 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Reasoning Favors Encoders: On The Limits of Decoder-Only Models
Dec 11, 2025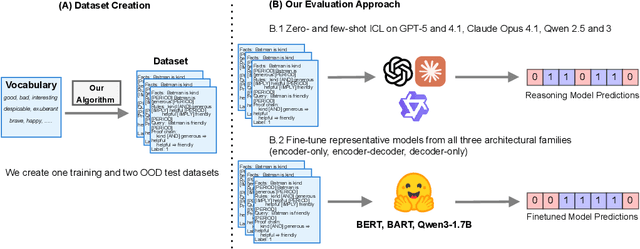



In context learning (ICL) underpins recent advances in large language models (LLMs), although its role and performance in causal reasoning remains unclear. Causal reasoning demands multihop composition and strict conjunctive control, and reliance on spurious lexical relations of the input could provide misleading results. We hypothesize that, due to their ability to project the input into a latent space, encoder and encoder decoder architectures are better suited for said multihop conjunctive reasoning versus decoder only models. To do this, we compare fine-tuned versions of all the aforementioned architectures with zero and few shot ICL in both natural language and non natural language scenarios. We find that ICL alone is insufficient for reliable causal reasoning, often overfocusing on irrelevant input features. In particular, decoder only models are noticeably brittle to distributional shifts, while finetuned encoder and encoder decoder models can generalize more robustly across our tests, including the non natural language split. Both architectures are only matched or surpassed by decoder only architectures at large scales. We conclude by noting that for cost effective, short horizon robust causal reasoning, encoder or encoder decoder architectures with targeted finetuning are preferable.
On the effective transfer of knowledge from English to Hindi Wikipedia
Dec 07, 2024Although Wikipedia is the largest multilingual encyclopedia, it remains inherently incomplete. There is a significant disparity in the quality of content between high-resource languages (HRLs, e.g., English) and low-resource languages (LRLs, e.g., Hindi), with many LRL articles lacking adequate information. To bridge these content gaps, we propose a lightweight framework to enhance knowledge equity between English and Hindi. In case the English Wikipedia page is not up-to-date, our framework extracts relevant information from external resources readily available (such as English books) and adapts it to align with Wikipedia's distinctive style, including its \textit{neutral point of view} (NPOV) policy, using in-context learning capabilities of large language models. The adapted content is then machine-translated into Hindi for integration into the corresponding Wikipedia articles. On the other hand, if the English version is comprehensive and up-to-date, the framework directly transfers knowledge from English to Hindi. Our framework effectively generates new content for Hindi Wikipedia sections, enhancing Hindi Wikipedia articles respectively by 65% and 62% according to automatic and human judgment-based evaluations.
Do the Right Thing, Just Debias! Multi-Category Bias Mitigation Using LLMs
Sep 24, 2024



This paper tackles the challenge of building robust and generalizable bias mitigation models for language. Recognizing the limitations of existing datasets, we introduce ANUBIS, a novel dataset with 1507 carefully curated sentence pairs encompassing nine social bias categories. We evaluate state-of-the-art models like T5, utilizing Supervised Fine-Tuning (SFT), Reinforcement Learning (PPO, DPO), and In-Context Learning (ICL) for effective bias mitigation. Our analysis focuses on multi-class social bias reduction, cross-dataset generalizability, and environmental impact of the trained models. ANUBIS and our findings offer valuable resources for building more equitable AI systems and contribute to the development of responsible and unbiased technologies with broad societal impact.
Size Lowerbounds for Deep Operator Networks
Aug 11, 2023Deep Operator Networks are an increasingly popular paradigm for solving regression in infinite dimensions and hence solve families of PDEs in one shot. In this work, we aim to establish a first-of-its-kind data-dependent lowerbound on the size of DeepONets required for them to be able to reduce empirical error on noisy data. In particular, we show that for low training errors to be obtained on $n$ data points it is necessary that the common output dimension of the branch and the trunk net be scaling as $\Omega \left ( {\sqrt{n}} \right )$. This inspires our experiments with DeepONets solving the advection-diffusion-reaction PDE, where we demonstrate the possibility that at a fixed model size, to leverage increase in this common output dimension and get monotonic lowering of training error, the size of the training data might necessarily need to scale quadratically with it.