 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation
Oct 08, 2025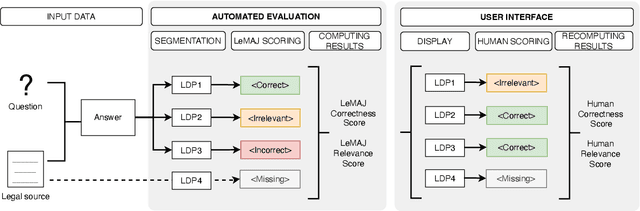

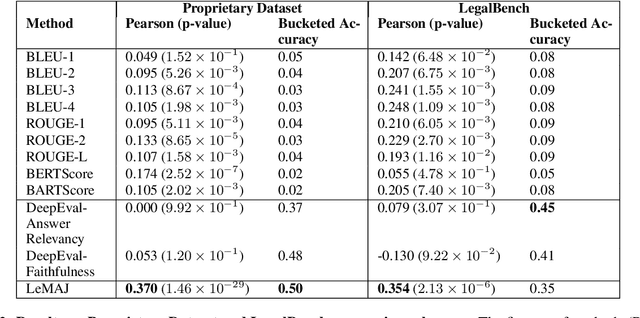
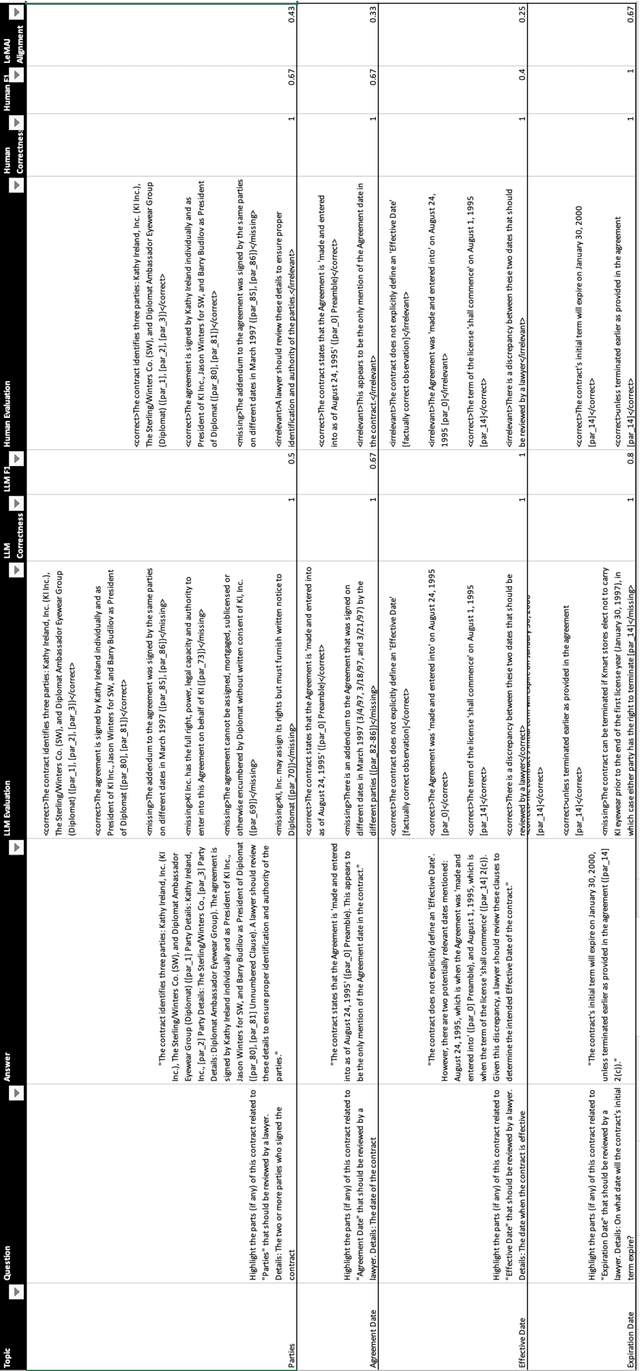
Evaluating large language model (LLM) outputs in the legal domain presents unique challenges due to the complex and nuanced nature of legal analysis. Current evaluation approaches either depend on reference data, which is costly to produce, or use standardized assessment methods, both of which have significant limitations for legal applications. Although LLM-as-a-Judge has emerged as a promising evaluation technique, its reliability and effectiveness in legal contexts depend heavily on evaluation processes unique to the legal industry and how trustworthy the evaluation appears to the human legal expert. This is where existing evaluation methods currently fail and exhibit considerable variability. This paper aims to close the gap: a) we break down lengthy responses into 'Legal Data Points' (LDPs), self-contained units of information, and introduce a novel, reference-free evaluation methodology that reflects how lawyers evaluate legal answers; b) we demonstrate that our method outperforms a variety of baselines on both our proprietary dataset and an open-source dataset (LegalBench); c) we show how our method correlates more closely with human expert evaluations and helps improve inter-annotator agreement; and finally d) we open source our Legal Data Points for a subset of LegalBench used in our experiments, allowing the research community to replicate our results and advance research in this vital area of LLM evaluation on legal question-answering.
Breaking Down the Defenses: A Comparative Survey of Attacks on Large Language Models
Mar 03, 2024

