 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Cross-Dataset Object Detection Generalization under Domain Specificity
Jan 14, 2026Object detectors often perform well in-distribution, yet degrade sharply on a different benchmark. We study cross-dataset object detection (CD-OD) through a lens of setting specificity. We group benchmarks into setting-agnostic datasets with diverse everyday scenes and setting-specific datasets tied to a narrow environment, and evaluate a standard detector family across all train--test pairs. This reveals a clear structure in CD-OD: transfer within the same setting type is relatively stable, while transfer across setting types drops substantially and is often asymmetric. The most severe breakdowns occur when transferring from specific sources to agnostic targets, and persist after open-label alignment, indicating that domain shift dominates in the hardest regimes. To disentangle domain shift from label mismatch, we compare closed-label transfer with an open-label protocol that maps predicted classes to the nearest target label using CLIP similarity. Open-label evaluation yields consistent but bounded gains, and many corrected cases correspond to semantic near-misses supported by the image evidence. Overall, we provide a principled characterization of CD-OD under setting specificity and practical guidance for evaluating detectors under distribution shift. Code will be released at \href{[https://github.com/Ritabrata04/cdod-icpr.git}{https://github.com/Ritabrata04/cdod-icpr}.
Mask & Match: Learning to Recognize Handwritten Math with Self-Supervised Attention
Aug 08, 2025Recognizing handwritten mathematical expressions (HMER) is a challenging task due to the inherent two-dimensional structure, varying symbol scales, and complex spatial relationships among symbols. In this paper, we present a self-supervised learning (SSL) framework for HMER that eliminates the need for expensive labeled data. Our approach begins by pretraining an image encoder using a combination of global and local contrastive loss, enabling the model to learn both holistic and fine-grained representations. A key contribution of this work is a novel self-supervised attention network, which is trained using a progressive spatial masking strategy. This attention mechanism is designed to learn semantically meaningful focus regions, such as operators, exponents, and nested mathematical notation, without requiring any supervision. The progressive masking curriculum encourages the network to become increasingly robust to missing or occluded visual information, ultimately improving structural understanding. Our complete pipeline consists of (1) self-supervised pretraining of the encoder, (2) self-supervised attention learning, and (3) supervised fine-tuning with a transformer decoder to generate LATEX sequences. Extensive experiments on CROHME benchmarks demonstrate that our method outperforms existing SSL and fully supervised baselines, validating the effectiveness of our progressive attention mechanism in enhancing HMER performance. Our codebase can be found here.
A Context-Driven Training-Free Network for Lightweight Scene Text Segmentation and Recognition
Mar 19, 2025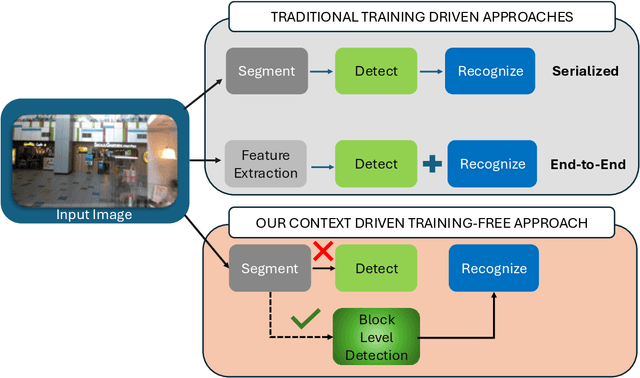

