 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaSetu: Cross-Lingual Knowledge Transfer from High-Resource to Extreme Low-Resource Languages
Feb 05, 2026Despite remarkable advances in natural language processing, developing effective systems for low-resource languages remains a formidable challenge, with performances typically lagging far behind high-resource counterparts due to data scarcity and insufficient linguistic resources. Cross-lingual knowledge transfer has emerged as a promising approach to address this challenge by leveraging resources from high-resource languages. In this paper, we investigate methods for transferring linguistic knowledge from high-resource languages to low-resource languages, where the number of labeled training instances is in hundreds. We focus on sentence-level and word-level tasks. We introduce a novel method, GETR (Graph-Enhanced Token Representation) for cross-lingual knowledge transfer along with two adopted baselines (a) augmentation in hidden layers and (b) token embedding transfer through token translation. Experimental results demonstrate that our GNN-based approach significantly outperforms existing multilingual and cross-lingual baseline methods, achieving 13 percentage point improvements on truly low-resource languages (Mizo, Khasi) for POS tagging, and 20 and 27 percentage point improvements in macro-F1 on simulated low-resource languages (Marathi, Bangla, Malayalam) across sentiment classification and NER tasks respectively. We also present a detailed analysis of the transfer mechanisms and identify key factors that contribute to successful knowledge transfer in this linguistic context.
Vacaspati: A Diverse Corpus of Bangla Literature
Jul 11, 2023Bangla (or Bengali) is the fifth most spoken language globally; yet, the state-of-the-art NLP in Bangla is lagging for even simple tasks such as lemmatization, POS tagging, etc. This is partly due to lack of a varied quality corpus. To alleviate this need, we build Vacaspati, a diverse corpus of Bangla literature. The literary works are collected from various websites; only those works that are publicly available without copyright violations or restrictions are collected. We believe that published literature captures the features of a language much better than newspapers, blogs or social media posts which tend to follow only a certain literary pattern and, therefore, miss out on language variety. Our corpus Vacaspati is varied from multiple aspects, including type of composition, topic, author, time, space, etc. It contains more than 11 million sentences and 115 million words. We also built a word embedding model, Vac-FT, using FastText from Vacaspati as well as trained an Electra model, Vac-BERT, using the corpus. Vac-BERT has far fewer parameters and requires only a fraction of resources compared to other state-of-the-art transformer models and yet performs either better or similar on various downstream tasks. On multiple downstream tasks, Vac-FT outperforms other FastText-based models. We also demonstrate the efficacy of Vacaspati as a corpus by showing that similar models built from other corpora are not as effective. The models are available at https://bangla.iitk.ac.in/.
DCoM: A Deep Column Mapper for Semantic Data Type Detection
Jun 24, 2021
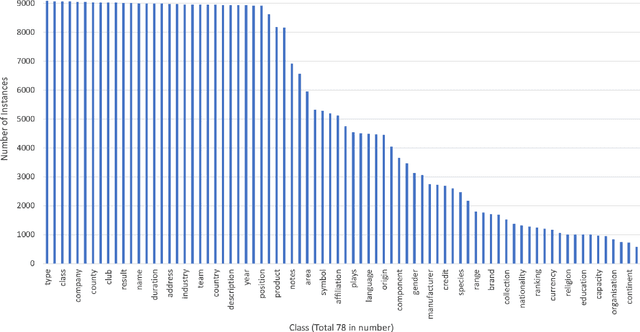

