 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEaster2.0: Improving convolutional models for handwritten text recognition
May 30, 2022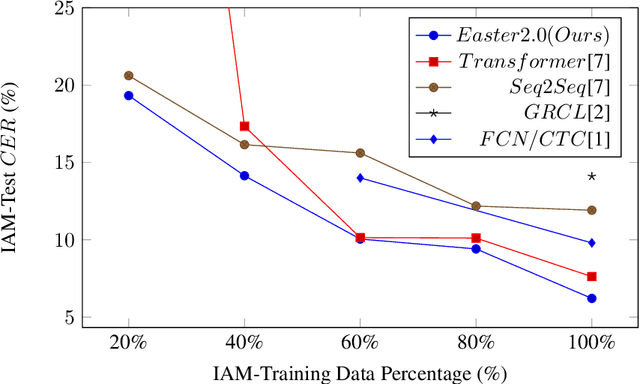

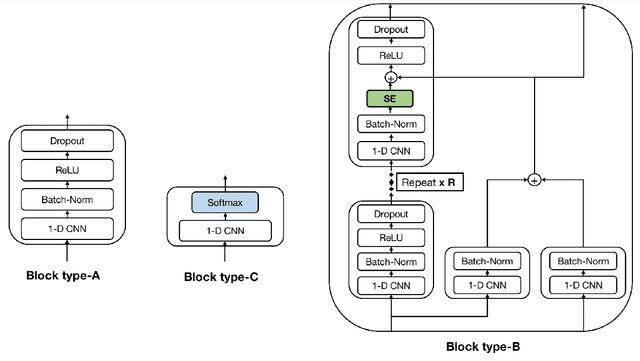

Convolutional Neural Networks (CNN) have shown promising results for the task of Handwritten Text Recognition (HTR) but they still fall behind Recurrent Neural Networks (RNNs)/Transformer based models in terms of performance. In this paper, we propose a CNN based architecture that bridges this gap. Our work, Easter2.0, is composed of multiple layers of 1D Convolution, Batch Normalization, ReLU, Dropout, Dense Residual connection, Squeeze-and-Excitation module and make use of Connectionist Temporal Classification (CTC) loss. In addition to the Easter2.0 architecture, we propose a simple and effective data augmentation technique 'Tiling and Corruption (TACO)' relevant for the task of HTR/OCR. Our work achieves state-of-the-art results on IAM handwriting database when trained using only publicly available training data. In our experiments, we also present the impact of TACO augmentations and Squeeze-and-Excitation (SE) on text recognition accuracy. We further show that Easter2.0 is suitable for few-shot learning tasks and outperforms current best methods including Transformers when trained on limited amount of annotated data. Code and model is available at: https://github.com/kartikgill/Easter2
EASTER: Efficient and Scalable Text Recognizer
Aug 19, 2020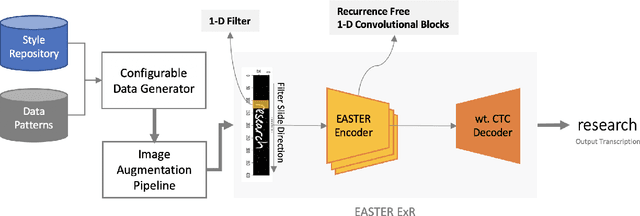



Recent progress in deep learning has led to the development of Optical Character Recognition (OCR) systems which perform remarkably well. Most research has been around recurrent networks as well as complex gated layers which make the overall solution complex and difficult to scale. In this paper, we present an Efficient And Scalable TExt Recognizer (EASTER) to perform optical character recognition on both machine printed and handwritten text. Our model utilises 1-D convolutional layers without any recurrence which enables parallel training with considerably less volume of data. We experimented with multiple variations of our architecture and one of the smallest variant (depth and number of parameter wise) performs comparably to RNN based complex choices. Our 20-layered deepest variant outperforms RNN architectures with a good margin on benchmarking datasets like IIIT-5k and SVT. We also showcase improvements over the current best results on offline handwritten text recognition task. We also present data generation pipelines with augmentation setup to generate synthetic datasets for both handwritten and machine printed text.