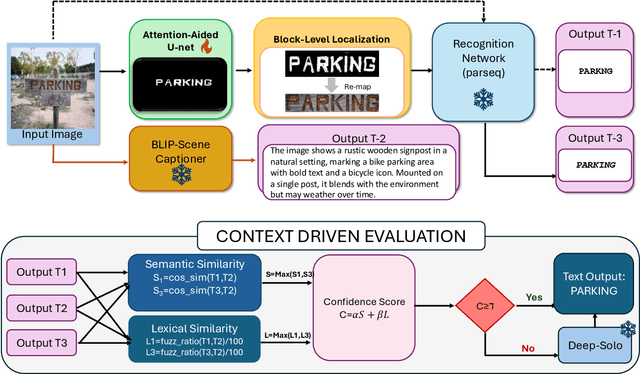

Modern scene text recognition systems often depend on large end-to-end architectures that require extensive training and are prohibitively expensive for real-time scenarios. In such cases, the deployment of heavy models becomes impractical due to constraints on memory, computational resources, and latency. To address these challenges, we propose a novel, training-free plug-and-play framework that leverages the strengths of pre-trained text recognizers while minimizing redundant computations. Our approach uses context-based understanding and introduces an attention-based segmentation stage, which refines candidate text regions at the pixel level, improving downstream recognition. Instead of performing traditional text detection that follows a block-level comparison between feature map and source image and harnesses contextual information using pretrained captioners, allowing the framework to generate word predictions directly from scene context.Candidate texts are semantically and lexically evaluated to get a final score. Predictions that meet or exceed a pre-defined confidence threshold bypass the heavier process of end-to-end text STR profiling, ensuring faster inference and cutting down on unnecessary computations. Experiments on public benchmarks demonstrate that our paradigm achieves performance on par with state-of-the-art systems, yet requires substantially fewer resources.
TruthLens:A Training-Free Paradigm for DeepFake Detection
Mar 19, 2025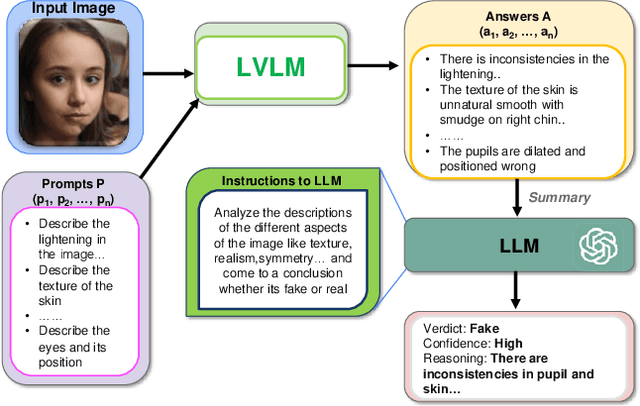
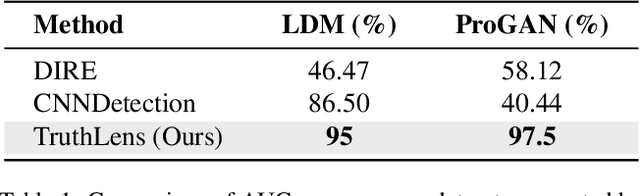

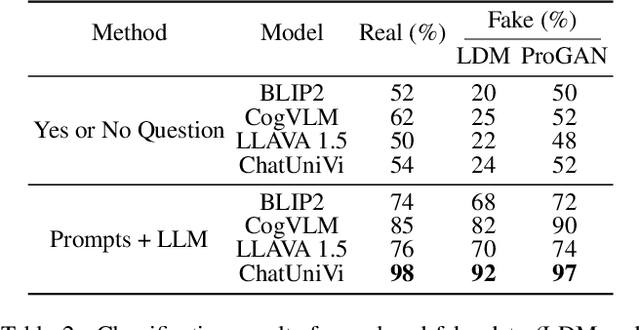
The proliferation of synthetic images generated by advanced AI models poses significant challenges in identifying and understanding manipulated visual content. Current fake image detection methods predominantly rely on binary classification models that focus on accuracy while often neglecting interpretability, leaving users without clear insights into why an image is deemed real or fake. To bridge this gap, we introduce TruthLens, a novel training-free framework that reimagines deepfake detection as a visual question-answering (VQA) task. TruthLens utilizes state-of-the-art large vision-language models (LVLMs) to observe and describe visual artifacts and combines this with the reasoning capabilities of large language models (LLMs) like GPT-4 to analyze and aggregate evidence into informed decisions. By adopting a multimodal approach, TruthLens seamlessly integrates visual and semantic reasoning to not only classify images as real or fake but also provide interpretable explanations for its decisions. This transparency enhances trust and provides valuable insights into the artifacts that signal synthetic content. Extensive evaluations demonstrate that TruthLens outperforms conventional methods, achieving high accuracy on challenging datasets while maintaining a strong emphasis on explainability. By reframing deepfake detection as a reasoning-driven process, TruthLens establishes a new paradigm in combating synthetic media, combining cutting-edge performance with interpretability to address the growing threats of visual disinformation.
On the effective transfer of knowledge from English to Hindi Wikipedia
Dec 07, 2024Although Wikipedia is the largest multilingual encyclopedia, it remains inherently incomplete. There is a significant disparity in the quality of content between high-resource languages (HRLs, e.g., English) and low-resource languages (LRLs, e.g., Hindi), with many LRL articles lacking adequate information. To bridge these content gaps, we propose a lightweight framework to enhance knowledge equity between English and Hindi. In case the English Wikipedia page is not up-to-date, our framework extracts relevant information from external resources readily available (such as English books) and adapts it to align with Wikipedia's distinctive style, including its \textit{neutral point of view} (NPOV) policy, using in-context learning capabilities of large language models. The adapted content is then machine-translated into Hindi for integration into the corresponding Wikipedia articles. On the other hand, if the English version is comprehensive and up-to-date, the framework directly transfers knowledge from English to Hindi. Our framework effectively generates new content for Hindi Wikipedia sections, enhancing Hindi Wikipedia articles respectively by 65% and 62% according to automatic and human judgment-based evaluations.