 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaByT5: Byte-Level Modelling for Bangla
May 21, 2025Large language models (LLMs) have achieved remarkable success across various natural language processing tasks. However, most LLM models use traditional tokenizers like BPE and SentencePiece, which fail to capture the finer nuances of a morphologically rich language like Bangla (Bengali). In this work, we introduce BanglaByT5, the first byte-level encoder-decoder model explicitly tailored for Bangla. Built upon a small variant of Googles ByT5 architecture, BanglaByT5 is pre-trained on a 14GB curated corpus combining high-quality literary and newspaper articles. Through zeroshot and supervised evaluations across generative and classification tasks, BanglaByT5 demonstrates competitive performance, surpassing several multilingual and larger models. Our findings highlight the efficacy of byte-level modelling for morphologically rich languages and highlight BanglaByT5 potential as a lightweight yet powerful tool for Bangla NLP, particularly in both resource-constrained and scalable environments.
A Case Study of Cross-Lingual Zero-Shot Generalization for Classical Languages in LLMs
May 19, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across diverse tasks and languages. In this study, we focus on natural language understanding in three classical languages -- Sanskrit, Ancient Greek and Latin -- to investigate the factors affecting cross-lingual zero-shot generalization. First, we explore named entity recognition and machine translation into English. While LLMs perform equal to or better than fine-tuned baselines on out-of-domain data, smaller models often struggle, especially with niche or abstract entity types. In addition, we concentrate on Sanskrit by presenting a factoid question-answering (QA) dataset and show that incorporating context via retrieval-augmented generation approach significantly boosts performance. In contrast, we observe pronounced performance drops for smaller LLMs across these QA tasks. These results suggest model scale as an important factor influencing cross-lingual generalization. Assuming that models used such as GPT-4o and Llama-3.1 are not instruction fine-tuned on classical languages, our findings provide insights into how LLMs may generalize on these languages and their consequent utility in classical studies.
VAIYAKARANA : A Benchmark for Automatic Grammar Correction in Bangla
Jun 20, 2024



Bangla (Bengali) is the fifth most spoken language globally and, yet, the problem of automatic grammar correction in Bangla is still in its nascent stage. This is mostly due to the need for a large corpus of grammatically incorrect sentences, with their corresponding correct counterparts. The present state-of-the-art techniques to curate a corpus for grammatically wrong sentences involve random swapping, insertion and deletion of words. However,these steps may not always generate grammatically wrong sentences in Bangla. In this work, we propose a pragmatic approach to generate grammatically wrong sentences in Bangla. We first categorize the different kinds of errors in Bangla into 5 broad classes and 12 finer classes. We then use these to generate grammatically wrong sentences systematically from a correct sentence. This approach can generate a large number of wrong sentences and can, thus, mitigate the challenge of lacking a large corpus for neural networks. We provide a dataset, Vaiyakarana, consisting of 92,830 grammatically incorrect sentences as well as 18,426 correct sentences. We also collected 619 human-generated sentences from essays written by Bangla native speakers. This helped us to understand errors that are more frequent. We evaluated our corpus against neural models and LLMs and also benchmark it against human evaluators who are native speakers of Bangla. Our analysis shows that native speakers are far more accurate than state-of-the-art models to detect whether the sentence is grammatically correct. Our methodology of generating erroneous sentences can be applied for most other Indian languages as well.
LGR2: Language Guided Reward Relabeling for Accelerating Hierarchical Reinforcement Learning
Jun 09, 2024Developing interactive systems that leverage natural language instructions to solve complex robotic control tasks has been a long-desired goal in the robotics community. Large Language Models (LLMs) have demonstrated exceptional abilities in handling complex tasks, including logical reasoning, in-context learning, and code generation. However, predicting low-level robotic actions using LLMs poses significant challenges. Additionally, the complexity of such tasks usually demands the acquisition of policies to execute diverse subtasks and combine them to attain the ultimate objective. Hierarchical Reinforcement Learning (HRL) is an elegant approach for solving such tasks, which provides the intuitive benefits of temporal abstraction and improved exploration. However, HRL faces the recurring issue of non-stationarity due to unstable lower primitive behaviour. In this work, we propose LGR2, a novel HRL framework that leverages language instructions to generate a stationary reward function for the higher-level policy. Since the language-guided reward is unaffected by the lower primitive behaviour, LGR2 mitigates non-stationarity and is thus an elegant method for leveraging language instructions to solve robotic control tasks. To analyze the efficacy of our approach, we perform empirical analysis and demonstrate that LGR2 effectively alleviates non-stationarity in HRL. Our approach attains success rates exceeding 70$\%$ in challenging, sparse-reward robotic navigation and manipulation environments where the baselines fail to achieve any significant progress. Additionally, we conduct real-world robotic manipulation experiments and demonstrate that CRISP shows impressive generalization in real-world scenarios.
