 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Enhanced Multi-hop Reasoning for Temporal Knowledge Question Answering
Jan 03, 2026Temporal knowledge graph question answering (TKGQA) involves multi-hop reasoning over temporally constrained entity relationships in the knowledge graph to answer a given question. However, at each hop, large language models (LLMs) retrieve subgraphs with numerous temporally similar and semantically complex relations, increasing the risk of suboptimal decisions and error propagation. To address these challenges, we propose the multi-hop reasoning enhanced (MRE) framework, which enhances both forward and backward reasoning to improve the identification of globally optimal reasoning trajectories. Specifically, MRE begins with prompt engineering to guide the LLM in generating diverse reasoning trajectories for a given question. Valid reasoning trajectories are then selected for supervised fine-tuning, serving as a cold-start strategy. Finally, we introduce Tree-Group Relative Policy Optimization (T-GRPO), a recursive, tree-structured learning-by-exploration approach. At each hop, exploration establishes strong causal dependencies on the previous hop, while evaluation is informed by multi-path exploration feedback from subsequent hops. Experimental results on two TKGQA benchmarks indicate that the proposed MRE-based model consistently surpasses state-of-the-art (SOTA) approaches in handling complex multi-hop queries. Further analysis highlights improved interpretability and robustness to noisy temporal annotations.
Not All Parameters Are Created Equal: Smart Isolation Boosts Fine-Tuning Performance
Aug 29, 2025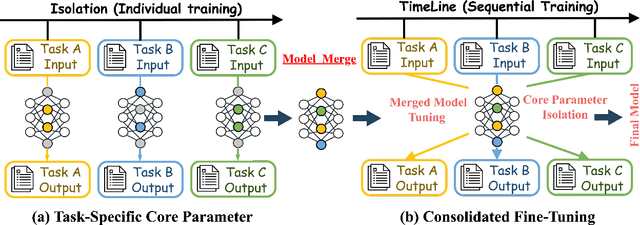
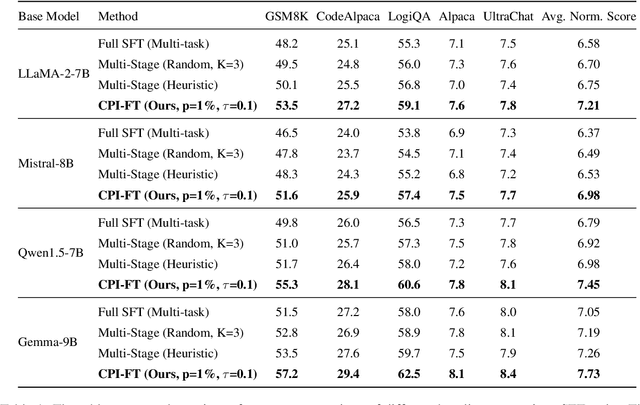

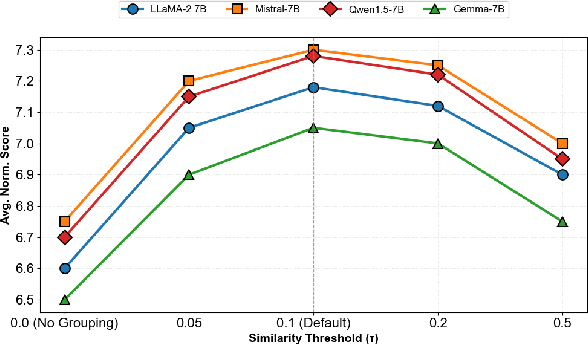
Supervised fine-tuning (SFT) is a pivotal approach to adapting large language models (LLMs) for downstream tasks; however, performance often suffers from the ``seesaw phenomenon'', where indiscriminate parameter updates yield progress on certain tasks at the expense of others. To address this challenge, we propose a novel \emph{Core Parameter Isolation Fine-Tuning} (CPI-FT) framework. Specifically, we first independently fine-tune the LLM on each task to identify its core parameter regions by quantifying parameter update magnitudes. Tasks with similar core regions are then grouped based on region overlap, forming clusters for joint modeling. We further introduce a parameter fusion technique: for each task, core parameters from its individually fine-tuned model are directly transplanted into a unified backbone, while non-core parameters from different tasks are smoothly integrated via Spherical Linear Interpolation (SLERP), mitigating destructive interference. A lightweight, pipelined SFT training phase using mixed-task data is subsequently employed, while freezing core regions from prior tasks to prevent catastrophic forgetting. Extensive experiments on multiple public benchmarks demonstrate that our approach significantly alleviates task interference and forgetting, consistently outperforming vanilla multi-task and multi-stage fine-tuning baselines.
