 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDE-Agent: A toolchain-augmented multi-agent framework for PDE solving
Dec 22, 2025



Solving Partial Differential Equations (PDEs) is a cornerstone of engineering and scientific research. Traditional methods for PDE solving are cumbersome, relying on manual setup and domain expertise. While Physics-Informed Neural Network (PINNs) introduced end-to-end neural network-based solutions, and frameworks like DeepXDE further enhanced automation, these approaches still depend on expert knowledge and lack full autonomy. In this work, we frame PDE solving as tool invocation via LLM-driven agents and introduce PDE-Agent, the first toolchain-augmented multi-agent collaboration framework, inheriting the reasoning capacity of LLMs and the controllability of external tools and enabling automated PDE solving from natural language descriptions. PDE-Agent leverages the strengths of multi-agent and multi-tool collaboration through two key innovations: (1) A Prog-Act framework with graph memory for multi-agent collaboration, which enables effective dynamic planning and error correction via dual-loop mechanisms (localized fixes and global revisions). (2) A Resource-Pool integrated with a tool-parameter separation mechanism for multi-tool collaboration. This centralizes the management of runtime artifacts and resolves inter-tool dependency gaps in existing frameworks. To validate and evaluate this new paradigm for PDE solving , we develop PDE-Bench, a multi-type PDE Benchmark for agent-based tool collaborative solving, and propose multi-level metrics for assessing tool coordination. Evaluations verify that PDE-Agent exhibits superior applicability and performance in complex multi-step, cross-step dependent tasks. This new paradigm of toolchain-augmented multi-agent PDE solving will further advance future developments in automated scientific computing. Our source code and dataset will be made publicly available.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
LLaVA-c: Continual Improved Visual Instruction Tuning
Jun 10, 2025Multimodal models like LLaVA-1.5 achieve state-of-the-art visual understanding through visual instruction tuning on multitask datasets, enabling strong instruction-following and multimodal performance. However, multitask learning faces challenges such as task balancing, requiring careful adjustment of data proportions, and expansion costs, where new tasks risk catastrophic forgetting and need costly retraining. Continual learning provides a promising alternative to acquiring new knowledge incrementally while preserving existing capabilities. However, current methods prioritize task-specific performance, neglecting base model degradation from overfitting to specific instructions, which undermines general capabilities. In this work, we propose a simple but effective method with two modifications on LLaVA-1.5: spectral-aware consolidation for improved task balance and unsupervised inquiry regularization to prevent base model degradation. We evaluate both general and task-specific performance across continual pretraining and fine-tuning. Experiments demonstrate that LLaVA-c consistently enhances standard benchmark performance and preserves general capabilities. For the first time, we show that task-by-task continual learning can achieve results that match or surpass multitask joint learning. The code will be publicly released.
Air Quality Prediction with A Meteorology-Guided Modality-Decoupled Spatio-Temporal Network
Apr 14, 2025Air quality prediction plays a crucial role in public health and environmental protection. Accurate air quality prediction is a complex multivariate spatiotemporal problem, that involves interactions across temporal patterns, pollutant correlations, spatial station dependencies, and particularly meteorological influences that govern pollutant dispersion and chemical transformations. Existing works underestimate the critical role of atmospheric conditions in air quality prediction and neglect comprehensive meteorological data utilization, thereby impairing the modeling of dynamic interdependencies between air quality and meteorological data. To overcome this, we propose MDSTNet, an encoder-decoder framework that explicitly models air quality observations and atmospheric conditions as distinct modalities, integrating multi-pressure-level meteorological data and weather forecasts to capture atmosphere-pollution dependencies for prediction. Meantime, we construct ChinaAirNet, the first nationwide dataset combining air quality records with multi-pressure-level meteorological observations. Experimental results on ChinaAirNet demonstrate MDSTNet's superiority, substantially reducing 48-hour prediction errors by 17.54\% compared to the state-of-the-art model. The source code and dataset will be available on github.
Multimodal Agricultural Agent Architecture (MA3): A New Paradigm for Intelligent Agricultural Decision-Making
Apr 07, 2025



As a strategic pillar industry for human survival and development, modern agriculture faces dual challenges: optimizing production efficiency and achieving sustainable development. Against the backdrop of intensified climate change leading to frequent extreme weather events, the uncertainty risks in agricultural production systems are increasing exponentially. To address these challenges, this study proposes an innovative \textbf{M}ultimodal \textbf{A}gricultural \textbf{A}gent \textbf{A}rchitecture (\textbf{MA3}), which leverages cross-modal information fusion and task collaboration mechanisms to achieve intelligent agricultural decision-making. This study constructs a multimodal agricultural agent dataset encompassing five major tasks: classification, detection, Visual Question Answering (VQA), tool selection, and agent evaluation. We propose a unified backbone for sugarcane disease classification and detection tools, as well as a sugarcane disease expert model. By integrating an innovative tool selection module, we develop a multimodal agricultural agent capable of effectively performing tasks in classification, detection, and VQA. Furthermore, we introduce a multi-dimensional quantitative evaluation framework and conduct a comprehensive assessment of the entire architecture over our evaluation dataset, thereby verifying the practicality and robustness of MA3 in agricultural scenarios. This study provides new insights and methodologies for the development of agricultural agents, holding significant theoretical and practical implications. Our source code and dataset will be made publicly available upon acceptance.
