 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaSetu: Cross-Lingual Knowledge Transfer from High-Resource to Extreme Low-Resource Languages
Feb 05, 2026Despite remarkable advances in natural language processing, developing effective systems for low-resource languages remains a formidable challenge, with performances typically lagging far behind high-resource counterparts due to data scarcity and insufficient linguistic resources. Cross-lingual knowledge transfer has emerged as a promising approach to address this challenge by leveraging resources from high-resource languages. In this paper, we investigate methods for transferring linguistic knowledge from high-resource languages to low-resource languages, where the number of labeled training instances is in hundreds. We focus on sentence-level and word-level tasks. We introduce a novel method, GETR (Graph-Enhanced Token Representation) for cross-lingual knowledge transfer along with two adopted baselines (a) augmentation in hidden layers and (b) token embedding transfer through token translation. Experimental results demonstrate that our GNN-based approach significantly outperforms existing multilingual and cross-lingual baseline methods, achieving 13 percentage point improvements on truly low-resource languages (Mizo, Khasi) for POS tagging, and 20 and 27 percentage point improvements in macro-F1 on simulated low-resource languages (Marathi, Bangla, Malayalam) across sentiment classification and NER tasks respectively. We also present a detailed analysis of the transfer mechanisms and identify key factors that contribute to successful knowledge transfer in this linguistic context.
INDIC DIALECT: A Multi Task Benchmark to Evaluate and Translate in Indian Language Dialects
Jan 15, 2026Recent NLP advances focus primarily on standardized languages, leaving most low-resource dialects under-served especially in Indian scenarios. In India, the issue is particularly important: despite Hindi being the third most spoken language globally (over 600 million speakers), its numerous dialects remain underrepresented. The situation is similar for Odia, which has around 45 million speakers. While some datasets exist which contain standard Hindi and Odia languages, their regional dialects have almost no web presence. We introduce INDIC-DIALECT, a human-curated parallel corpus of 13k sentence pairs spanning 11 dialects and 2 languages: Hindi and Odia. Using this corpus, we construct a multi-task benchmark with three tasks: dialect classification, multiple-choice question (MCQ) answering, and machine translation (MT). Our experiments show that LLMs like GPT-4o and Gemini 2.5 perform poorly on the classification task. While fine-tuned transformer based models pretrained on Indian languages substantially improve performance e.g., improving F1 from 19.6\% to 89.8\% on dialect classification. For dialect to language translation, we find that hybrid AI model achieves highest BLEU score of 61.32 compared to the baseline score of 23.36. Interestingly, due to complexity in generating dialect sentences, we observe that for language to dialect translation the ``rule-based followed by AI" approach achieves best BLEU score of 48.44 compared to the baseline score of 27.59. INDIC-DIALECT thus is a new benchmark for dialect-aware Indic NLP, and we plan to release it as open source to support further work on low-resource Indian dialects.
ReGal: A First Look at PPO-based Legal AI for Judgment Prediction and Summarization in India
Dec 19, 2025This paper presents an early exploration of reinforcement learning methodologies for legal AI in the Indian context. We introduce Reinforcement Learning-based Legal Reasoning (ReGal), a framework that integrates Multi-Task Instruction Tuning with Reinforcement Learning from AI Feedback (RLAIF) using Proximal Policy Optimization (PPO). Our approach is evaluated across two critical legal tasks: (i) Court Judgment Prediction and Explanation (CJPE), and (ii) Legal Document Summarization. Although the framework underperforms on standard evaluation metrics compared to supervised and proprietary models, it provides valuable insights into the challenges of applying RL to legal texts. These challenges include reward model alignment, legal language complexity, and domain-specific adaptation. Through empirical and qualitative analysis, we demonstrate how RL can be repurposed for high-stakes, long-document tasks in law. Our findings establish a foundation for future work on optimizing legal reasoning pipelines using reinforcement learning, with broader implications for building interpretable and adaptive legal AI systems.
