 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMEDI: A Benchmark for Retention and Unlearning Evaluation in Multi-label Clinical Disease Inference
Jun 05, 2026Language models trained for clinical disease inference are trained on patient data, which may include sensitive and private information, and data owners may request the removal of their data from a trained model due to privacy or copyright concerns. However, exactly unlearning patient-specific data is intractable, and retraining with minor data removal is resource-intensive. While there exists several machine unlearning methods that can be used, their utility is generally restricted to non-medical domains. Moreover, the existing benchmarks for evaluating such unlearning methods primarily utilize synthetically curated datasets, which are not truly representative of real-world systems. Hence, the effectiveness of these unlearning methods in the medical domain is largely unclear. To this end, we introduce REMEDI, an extensive benchmark for machine unlearning tailored to multi-label and multiclass clinical disease inference, where label correlations, longitudinal structure, and safety constraints make unlearning particularly challenging. Unlike the existing benchmarks, REMEDI considers: (1) a relevant application domain (medical), (2) comprehensive unlearning setups involving diverse sets of forget instances, (3) challenging unlearning scenarios including multi-label and multi-class classification tasks, and (4) evaluation metrics involving performance both in terms of utility and extent of unlearning achieved. REMEDI is developed using the MIMIC-III clinical database that contains comprehensive clinical data of patients. Experiments with existing unlearning methods indicate that there exists a trade-off between utility and unlearning performance. They are also largely unsuited to multi-label classification tasks. To facilitate reproducibility, we make our benchmark publicly available.
FLNet: Flood-Induced Agriculture Damage Assessment using Super Resolution of Satellite Images
Jan 07, 2026Distributing government relief efforts after a flood is challenging. In India, the crops are widely affected by floods; therefore, making rapid and accurate crop damage assessment is crucial for effective post-disaster agricultural management. Traditional manual surveys are slow and biased, while current satellite-based methods face challenges like cloud cover and low spatial resolution. Therefore, to bridge this gap, this paper introduced FLNet, a novel deep learning based architecture that used super-resolution to enhance the 10 m spatial resolution of Sentinel-2 satellite images into 3 m resolution before classifying damage. We tested our model on the Bihar Flood Impacted Croplands Dataset (BFCD-22), and the results showed an improved critical "Full Damage" F1-score from 0.83 to 0.89, nearly matching the 0.89 score of commercial high-resolution imagery. This work presented a cost-effective and scalable solution, paving the way for a nationwide shift from manual to automated, high-fidelity damage assessment.
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Jun 22, 2024

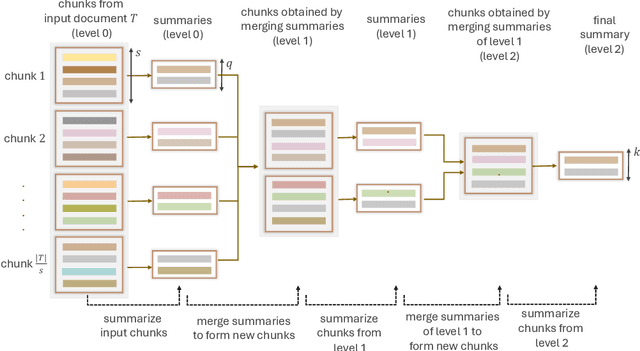

Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. Inherently LLMs produce abstractive summaries, and the task of achieving extractive summaries through LLMs still remains largely unexplored. To bridge this gap, in this work, we propose a novel framework LaMSUM to generate extractive summaries through LLMs for large user-generated text by leveraging voting algorithms. Our evaluation on three popular open-source LLMs (Llama 3, Mixtral and Gemini) reveal that the LaMSUM outperforms state-of-the-art extractive summarization methods. We further attempt to provide the rationale behind the output summary produced by LLMs. Overall, this is one of the early attempts to achieve extractive summarization for large user-generated text by utilizing LLMs, and likely to generate further interest in the community.