DocSAM: Unified Document Image Segmentation via Query Decomposition and Heterogeneous Mixed Learning
Apr 05, 2025Document image segmentation is crucial for document analysis and recognition but remains challenging due to the diversity of document formats and segmentation tasks. Existing methods often address these tasks separately, resulting in limited generalization and resource wastage. This paper introduces DocSAM, a transformer-based unified framework designed for various document image segmentation tasks, such as document layout analysis, multi-granularity text segmentation, and table structure recognition, by modelling these tasks as a combination of instance and semantic segmentation. Specifically, DocSAM employs Sentence-BERT to map category names from each dataset into semantic queries that match the dimensionality of instance queries. These two sets of queries interact through an attention mechanism and are cross-attended with image features to predict instance and semantic segmentation masks. Instance categories are predicted by computing the dot product between instance and semantic queries, followed by softmax normalization of scores. Consequently, DocSAM can be jointly trained on heterogeneous datasets, enhancing robustness and generalization while reducing computational and storage resources. Comprehensive evaluations show that DocSAM surpasses existing methods in accuracy, efficiency, and adaptability, highlighting its potential for advancing document image understanding and segmentation across various applications. Codes are available at https://github.com/xhli-git/DocSAM.
A Context-Driven Training-Free Network for Lightweight Scene Text Segmentation and Recognition
Mar 19, 2025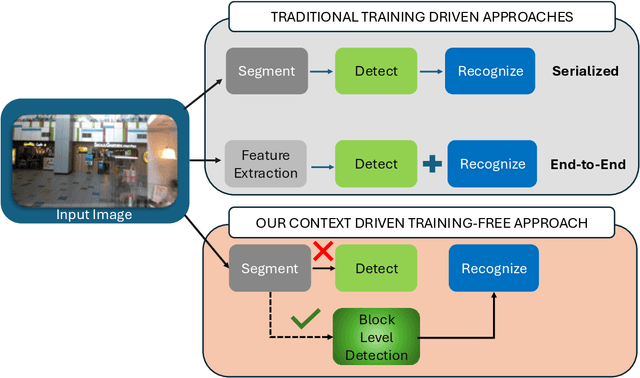

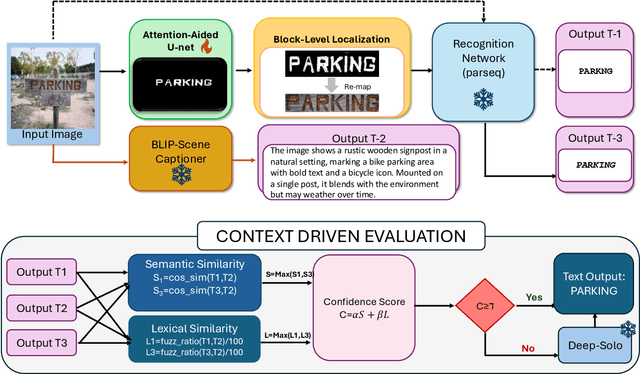

Modern scene text recognition systems often depend on large end-to-end architectures that require extensive training and are prohibitively expensive for real-time scenarios. In such cases, the deployment of heavy models becomes impractical due to constraints on memory, computational resources, and latency. To address these challenges, we propose a novel, training-free plug-and-play framework that leverages the strengths of pre-trained text recognizers while minimizing redundant computations. Our approach uses context-based understanding and introduces an attention-based segmentation stage, which refines candidate text regions at the pixel level, improving downstream recognition. Instead of performing traditional text detection that follows a block-level comparison between feature map and source image and harnesses contextual information using pretrained captioners, allowing the framework to generate word predictions directly from scene context.Candidate texts are semantically and lexically evaluated to get a final score. Predictions that meet or exceed a pre-defined confidence threshold bypass the heavier process of end-to-end text STR profiling, ensuring faster inference and cutting down on unnecessary computations. Experiments on public benchmarks demonstrate that our paradigm achieves performance on par with state-of-the-art systems, yet requires substantially fewer resources.
