 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGal: A First Look at PPO-based Legal AI for Judgment Prediction and Summarization in India
Dec 19, 2025This paper presents an early exploration of reinforcement learning methodologies for legal AI in the Indian context. We introduce Reinforcement Learning-based Legal Reasoning (ReGal), a framework that integrates Multi-Task Instruction Tuning with Reinforcement Learning from AI Feedback (RLAIF) using Proximal Policy Optimization (PPO). Our approach is evaluated across two critical legal tasks: (i) Court Judgment Prediction and Explanation (CJPE), and (ii) Legal Document Summarization. Although the framework underperforms on standard evaluation metrics compared to supervised and proprietary models, it provides valuable insights into the challenges of applying RL to legal texts. These challenges include reward model alignment, legal language complexity, and domain-specific adaptation. Through empirical and qualitative analysis, we demonstrate how RL can be repurposed for high-stakes, long-document tasks in law. Our findings establish a foundation for future work on optimizing legal reasoning pipelines using reinforcement learning, with broader implications for building interpretable and adaptive legal AI systems.
AdversariaL attacK sAfety aLIgnment(ALKALI): Safeguarding LLMs through GRACE: Geometric Representation-Aware Contrastive Enhancement- Introducing Adversarial Vulnerability Quality Index (AVQI)
Jun 11, 2025
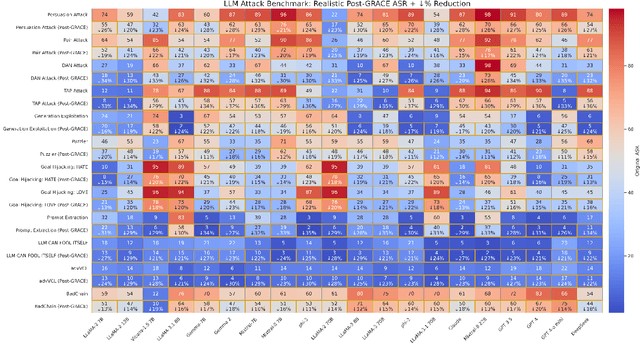
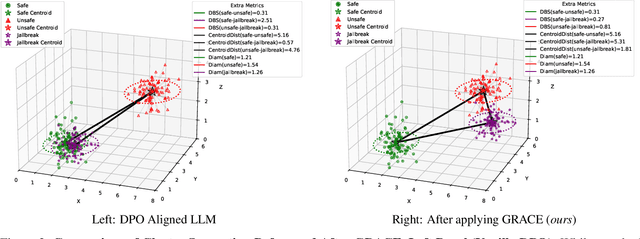

Adversarial threats against LLMs are escalating faster than current defenses can adapt. We expose a critical geometric blind spot in alignment: adversarial prompts exploit latent camouflage, embedding perilously close to the safe representation manifold while encoding unsafe intent thereby evading surface level defenses like Direct Preference Optimization (DPO), which remain blind to the latent geometry. We introduce ALKALI, the first rigorously curated adversarial benchmark and the most comprehensive to date spanning 9,000 prompts across three macro categories, six subtypes, and fifteen attack families. Evaluation of 21 leading LLMs reveals alarmingly high Attack Success Rates (ASRs) across both open and closed source models, exposing an underlying vulnerability we term latent camouflage, a structural blind spot where adversarial completions mimic the latent geometry of safe ones. To mitigate this vulnerability, we introduce GRACE - Geometric Representation Aware Contrastive Enhancement, an alignment framework coupling preference learning with latent space regularization. GRACE enforces two constraints: latent separation between safe and adversarial completions, and adversarial cohesion among unsafe and jailbreak behaviors. These operate over layerwise pooled embeddings guided by a learned attention profile, reshaping internal geometry without modifying the base model, and achieve up to 39% ASR reduction. Moreover, we introduce AVQI, a geometry aware metric that quantifies latent alignment failure via cluster separation and compactness. AVQI reveals when unsafe completions mimic the geometry of safe ones, offering a principled lens into how models internally encode safety. We make the code publicly available at https://anonymous.4open.science/r/alkali-B416/README.md.