Legal Judgment Reimagined: PredEx and the Rise of Intelligent AI Interpretation in Indian Courts
Jun 06, 2024In the era of Large Language Models (LLMs), predicting judicial outcomes poses significant challenges due to the complexity of legal proceedings and the scarcity of expert-annotated datasets. Addressing this, we introduce \textbf{Pred}iction with \textbf{Ex}planation (\texttt{PredEx}), the largest expert-annotated dataset for legal judgment prediction and explanation in the Indian context, featuring over 15,000 annotations. This groundbreaking corpus significantly enhances the training and evaluation of AI models in legal analysis, with innovations including the application of instruction tuning to LLMs. This method has markedly improved the predictive accuracy and explanatory depth of these models for legal judgments. We employed various transformer-based models, tailored for both general and Indian legal contexts. Through rigorous lexical, semantic, and expert assessments, our models effectively leverage \texttt{PredEx} to provide precise predictions and meaningful explanations, establishing it as a valuable benchmark for both the legal profession and the NLP community.
Few-Shot Fairness: Unveiling LLM's Potential for Fairness-Aware Classification
Feb 28, 2024



Employing Large Language Models (LLM) in various downstream applications such as classification is crucial, especially for smaller companies lacking the expertise and resources required for fine-tuning a model. Fairness in LLMs helps ensure inclusivity, equal representation based on factors such as race, gender and promotes responsible AI deployment. As the use of LLMs has become increasingly prevalent, it is essential to assess whether LLMs can generate fair outcomes when subjected to considerations of fairness. In this study, we introduce a framework outlining fairness regulations aligned with various fairness definitions, with each definition being modulated by varying degrees of abstraction. We explore the configuration for in-context learning and the procedure for selecting in-context demonstrations using RAG, while incorporating fairness rules into the process. Experiments conducted with different LLMs indicate that GPT-4 delivers superior results in terms of both accuracy and fairness compared to other models. This work is one of the early attempts to achieve fairness in prediction tasks by utilizing LLMs through in-context learning.
A Unified Framework for Optimization-Based Graph Coarsening