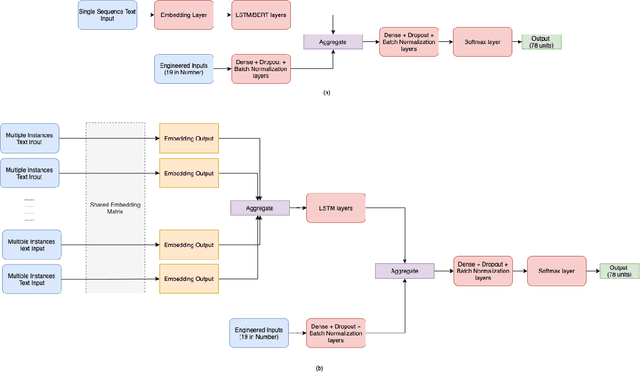
Detection of semantic data types is a very crucial task in data science for automated data cleaning, schema matching, data discovery, semantic data type normalization and sensitive data identification. Existing methods include regular expression-based or dictionary lookup-based methods that are not robust to dirty as well unseen data and are limited to a very less number of semantic data types to predict. Existing Machine Learning methods extract large number of engineered features from data and build logistic regression, random forest or feedforward neural network for this purpose. In this paper, we introduce DCoM, a collection of multi-input NLP-based deep neural networks to detect semantic data types where instead of extracting large number of features from the data, we feed the raw values of columns (or instances) to the model as texts. We train DCoM on 686,765 data columns extracted from VizNet corpus with 78 different semantic data types. DCoM outperforms other contemporary results with a quite significant margin on the same dataset.
Multicollinearity Correction and Combined Feature Effect in Shapley Values
Nov 03, 2020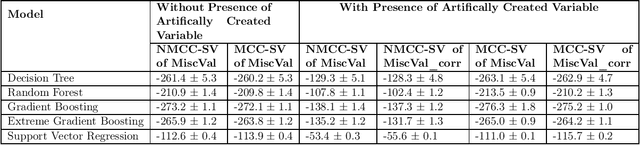
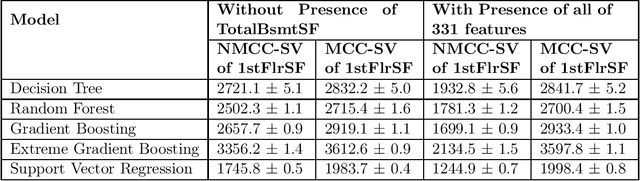
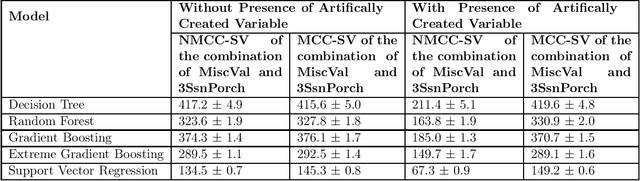
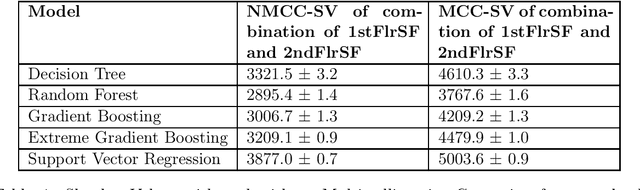
Model interpretability is one of the most intriguing problems in most of the Machine Learning models, particularly for those that are mathematically sophisticated. Computing Shapley Values are arguably the best approach so far to find the importance of each feature in a model, at the row level. In other words, Shapley values represent the importance of a feature for a particular row, especially for Classification or Regression problems. One of the biggest limitations of Shapley vales is that, Shapley value calculations assume all the features are uncorrelated (independent of each other), this assumption is often incorrect. To address this problem, we present a unified framework to calculate Shapley values with correlated features. To be more specific, we do an adjustment (Matrix formulation) of the features while calculating Independent Shapley values for the rows. Moreover, we have given a Mathematical proof against the said adjustments. With these adjustments, Shapley values (Importance) for the features become independent of the correlations existing between them. We have also enhanced this adjustment concept for more than features. As the Shapley values are additive, to calculate combined effect of two features, we just have to add their individual Shapley values. This is again not right if one or more of the features (used in the combination) are correlated with the other features (not in the combination). We have addressed this problem also by extending the correlation adjustment for one feature to multiple features in the said combination for which Shapley values are determined. Our implementation of this method proves that our method is computationally efficient also, compared to original Shapley method.
An Interpretable Deep Learning System for Automatically Scoring Request for Proposals
Aug 05, 2020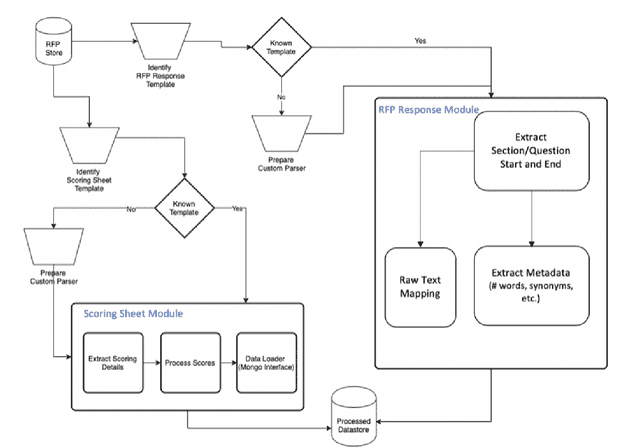



