store plenty of old data. We hope to draw the attention of researchers back to non-exemplar CIL by rethinking the necessity of storing old samples in CIL.
Open-world Machine Learning: A Review and New Outlooks
Mar 15, 2024Machine learning has achieved remarkable success in many applications. However, existing studies are largely based on the closed-world assumption, which assumes that the environment is stationary, and the model is fixed once deployed. In many real-world applications, this fundamental and rather naive assumption may not hold because an open environment is complex, dynamic, and full of unknowns. In such cases, rejecting unknowns, discovering novelties, and then incrementally learning them, could enable models to be safe and evolve continually as biological systems do. This paper provides a holistic view of open-world machine learning by investigating unknown rejection, novel class discovery, and class-incremental learning in a unified paradigm. The challenges, principles, and limitations of current methodologies are discussed in detail. Finally, we discuss several potential directions for future research. This paper aims to provide a comprehensive introduction to the emerging open-world machine learning paradigm, to help researchers build more powerful AI systems in their respective fields, and to promote the development of artificial general intelligence.
Revisiting Confidence Estimation: Towards Reliable Failure Prediction
Mar 05, 2024Reliable confidence estimation is a challenging yet fundamental requirement in many risk-sensitive applications. However, modern deep neural networks are often overconfident for their incorrect predictions, i.e., misclassified samples from known classes, and out-of-distribution (OOD) samples from unknown classes. In recent years, many confidence calibration and OOD detection methods have been developed. In this paper, we find a general, widely existing but actually-neglected phenomenon that most confidence estimation methods are harmful for detecting misclassification errors. We investigate this problem and reveal that popular calibration and OOD detection methods often lead to worse confidence separation between correctly classified and misclassified examples, making it difficult to decide whether to trust a prediction or not. Finally, we propose to enlarge the confidence gap by finding flat minima, which yields state-of-the-art failure prediction performance under various settings including balanced, long-tailed, and covariate-shift classification scenarios. Our study not only provides a strong baseline for reliable confidence estimation but also acts as a bridge between understanding calibration, OOD detection, and failure prediction. The code is available at \url{https://github.com/Impression2805/FMFP}.
Unified Classification and Rejection: A One-versus-All Framework
Nov 22, 2023Classifying patterns of known classes and rejecting ambiguous and novel (also called as out-of-distribution (OOD)) inputs are involved in open world pattern recognition. Deep neural network models usually excel in closed-set classification while performing poorly in rejecting OOD. To tackle this problem, numerous methods have been designed to perform open set recognition (OSR) or OOD rejection/detection tasks. Previous methods mostly take post-training score transformation or hybrid models to ensure low scores on OOD inputs while separating known classes. In this paper, we attempt to build a unified framework for building open set classifiers for both classification and OOD rejection. We formulate the open set recognition of $ K $-known-class as a $ (K + 1) $-class classification problem with model trained on known-class samples only. By decomposing the $ K $-class problem into $ K $ one-versus-all (OVA) binary classification tasks and binding some parameters, we show that combining the scores of OVA classifiers can give $ (K + 1) $-class posterior probabilities, which enables classification and OOD rejection in a unified framework. To maintain the closed-set classification accuracy of the OVA trained classifier, we propose a hybrid training strategy combining OVA loss and multi-class cross-entropy loss. We implement the OVA framework and hybrid training strategy on the recently proposed convolutional prototype network. Experiments on popular OSR and OOD detection datasets demonstrate that the proposed framework, using a single multi-class classifier, yields competitive performance in closed-set classification, OOD detection, and misclassification detection.