Oct 02, 2022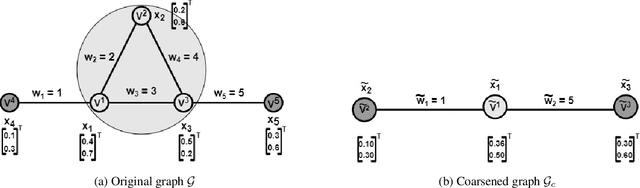
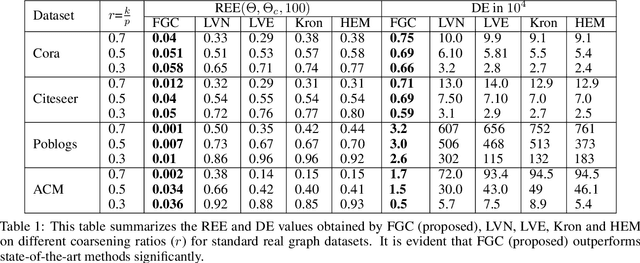
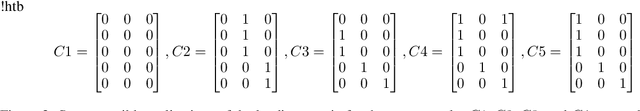
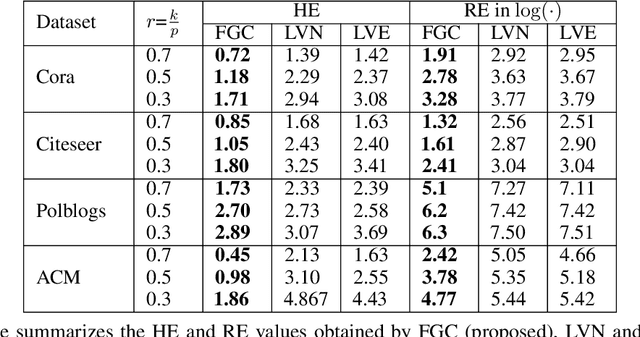
Graph coarsening is a widely used dimensionality reduction technique for approaching large-scale graph machine learning problems. Given a large graph, graph coarsening aims to learn a smaller-tractable graph while preserving the properties of the originally given graph. Graph data consist of node features and graph matrix (e.g., adjacency and Laplacian). The existing graph coarsening methods ignore the node features and rely solely on a graph matrix to simplify graphs. In this paper, we introduce a novel optimization-based framework for graph dimensionality reduction. The proposed framework lies in the unification of graph learning and dimensionality reduction. It takes both the graph matrix and the node features as the input and learns the coarsen graph matrix and the coarsen feature matrix jointly while ensuring desired properties. The proposed optimization formulation is a multi-block non-convex optimization problem, which is solved efficiently by leveraging block majorization-minimization, $\log$ determinant, Dirichlet energy, and regularization frameworks. The proposed algorithms are provably convergent and practically amenable to numerous tasks. It is also established that the learned coarsened graph is $\epsilon\in(0,1)$ similar to the original graph. Extensive experiments elucidate the efficacy of the proposed framework for real-world applications.
Low Cost Autonomous Navigation and Control of a Mechanically Balanced Bicycle with Dual Locomotion Mode
Nov 01, 2016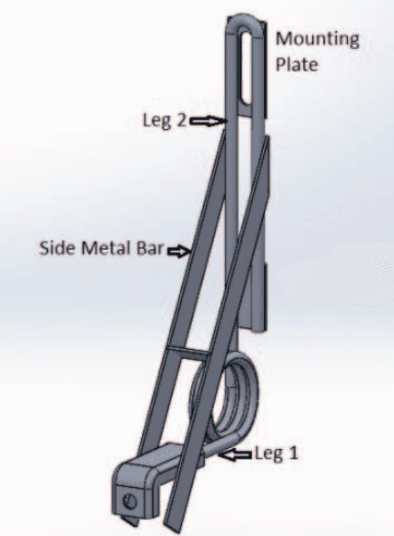
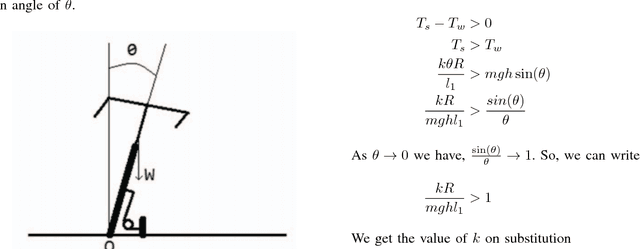
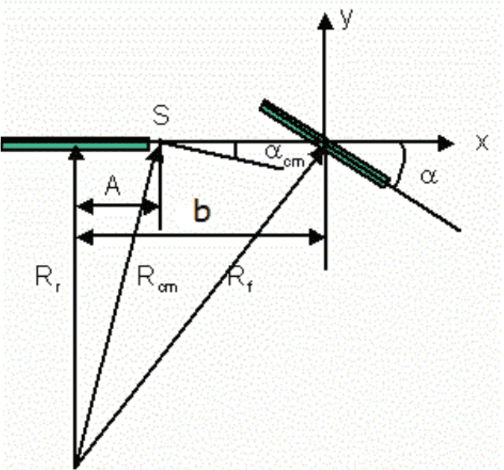
On the lines of the huge and varied efforts in the field of automation with respect to technology development and innovation of vehicles to make them run autonomously, this paper presents an innovation to a bicycle. A normal daily use bicycle was modified at low cost such that it runs autonomously, while maintaining its original form i.e. the manual drive. Hence, a bicycle which could be normally driven by any human and with a press of switch could run autonomously according to the needs of the user has been developed.
* Published in the International Transportation Electrification Conference (ITEC) in 2015 organized by IEEE Industrial Application Society (IAS) and SAE India in Chennai, India