 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEaster2.0: Improving convolutional models for handwritten text recognition
May 30, 2022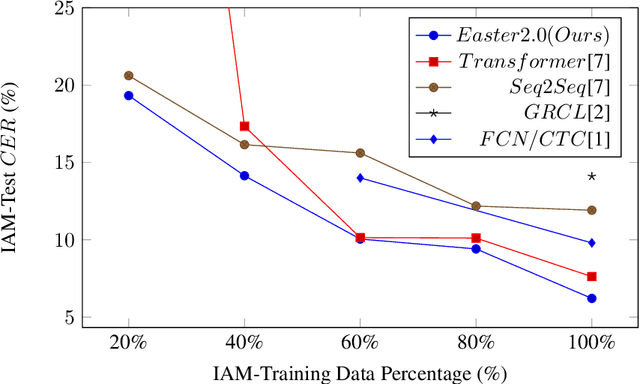

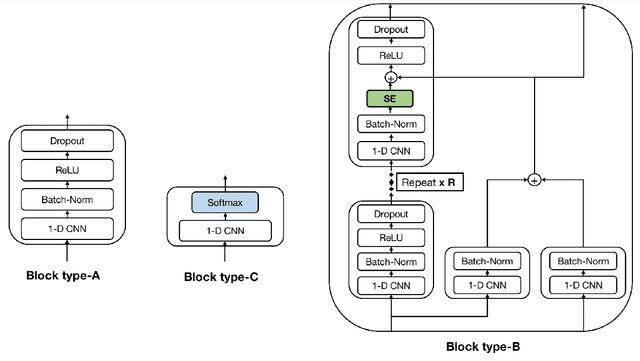

Convolutional Neural Networks (CNN) have shown promising results for the task of Handwritten Text Recognition (HTR) but they still fall behind Recurrent Neural Networks (RNNs)/Transformer based models in terms of performance. In this paper, we propose a CNN based architecture that bridges this gap. Our work, Easter2.0, is composed of multiple layers of 1D Convolution, Batch Normalization, ReLU, Dropout, Dense Residual connection, Squeeze-and-Excitation module and make use of Connectionist Temporal Classification (CTC) loss. In addition to the Easter2.0 architecture, we propose a simple and effective data augmentation technique 'Tiling and Corruption (TACO)' relevant for the task of HTR/OCR. Our work achieves state-of-the-art results on IAM handwriting database when trained using only publicly available training data. In our experiments, we also present the impact of TACO augmentations and Squeeze-and-Excitation (SE) on text recognition accuracy. We further show that Easter2.0 is suitable for few-shot learning tasks and outperforms current best methods including Transformers when trained on limited amount of annotated data. Code and model is available at: https://github.com/kartikgill/Easter2
EASTER: Efficient and Scalable Text Recognizer
Aug 19, 2020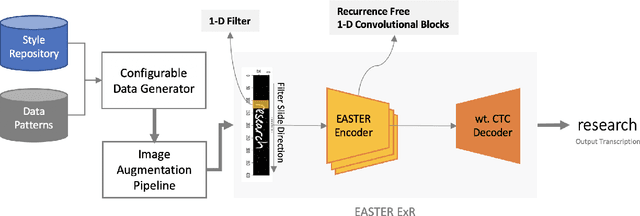



Recent progress in deep learning has led to the development of Optical Character Recognition (OCR) systems which perform remarkably well. Most research has been around recurrent networks as well as complex gated layers which make the overall solution complex and difficult to scale. In this paper, we present an Efficient And Scalable TExt Recognizer (EASTER) to perform optical character recognition on both machine printed and handwritten text. Our model utilises 1-D convolutional layers without any recurrence which enables parallel training with considerably less volume of data. We experimented with multiple variations of our architecture and one of the smallest variant (depth and number of parameter wise) performs comparably to RNN based complex choices. Our 20-layered deepest variant outperforms RNN architectures with a good margin on benchmarking datasets like IIIT-5k and SVT. We also showcase improvements over the current best results on offline handwritten text recognition task. We also present data generation pipelines with augmentation setup to generate synthetic datasets for both handwritten and machine printed text.
An Interpretable Deep Learning System for Automatically Scoring Request for Proposals
Aug 05, 2020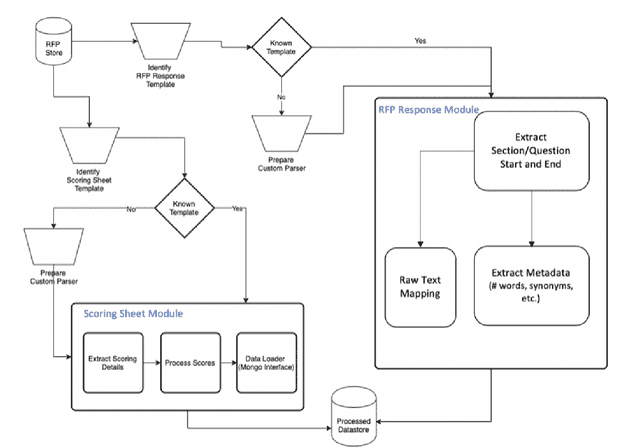