Seeing Justice Clearly: Handwritten Legal Document Translation with OCR and Vision-Language Models
Dec 19, 2025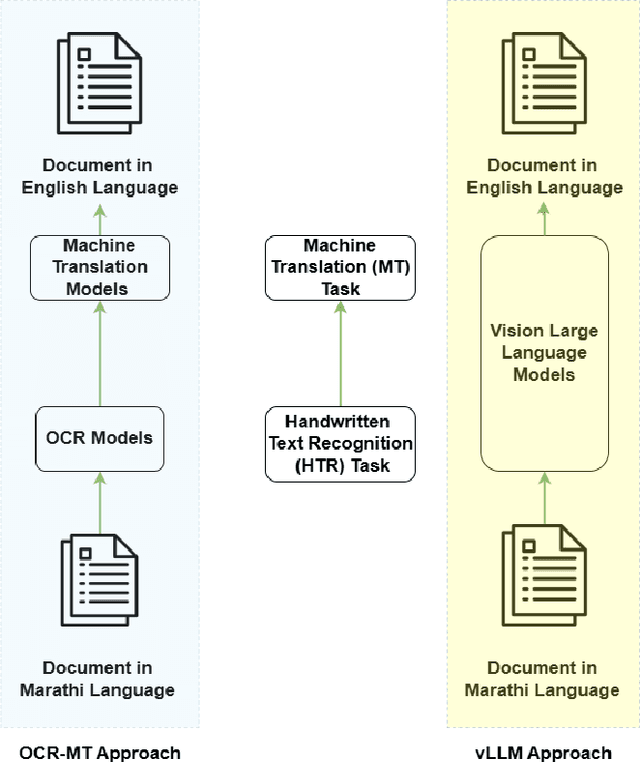
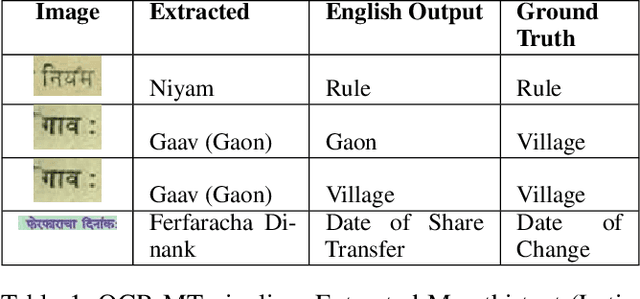
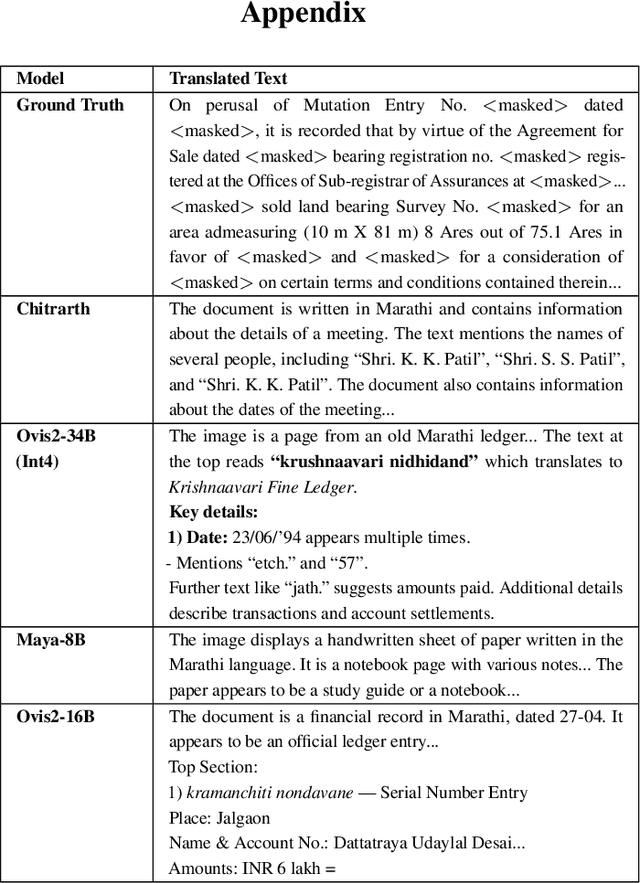

Handwritten text recognition (HTR) and machine translation continue to pose significant challenges, particularly for low-resource languages like Marathi, which lack large digitized corpora and exhibit high variability in handwriting styles. The conventional approach to address this involves a two-stage pipeline: an OCR system extracts text from handwritten images, which is then translated into the target language using a machine translation model. In this work, we explore and compare the performance of traditional OCR-MT pipelines with Vision Large Language Models that aim to unify these stages and directly translate handwritten text images in a single, end-to-end step. Our motivation is grounded in the urgent need for scalable, accurate translation systems to digitize legal records such as FIRs, charge sheets, and witness statements in India's district and high courts. We evaluate both approaches on a curated dataset of handwritten Marathi legal documents, with the goal of enabling efficient legal document processing, even in low-resource environments. Our findings offer actionable insights toward building robust, edge-deployable solutions that enhance access to legal information for non-native speakers and legal professionals alike.
IBPS: Indian Bail Prediction System
Aug 11, 2025Bail decisions are among the most frequently adjudicated matters in Indian courts, yet they remain plagued by subjectivity, delays, and inconsistencies. With over 75% of India's prison population comprising undertrial prisoners, many from socioeconomically disadvantaged backgrounds, the lack of timely and fair bail adjudication exacerbates human rights concerns and contributes to systemic judicial backlog. In this paper, we present the Indian Bail Prediction System (IBPS), an AI-powered framework designed to assist in bail decision-making by predicting outcomes and generating legally sound rationales based solely