Vacaspati: A Diverse Corpus of Bangla Literature
Jul 11, 2023Bangla (or Bengali) is the fifth most spoken language globally; yet, the state-of-the-art NLP in Bangla is lagging for even simple tasks such as lemmatization, POS tagging, etc. This is partly due to lack of a varied quality corpus. To alleviate this need, we build Vacaspati, a diverse corpus of Bangla literature. The literary works are collected from various websites; only those works that are publicly available without copyright violations or restrictions are collected. We believe that published literature captures the features of a language much better than newspapers, blogs or social media posts which tend to follow only a certain literary pattern and, therefore, miss out on language variety. Our corpus Vacaspati is varied from multiple aspects, including type of composition, topic, author, time, space, etc. It contains more than 11 million sentences and 115 million words. We also built a word embedding model, Vac-FT, using FastText from Vacaspati as well as trained an Electra model, Vac-BERT, using the corpus. Vac-BERT has far fewer parameters and requires only a fraction of resources compared to other state-of-the-art transformer models and yet performs either better or similar on various downstream tasks. On multiple downstream tasks, Vac-FT outperforms other FastText-based models. We also demonstrate the efficacy of Vacaspati as a corpus by showing that similar models built from other corpora are not as effective. The models are available at https://bangla.iitk.ac.in/.
OntoSeer -- A Recommendation System to Improve the Quality of Ontologies
Feb 04, 2022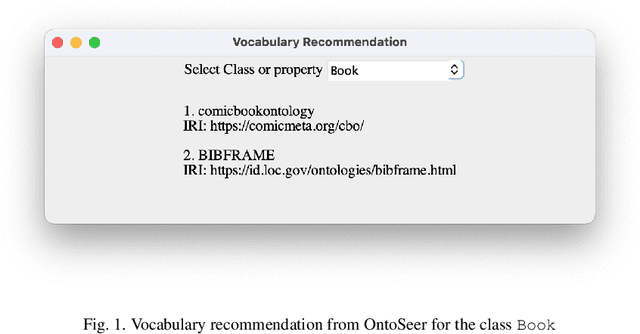

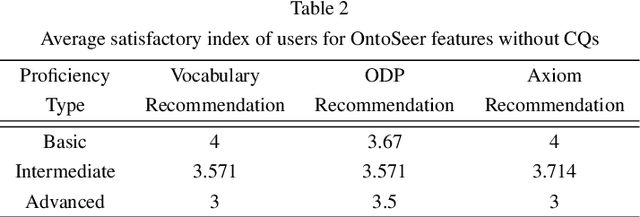
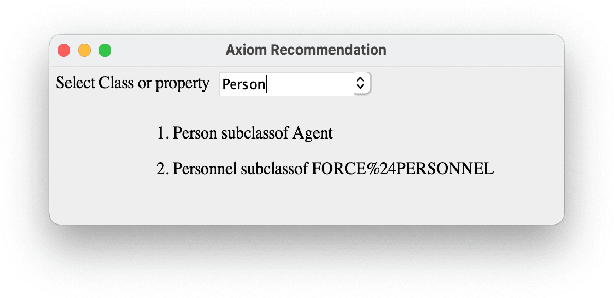
Building an ontology is not only a time-consuming process, but it is also confusing, especially for beginners and the inexperienced. Although ontology developers can take the help of domain experts in building an ontology, they are not readily available in several cases for a variety of reasons. Ontology developers have to grapple with several questions related to the choice of classes, properties, and the axioms that should be included. Apart from this, there are aspects such as modularity and reusability that should be taken care of. From among the thousands of publicly available ontologies and vocabularies in repositories such as Linked Open Vocabularies (LOV) and BioPortal, it is hard to know the terms (classes and properties) that can be reused in the development of an ontology. A similar problem exists in implementing the right set of ontology design patterns (ODPs) from among the several available. Generally, ontology developers make use of their experience in handling these issues, and the inexperienced ones have a hard time. In order to bridge this gap, we propose a tool named OntoSeer, that monitors the ontology development process and provides suggestions in real-time to improve the quality of the ontology under development. It can provide suggestions on the naming conventions to follow, vocabulary to reuse, ODPs to implement, and axioms to be added to the ontology. OntoSeer has been implemented as a Prot\'eg\'e plug-in.