Large Language Models (LLMs) have become a cornerstone in the field of Natural Language Processing (NLP), offering transformative capabilities in understanding and generating human-like text. However, with their rising prominence, the security and vulnerability aspects of these models have garnered significant attention. This paper presents a comprehensive survey of the various forms of attacks targeting LLMs, discussing the nature and mechanisms of these attacks, their potential impacts, and current defense strategies. We delve into topics such as adversarial attacks that aim to manipulate model outputs, data poisoning that affects model training, and privacy concerns related to training data exploitation. The paper also explores the effectiveness of different attack methodologies, the resilience of LLMs against these attacks, and the implications for model integrity and user trust. By examining the latest research, we provide insights into the current landscape of LLM vulnerabilities and defense mechanisms. Our objective is to offer a nuanced understanding of LLM attacks, foster awareness within the AI community, and inspire robust solutions to mitigate these risks in future developments.
From Prejudice to Parity: A New Approach to Debiasing Large Language Model Word Embeddings
Feb 20, 2024



Embeddings play a pivotal role in the efficacy of Large Language Models. They are the bedrock on which these models grasp contextual relationships and foster a more nuanced understanding of language and consequently perform remarkably on a plethora of complex tasks that require a fundamental understanding of human language. Given that these embeddings themselves often reflect or exhibit bias, it stands to reason that these models may also inadvertently learn this bias. In this work, we build on the seminal previous work and propose DeepSoftDebias, an algorithm that uses a neural network to perform 'soft debiasing'. We exhaustively evaluate this algorithm across a variety of SOTA datasets, accuracy metrics, and challenging NLP tasks. We find that DeepSoftDebias outperforms the current state-of-the-art methods at reducing bias across gender, race, and religion.
Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
Sep 21, 2023

Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.
Generative Data Augmentation using LLMs improves Distributional Robustness in Question Answering
Sep 03, 2023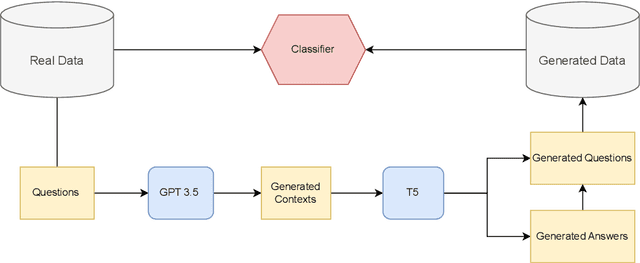
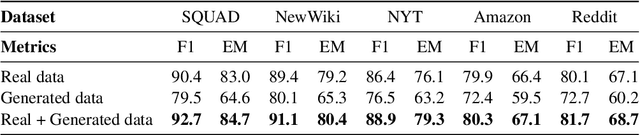