on factual case attributes and statutory provisions. We curate and release a large-scale dataset of 150,430 High Court bail judgments, enriched with structured annotations such as age, health, criminal history, crime category, custody duration, statutes, and judicial reasoning. We fine-tune a large language model using parameter-efficient techniques and evaluate its performance across multiple configurations, with and without statutory context, and with RAG. Our results demonstrate that models fine-tuned with statutory knowledge significantly outperform baselines, achieving strong accuracy and explanation quality, and generalize well to a test set independently annotated by legal experts. IBPS offers a transparent, scalable, and reproducible solution to support data-driven legal assistance, reduce bail delays, and promote procedural fairness in the Indian judicial system.
NyayaRAG: Realistic Legal Judgment Prediction with RAG under the Indian Common Law System
Aug 01, 2025Legal Judgment Prediction (LJP) has emerged as a key area in AI for law, aiming to automate judicial outcome forecasting and enhance interpretability in legal reasoning. While previous approaches in the Indian context have relied on internal case content such as facts, issues, and reasoning, they often overlook a core element of common law systems, which is reliance on statutory provisions and judicial precedents. In this work, we propose NyayaRAG, a Retrieval-Augmented Generation (RAG) framework that simulates realistic courtroom scenarios by providing models with factual case descriptions, relevant legal statutes, and semantically retrieved prior cases. NyayaRAG evaluates the effectiveness of these combined inputs in predicting court decisions and generating legal explanations using a domain-specific pipeline tailored to the Indian legal system. We assess performance across various input configurations using both standard lexical and semantic metrics as well as LLM-based evaluators such as G-Eval. Our results show that augmenting factual inputs with structured legal knowledge significantly improves both predictive accuracy and explanation quality.
