 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context-Driven Training-Free Network for Lightweight Scene Text Segmentation and Recognition
Paper and Code
Mar 19, 2025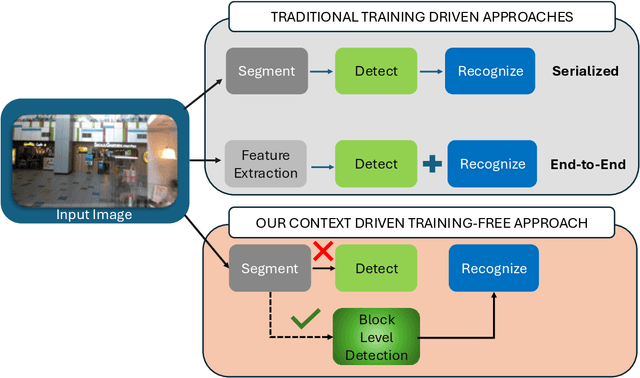

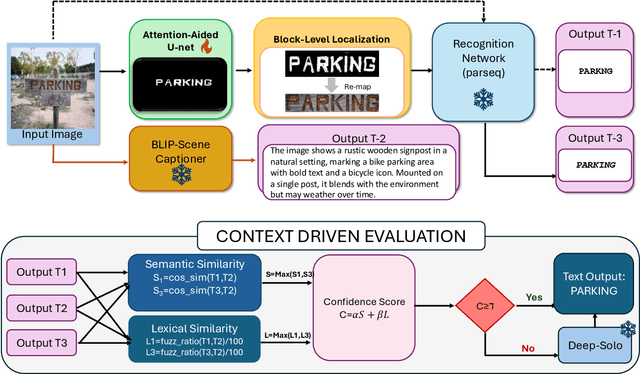

Modern scene text recognition systems often depend on large end-to-end architectures that require extensive training and are prohibitively expensive for real-time scenarios. In such cases, the deployment of heavy models becomes impractical due to constraints on memory, computational resources, and latency. To address these challenges, we propose a novel, training-free plug-and-play framework that leverages the strengths of pre-trained text recognizers while minimizing redundant computations. Our approach uses context-based understanding and introduces an attention-based segmentation stage, which refines candidate text regions at the pixel level, improving downstream recognition. Instead of performing traditional text detection that follows a block-level comparison between feature map and source image and harnesses contextual information using pretrained captioners, allowing the framework to generate word predictions directly from scene context.Candidate texts are semantically and lexically evaluated to get a final score. Predictions that meet or exceed a pre-defined confidence threshold bypass the heavier process of end-to-end text STR profiling, ensuring faster inference and cutting down on unnecessary computations. Experiments on public benchmarks demonstrate that our paradigm achieves performance on par with state-of-the-art systems, yet requires substantially fewer resources.