The Managed Care system within Medicaid (US Healthcare) uses Request For Proposals (RFP) to award contracts for various healthcare and related services. RFP responses are very detailed documents (hundreds of pages) submitted by competing organisations to win contracts. Subject matter expertise and domain knowledge play an important role in preparing RFP responses along with analysis of historical submissions. Automated analysis of these responses through Natural Language Processing (NLP) systems can reduce time and effort needed to explore historical responses, and assisting in writing better responses. Our work draws parallels between scoring RFPs and essay scoring models, while highlighting new challenges and the need for interpretability. Typical scoring models focus on word level impacts to grade essays and other short write-ups. We propose a novel Bi-LSTM based regression model, and provide deeper insight into phrases which latently impact scoring of responses. We contend the merits of our proposed methodology using extensive quantitative experiments. We also qualitatively asses the impact of important phrases using human evaluators. Finally, we introduce a novel problem statement that can be used to further improve the state of the art in NLP based automatic scoring systems.
A Simple and Interpretable Predictive Model for Healthcare
Jul 27, 2020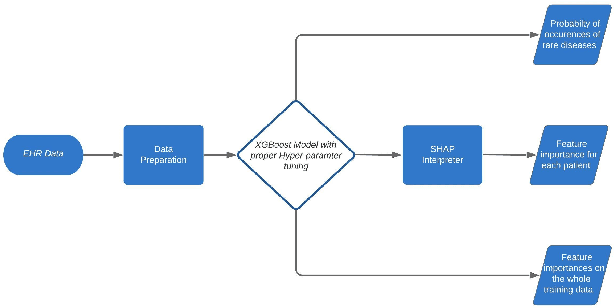
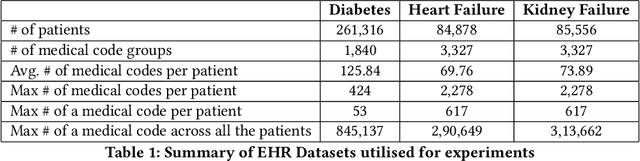
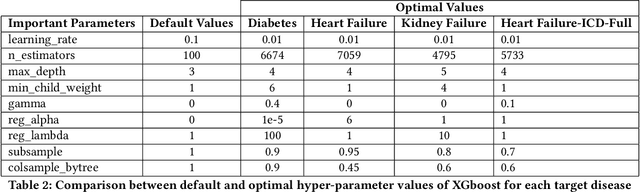
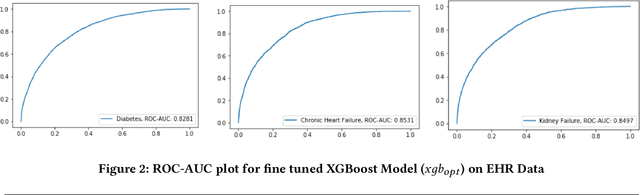
Deep Learning based models are currently dominating most state-of-the-art solutions for disease prediction. Existing works employ RNNs along with multiple levels of attention mechanisms to provide interpretability. These deep learning models, with trainable parameters running into millions, require huge amounts of compute and data to train and deploy. These requirements are sometimes so huge that they render usage of such models as unfeasible. We address these challenges by developing a simpler yet interpretable non-deep learning based model for application to EHR data. We model and showcase our work's results on the task of predicting first occurrence of a diagnosis, often overlooked in existing works. We push the capabilities of a tree based model and come up with a strong baseline for more sophisticated models. Its performance shows an improvement over deep learning based solutions (both, with and without the first-occurrence constraint) all the while maintaining interpretability.
Exclusion and Inclusion -- A model agnostic approach to feature importance in DNNs
Jul 13, 2020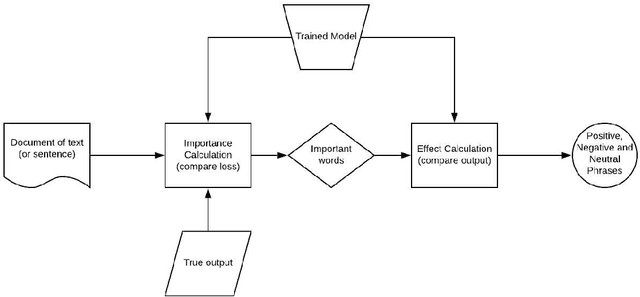

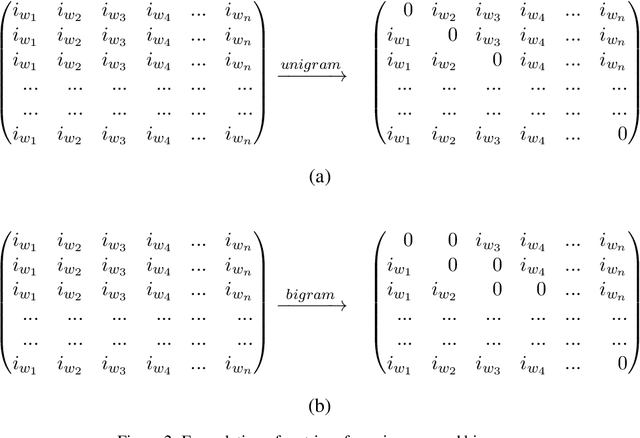
Deep Neural Networks in NLP have enabled systems to learn complex non-linear relationships. One of the major bottlenecks towards being able to use DNNs for real world applications is their characterization as black boxes. To solve this problem, we introduce a model agnostic algorithm which calculates phrase-wise importance of input features. We contend that our method is generalizable to a diverse set of tasks, by carrying out experiments for both Regression and Classification. We also observe that our approach is robust to outliers, implying that it only captures the essential aspects of the input.