 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Down the Defenses: A Comparative Survey of Attacks on Large Language Models
Mar 03, 2024

Large Language Models (LLMs) have become a cornerstone in the field of Natural Language Processing (NLP), offering transformative capabilities in understanding and generating human-like text. However, with their rising prominence, the security and vulnerability aspects of these models have garnered significant attention. This paper presents a comprehensive survey of the various forms of attacks targeting LLMs, discussing the nature and mechanisms of these attacks, their potential impacts, and current defense strategies. We delve into topics such as adversarial attacks that aim to manipulate model outputs, data poisoning that affects model training, and privacy concerns related to training data exploitation. The paper also explores the effectiveness of different attack methodologies, the resilience of LLMs against these attacks, and the implications for model integrity and user trust. By examining the latest research, we provide insights into the current landscape of LLM vulnerabilities and defense mechanisms. Our objective is to offer a nuanced understanding of LLM attacks, foster awareness within the AI community, and inspire robust solutions to mitigate these risks in future developments.
NL2GDPR: Automatically Develop GDPR Compliant Android Application Features from Natural Language
Aug 29, 2022
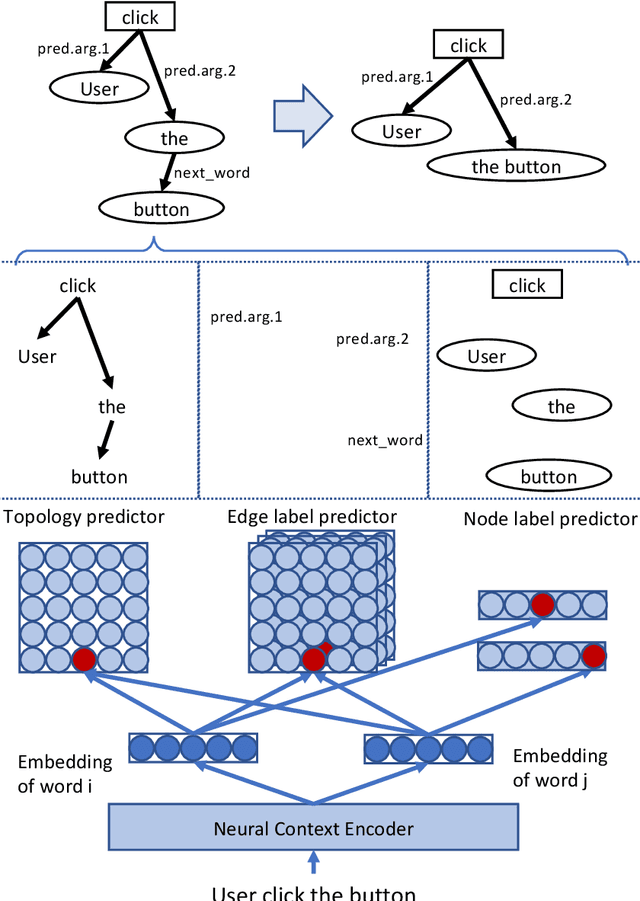

The recent privacy leakage incidences and the more strict policy regulations demand a much higher standard of compliance for companies and mobile apps. However, such obligations also impose significant challenges on app developers for complying with these regulations that contain various perspectives, activities, and roles, especially for small companies and developers who are less experienced in this matter or with limited resources. To address these hurdles, we develop an automatic tool, NL2GDPR, which can generate policies from natural language descriptions from the developer while also ensuring the app's functionalities are compliant with General Data Protection Regulation (GDPR). NL2GDPR is developed by leveraging an information extraction tool, OIA (Open Information Annotation), developed by Baidu Cognitive Computing Lab. At the core, NL2GDPR is a privacy-centric information extraction model, appended with a GDPR policy finder and a policy generator. We perform a comprehensive study to grasp the challenges in extracting privacy-centric information and generating privacy policies, while exploiting optimizations for this specific task. With NL2GDPR, we can achieve 92.9%, 95.2%, and 98.4% accuracy in correctly identifying GDPR policies related to personal data storage, process, and share types, respectively. To the best of our knowledge, NL2GDPR is the first tool that allows a developer to automatically generate GDPR compliant policies, with only the need of entering the natural language for describing the app features. Note that other non-GDPR-related features might be integrated with the generated features to build a complex app.