SELF-PERCEPT: Introspection Improves Large Language Models' Detection of Multi-Person Mental Manipulation in Conversations
May 27, 2025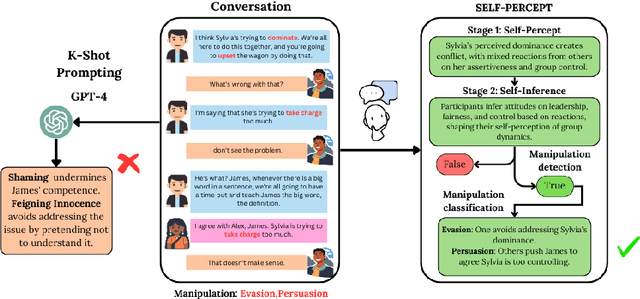
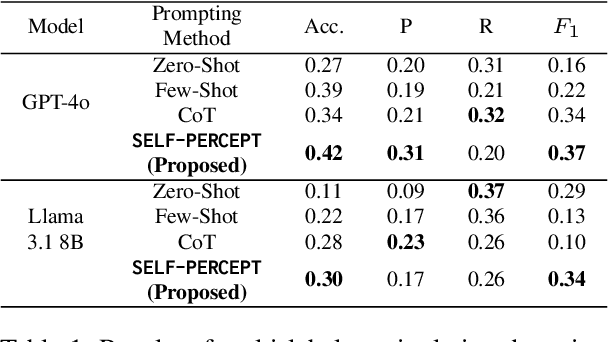
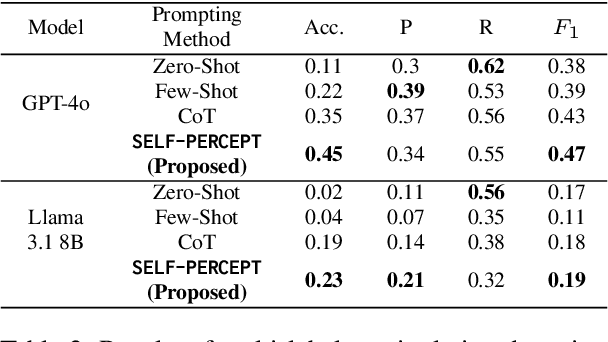
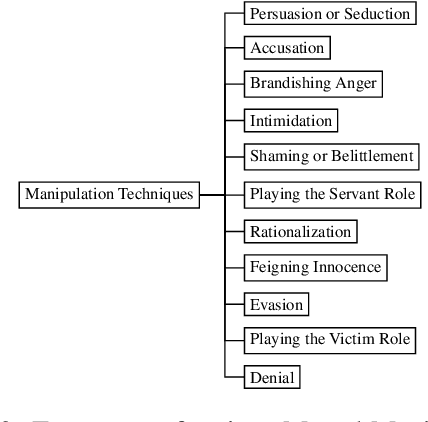
Mental manipulation is a subtle yet pervasive form of abuse in interpersonal communication, making its detection critical for safeguarding potential victims. However, due to manipulation's nuanced and context-specific nature, identifying manipulative language in complex, multi-turn, and multi-person conversations remains a significant challenge for large language models (LLMs). To address this gap, we introduce the MultiManip dataset, comprising 220 multi-turn, multi-person dialogues balanced between manipulative and non-manipulative interactions, all drawn from reality shows that mimic real-world scenarios. For manipulative interactions, it includes 11 distinct manipulations depicting real-life scenarios. We conduct extensive evaluations of state-of-the-art LLMs, such as GPT-4o and Llama-3.1-8B, employing various prompting strategies. Despite their capabilities, these models often struggle to detect manipulation effectively. To overcome this limitation, we propose SELF-PERCEPT, a novel, two-stage prompting framework inspired by Self-Perception Theory, demonstrating strong performance in detecting multi-person, multi-turn mental manipulation. Our code and data are publicly available at https://github.com/danushkhanna/self-percept .
DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference Optimization
Jan 08, 2025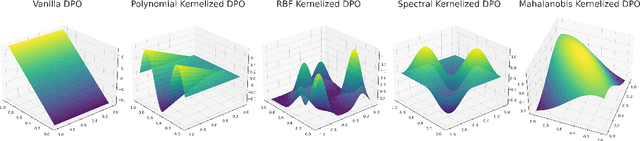


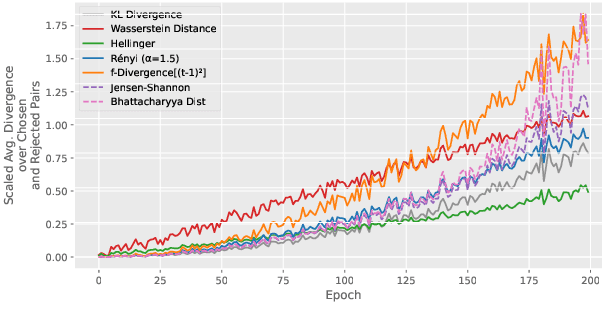
The rapid rise of large language models (LLMs) has unlocked many applications but also underscores the challenge of aligning them with diverse values and preferences. Direct Preference Optimization (DPO) is central to alignment but constrained by fixed divergences and limited feature transformations. We propose DPO-Kernels, which integrates kernel methods to address these issues through four key contributions: (i) Kernelized Representations with polynomial, RBF, Mahalanobis, and spectral kernels for richer transformations, plus a hybrid loss combining embedding-based and probability-based objectives; (ii) Divergence Alternatives (Jensen-Shannon, Hellinger, Renyi, Bhattacharyya, Wasserstein, and f-divergences) for greater stability; (iii) Data-Driven Selection metrics that automatically choose the best kernel-divergence pair; and (iv) a Hierarchical Mixture of Kernels for both local precision and global modeling. Evaluations on 12 datasets demonstrate state-of-the-art performance in factuality, safety, reasoning, and instruction following. Grounded in Heavy-Tailed Self-Regularization, DPO-Kernels maintains robust generalization for LLMs, offering a comprehensive resource for further alignment research.
Do the Right Thing, Just Debias! Multi-Category Bias Mitigation Using LLMs
Sep 24, 2024



This paper tackles the challenge of building robust and generalizable bias mitigation models for language. Recognizing the limitations of existing datasets, we introduce ANUBIS, a novel dataset with 1507 carefully curated sentence pairs encompassing nine social bias categories. We evaluate state-of-the-art models like T5, utilizing Supervised Fine-Tuning (SFT), Reinforcement Learning (PPO, DPO), and In-Context Learning (ICL) for effective bias mitigation. Our analysis focuses on multi-class social bias reduction, cross-dataset generalizability, and environmental impact of the trained models. ANUBIS and our findings offer valuable resources for building more equitable AI systems and contribute to the development of responsible and unbiased technologies with broad societal impact.
Legal Judgment Reimagined: PredEx and the Rise of Intelligent AI Interpretation in Indian Courts
Jun 06, 2024In the era of Large Language Models (LLMs), predicting judicial outcomes poses significant challenges due to the complexity of legal proceedings and the scarcity of expert-annotated datasets. Addressing this, we introduce \textbf{Pred}iction with \textbf{Ex}planation (\texttt{PredEx}), the largest expert-annotated dataset for legal judgment prediction and explanation in the Indian context, featuring over 15,000 annotations. This groundbreaking corpus significantly enhances the training and evaluation of AI models in legal analysis, with innovations including the application of instruction tuning to LLMs. This method has markedly improved the predictive accuracy and explanatory depth of these models for legal judgments. We employed various transformer-based models, tailored for both general and Indian legal contexts. Through rigorous lexical, semantic, and expert assessments, our models effectively leverage \texttt{PredEx} to provide precise predictions and meaningful explanations, establishing it as a valuable benchmark for both the legal profession and the NLP community.