Robustness in Natural Language Processing continues to be a pertinent issue, where state of the art models under-perform under naturally shifted distributions. In the context of Question Answering, work on domain adaptation methods continues to be a growing body of research. However, very little attention has been given to the notion of domain generalization under natural distribution shifts, where the target domain is unknown. With drastic improvements in the quality and access to generative models, we answer the question: How do generated datasets influence the performance of QA models under natural distribution shifts? We perform experiments on 4 different datasets under varying amounts of distribution shift, and analyze how "in-the-wild" generation can help achieve domain generalization. We take a two-step generation approach, generating both contexts and QA pairs to augment existing datasets. Through our experiments, we demonstrate how augmenting reading comprehension datasets with generated data leads to better robustness towards natural distribution shifts.
An Interpretable Deep Learning System for Automatically Scoring Request for Proposals
Aug 05, 2020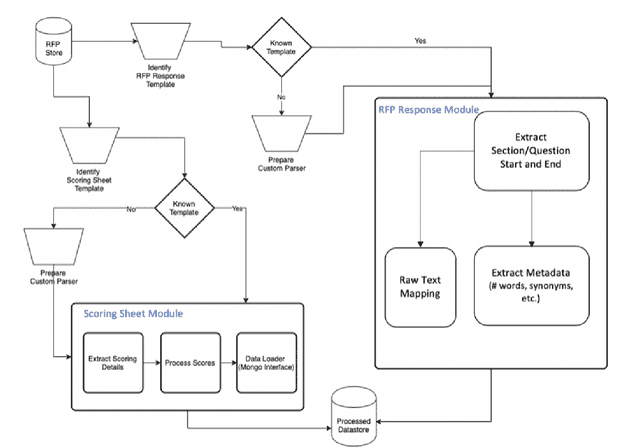



The Managed Care system within Medicaid (US Healthcare) uses Request For Proposals (RFP) to award contracts for various healthcare and related services. RFP responses are very detailed documents (hundreds of pages) submitted by competing organisations to win contracts. Subject matter expertise and domain knowledge play an important role in preparing RFP responses along with analysis of historical submissions. Automated analysis of these responses through Natural Language Processing (NLP) systems can reduce time and effort needed to explore historical responses, and assisting in writing better responses. Our work draws parallels between scoring RFPs and essay scoring models, while highlighting new challenges and the need for interpretability. Typical scoring models focus on word level impacts to grade essays and other short write-ups. We propose a novel Bi-LSTM based regression model, and provide deeper insight into phrases which latently impact scoring of responses. We contend the merits of our proposed methodology using extensive quantitative experiments. We also qualitatively asses the impact of important phrases using human evaluators. Finally, we introduce a novel problem statement that can be used to further improve the state of the art in NLP based automatic scoring systems.
Exclusion and Inclusion -- A model agnostic approach to feature importance in DNNs
Jul 13, 2020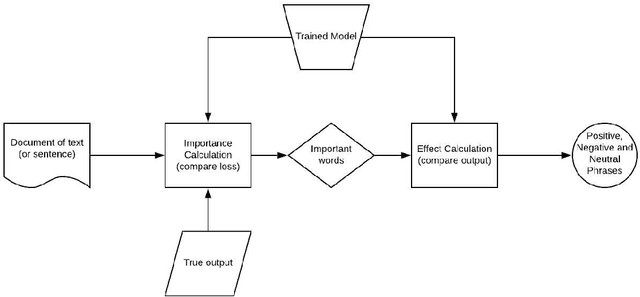

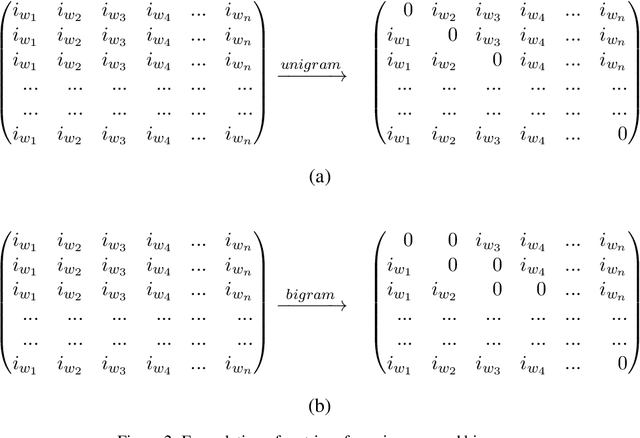
Deep Neural Networks in NLP have enabled systems to learn complex non-linear relationships. One of the major bottlenecks towards being able to use DNNs for real world applications is their characterization as black boxes. To solve this problem, we introduce a model agnostic algorithm which calculates phrase-wise importance of input features. We contend that our method is generalizable to a diverse set of tasks, by carrying out experiments for both Regression and Classification. We also observe that our approach is robust to outliers, implying that it only captures the essential aspects of the input.