Segment First, Retrieve Better: Realistic Legal Search via Rhetorical Role-Based Queries
Aug 01, 2025Legal precedent retrieval is a cornerstone of the common law system, governed by the principle of stare decisis, which demands consistency in judicial decisions. However, the growing complexity and volume of legal documents challenge traditional retrieval methods. TraceRetriever mirrors real-world legal search by operating with limited case information, extracting only rhetorically significant segments instead of requiring complete documents. Our pipeline integrates BM25, Vector Database, and Cross-Encoder models, combining initial results through Reciprocal Rank Fusion before final re-ranking. Rhetorical annotations are generated using a Hierarchical BiLSTM CRF classifier trained on Indian judgments. Evaluated on IL-PCR and COLIEE 2025 datasets, TraceRetriever addresses growing document volume challenges while aligning with practical search constraints, reliable and scalable foundation for precedent retrieval enhancing legal research when only partial case knowledge is available.
BanglaByT5: Byte-Level Modelling for Bangla
May 21, 2025Large language models (LLMs) have achieved remarkable success across various natural language processing tasks. However, most LLM models use traditional tokenizers like BPE and SentencePiece, which fail to capture the finer nuances of a morphologically rich language like Bangla (Bengali). In this work, we introduce BanglaByT5, the first byte-level encoder-decoder model explicitly tailored for Bangla. Built upon a small variant of Googles ByT5 architecture, BanglaByT5 is pre-trained on a 14GB curated corpus combining high-quality literary and newspaper articles. Through zeroshot and supervised evaluations across generative and classification tasks, BanglaByT5 demonstrates competitive performance, surpassing several multilingual and larger models. Our findings highlight the efficacy of byte-level modelling for morphologically rich languages and highlight BanglaByT5 potential as a lightweight yet powerful tool for Bangla NLP, particularly in both resource-constrained and scalable environments.
A Case Study of Cross-Lingual Zero-Shot Generalization for Classical Languages in LLMs
May 19, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across diverse tasks and languages. In this study, we focus on natural language understanding in three classical languages -- Sanskrit, Ancient Greek and Latin -- to investigate the factors affecting cross-lingual zero-shot generalization. First, we explore named entity recognition and machine translation into English. While LLMs perform equal to or better than fine-tuned baselines on out-of-domain data, smaller models often struggle, especially with niche or abstract entity types. In addition, we concentrate on Sanskrit by presenting a factoid question-answering (QA) dataset and show that incorporating context via retrieval-augmented generation approach significantly boosts performance. In contrast, we observe pronounced performance drops for smaller LLMs across these QA tasks. These results suggest model scale as an important factor influencing cross-lingual generalization. Assuming that models used such as GPT-4o and Llama-3.1 are not instruction fine-tuned on classical languages, our findings provide insights into how LLMs may generalize on these languages and their consequent utility in classical studies.
TathyaNyaya and FactLegalLlama: Advancing Factual Judgment Prediction and Explanation in the Indian Legal Context
Apr 07, 2025In the landscape of Fact-based Judgment Prediction and Explanation (FJPE), reliance on factual data is essential for developing robust and realistic AI-driven decision-making tools. This paper introduces TathyaNyaya, the largest annotated dataset for FJPE tailored to the Indian legal context, encompassing judgments from the Supreme Court of India and various High Courts. Derived from the Hindi terms "Tathya" (fact) and "Nyaya" (justice), the TathyaNyaya dataset is uniquely designed to focus on factual statements rather than complete legal texts, reflecting real-world judicial processes where factual data drives outcomes. Complementing this dataset, we present FactLegalLlama, an instruction-tuned variant of the LLaMa-3-8B Large Language Model (LLM), optimized for generating high-quality explanations in FJPE tasks. Finetuned on the factual data in TathyaNyaya, FactLegalLlama integrates predictive accuracy with coherent, contextually relevant explanations, addressing the critical need for transparency and interpretability in AI-assisted legal systems. Our methodology combines transformers for binary judgment prediction with FactLegalLlama for explanation generation, creating a robust framework for advancing FJPE in the Indian legal domain. TathyaNyaya not only surpasses existing datasets in scale and diversity but also establishes a benchmark for building explainable AI systems in legal analysis. The findings underscore the importance of factual precision and domain-specific tuning in enhancing predictive performance and interpretability, positioning TathyaNyaya and FactLegalLlama as foundational resources for AI-assisted legal decision-making.