The Managed Care system within Medicaid (US Healthcare) uses Request For Proposals (RFP) to award contracts for various healthcare and related services. RFP responses are very detailed documents (hundreds of pages) submitted by competing organisations to win contracts. Subject matter expertise and domain knowledge play an important role in preparing RFP responses along with analysis of historical submissions. Automated analysis of these responses through Natural Language Processing (NLP) systems can reduce time and effort needed to explore historical responses, and assisting in writing better responses. Our work draws parallels between scoring RFPs and essay scoring models, while highlighting new challenges and the need for interpretability. Typical scoring models focus on word level impacts to grade essays and other short write-ups. We propose a novel Bi-LSTM based regression model, and provide deeper insight into phrases which latently impact scoring of responses. We contend the merits of our proposed methodology using extensive quantitative experiments. We also qualitatively asses the impact of important phrases using human evaluators. Finally, we introduce a novel problem statement that can be used to further improve the state of the art in NLP based automatic scoring systems.
A Simple and Interpretable Predictive Model for Healthcare
Jul 27, 2020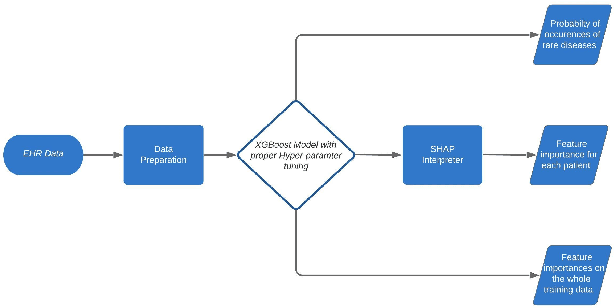
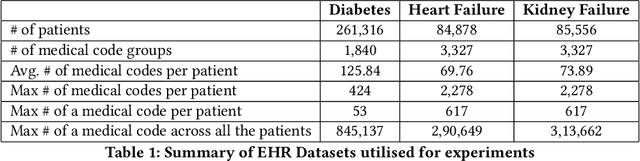
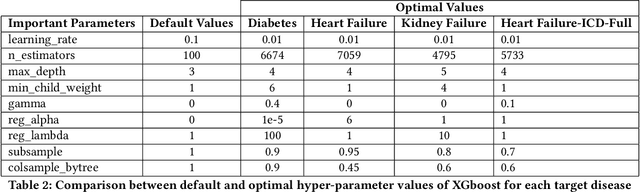
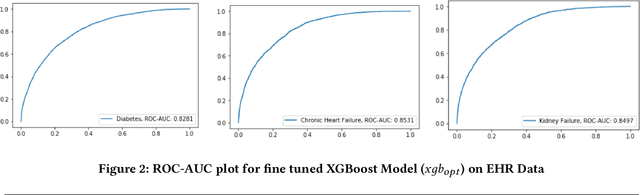
Deep Learning based models are currently dominating most state-of-the-art solutions for disease prediction. Existing works employ RNNs along with multiple levels of attention mechanisms to provide interpretability. These deep learning models, with trainable parameters running into millions, require huge amounts of compute and data to train and deploy. These requirements are sometimes so huge that they render usage of such models as unfeasible. We address these challenges by developing a simpler yet interpretable non-deep learning based model for application to EHR data. We model and showcase our work's results on the task of predicting first occurrence of a diagnosis, often overlooked in existing works. We push the capabilities of a tree based model and come up with a strong baseline for more sophisticated models. Its performance shows an improvement over deep learning based solutions (both, with and without the first-occurrence constraint) all the while maintaining interpretability.
Exclusion and Inclusion -- A model agnostic approach to feature importance in DNNs
Jul 13, 2020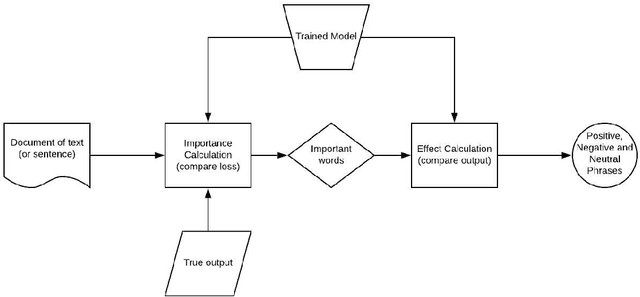

Deep Neural Networks in NLP have enabled systems to learn complex non-linear relationships. One of the major bottlenecks towards being able to use DNNs for real world applications is their characterization as black boxes. To solve this problem, we introduce a model agnostic algorithm which calculates phrase-wise importance of input features. We contend that our method is generalizable to a diverse set of tasks, by carrying out experiments for both Regression and Classification. We also observe that our approach is robust to outliers, implying that it only captures the essential aspects of the input.
Rotation Invariant Deep CBIR
Jun 21, 2020



Introduction of Convolutional Neural Networks has improved results on almost every image-based problem and Content-Based Image Retrieval is not an exception. But the CNN features, being rotation invariant, creates problems to build a rotation-invariant CBIR system. Though rotation-invariant features can be hand-engineered, the retrieval accuracy is very low because by hand engineering only low-level features can be created, unlike deep learning models that create high-level features along with low-level features. This paper shows a novel method to build a rotational invariant CBIR system by introducing a deep learning orientation angle detection model along with the CBIR feature extraction model. This paper also highlights that this rotation invariant deep CBIR can retrieve images from a large dataset in real-time.
An Improved Relevance Feedback in CBIR
Jun 21, 2020


Relevance Feedback in Content-Based Image Retrieval is a method where the feedback of the performance is being used to improve itself. Prior works use feature re-weighting and classification techniques as the Relevance Feedback methods. This paper shows a novel addition to the prior methods to further improve the retrieval accuracy. In addition to all of these, the paper also shows a novel idea to even improve the 0-th iteration retrieval accuracy from the information of Relevance Feedback.
Deep Image Orientation Angle Detection
Jun 21, 2020



Estimating and rectifying the orientation angle of any image is a pretty challenging task. Initial work used the hand engineering features for this purpose, where after the invention of deep learning using convolution-based neural network showed significant improvement in this problem. However, this paper shows that the combination of CNN and a custom loss function specially designed for angles lead to a state-of-the-art results. This includes the estimation of the orientation angle of any image or document at any degree (0 to 360 degree),