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Mar 17, 2025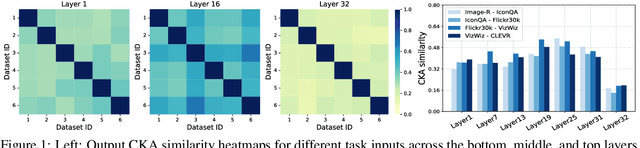
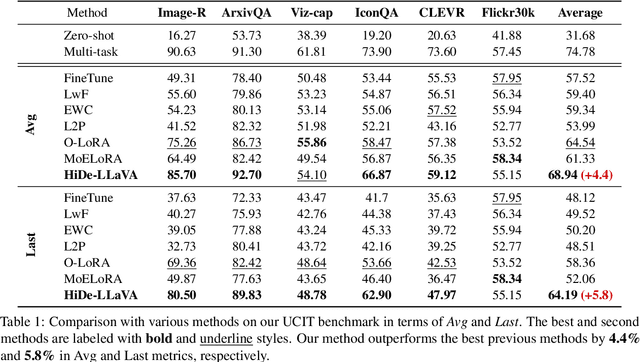
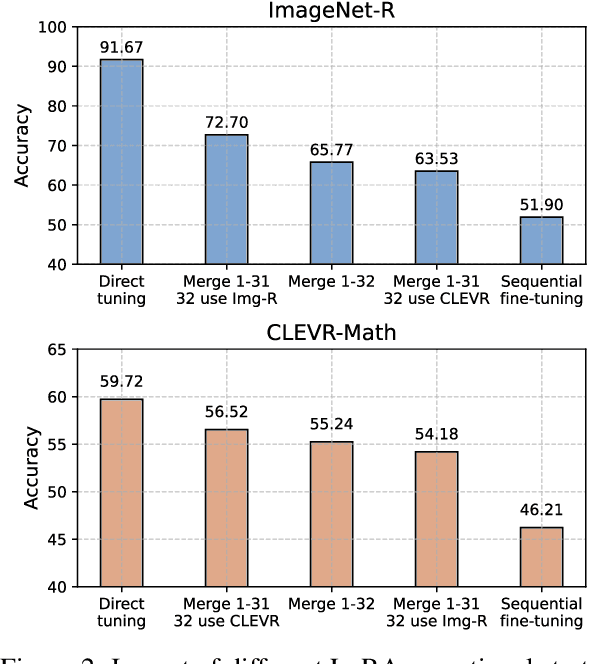
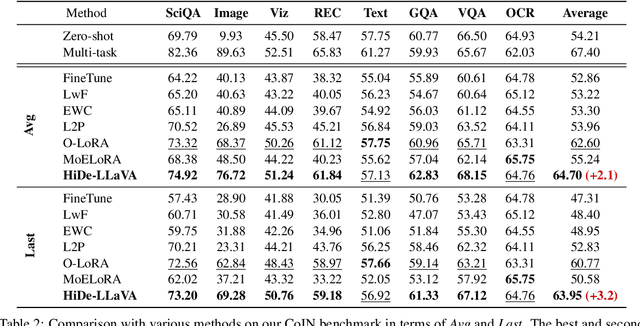
Instruction tuning is widely used to improve a pre-trained Multimodal Large Language Model (MLLM) by training it on curated task-specific datasets, enabling better comprehension of human instructions. However, it is infeasible to collect all possible instruction datasets simultaneously in real-world scenarios. Thus, enabling MLLM with continual instruction tuning is essential for maintaining their adaptability. However, existing methods often trade off memory efficiency for performance gains, significantly compromising overall efficiency. In this paper, we propose a task-specific expansion and task-general fusion framework based on the variations in Centered Kernel Alignment (CKA) similarity across different model layers when trained on diverse datasets. Furthermore, we analyze the information leakage present in the existing benchmark and propose a new and more challenging benchmark to rationally evaluate the performance of different methods. Comprehensive experiments showcase a significant performance improvement of our method compared to existing state-of-the-art methods. Our code will be public available.
Federated Continual Instruction Tuning
Mar 17, 2025A vast amount of instruction tuning data is crucial for the impressive performance of Large Multimodal Models (LMMs), but the associated computational costs and data collection demands during supervised fine-tuning make it impractical for most researchers. Federated learning (FL) has the potential to leverage all distributed data and training resources to reduce the overhead of joint training. However, most existing methods assume a fixed number of tasks, while in real-world scenarios, clients continuously encounter new knowledge and often struggle to retain old tasks due to memory constraints. In this work, we introduce the Federated Continual Instruction Tuning (FCIT) benchmark to model this real-world challenge. Our benchmark includes two realistic scenarios, encompassing four different settings and twelve carefully curated instruction tuning datasets. To address the challenges posed by FCIT, we propose dynamic knowledge organization to effectively integrate updates from different tasks during training and subspace selective activation to allocate task-specific output during inference. Extensive experimental results demonstrate that our proposed method significantly enhances model performance across varying levels of data heterogeneity and catastrophic forgetting. Our source code and dataset will be made publicly available.
From System 1 to System 2: A Survey of Reasoning Large Language Models
Feb 25, 2025Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.