Tool Graph Retriever: Exploring Dependency Graph-based Tool Retrieval for Large Language Models
Aug 07, 2025With the remarkable advancement of AI agents, the number of their equipped tools is increasing rapidly. However, integrating all tool information into the limited model context becomes impractical, highlighting the need for efficient tool retrieval methods. In this regard, dominant methods primarily rely on semantic similarities between tool descriptions and user queries to retrieve relevant tools. However, they often consider each tool independently, overlooking dependencies between tools, which may lead to the omission of prerequisite tools for successful task execution. To deal with this defect, in this paper, we propose Tool Graph Retriever (TGR), which exploits the dependencies among tools to learn better tool representations for retrieval. First, we construct a dataset termed TDI300K to train a discriminator for identifying tool dependencies. Then, we represent all candidate tools as a tool dependency graph and use graph convolution to integrate the dependencies into their representations. Finally, these updated tool representations are employed for online retrieval. Experimental results on several commonly used datasets show that our TGR can bring a performance improvement to existing dominant methods, achieving SOTA performance. Moreover, in-depth analyses also verify the importance of tool dependencies and the effectiveness of our TGR.
Shall Your Data Strategy Work? Perform a Swift Study
Feb 19, 2025This work presents a swift method to assess the efficacy of particular types of instruction-tuning data, utilizing just a handful of probe examples and eliminating the need for model retraining. This method employs the idea of gradient-based data influence estimation, analyzing the gradient projections of probe examples from the chosen strategy onto evaluation examples to assess its advantages. Building upon this method, we conducted three swift studies to investigate the potential of Chain-of-thought (CoT) data, query clarification data, and response evaluation data in enhancing model generalization. Subsequently, we embarked on a validation study to corroborate the findings of these swift studies. In this validation study, we developed training datasets tailored to each studied strategy and compared model performance with and without the use of these datasets. The results of the validation study aligned with the findings of the swift studies, validating the efficacy of our proposed method.
One2set + Large Language Model: Best Partners for Keyphrase Generation
Oct 04, 2024Keyphrase generation (KPG) aims to automatically generate a collection of phrases representing the core concepts of a given document. The dominant paradigms in KPG include one2seq and one2set. Recently, there has been increasing interest in applying large language models (LLMs) to KPG. Our preliminary experiments reveal that it is challenging for a single model to excel in both recall and precision. Further analysis shows that: 1) the one2set paradigm owns the advantage of high recall, but suffers from improper assignments of supervision signals during training; 2) LLMs are powerful in keyphrase selection, but existing selection methods often make redundant selections. Given these observations, we introduce a generate-then-select framework decomposing KPG into two steps, where we adopt a one2set-based model as generator to produce candidates and then use an LLM as selector to select keyphrases from these candidates. Particularly, we make two important improvements on our generator and selector: 1) we design an Optimal Transport-based assignment strategy to address the above improper assignments; 2) we model the keyphrase selection as a sequence labeling task to alleviate redundant selections. Experimental results on multiple benchmark datasets show that our framework significantly surpasses state-of-the-art models, especially in absent keyphrase prediction.
Eva-KELLM: A New Benchmark for Evaluating Knowledge Editing of LLMs
Aug 19, 2023Large language models (LLMs) possess a wealth of knowledge encoded in their parameters. However, this knowledge may become outdated or unsuitable over time. As a result, there has been a growing interest in knowledge editing for LLMs and evaluating its effectiveness. Existing studies primarily focus on knowledge editing using factual triplets, which not only incur high costs for collection but also struggle to express complex facts. Furthermore, these studies are often limited in their evaluation perspectives. In this paper, we propose Eva-KELLM, a new benchmark for evaluating knowledge editing of LLMs. This benchmark includes an evaluation framework and a corresponding dataset. Under our framework, we first ask the LLM to perform knowledge editing using raw documents, which provides a more convenient and universal approach compared to using factual triplets. We then evaluate the updated LLM from multiple perspectives. In addition to assessing the effectiveness of knowledge editing and the retention of unrelated knowledge from conventional studies, we further test the LLM's ability in two aspects: 1) Reasoning with the altered knowledge, aiming for the LLM to genuinely learn the altered knowledge instead of simply memorizing it. 2) Cross-lingual knowledge transfer, where the LLM updated with raw documents in one language should be capable of handling queries from another language. To facilitate further research, we construct and release the corresponding dataset. Using this benchmark, we investigate the effectiveness of several commonly-used knowledge editing methods. Experimental results indicate that the current methods for knowledge editing using raw documents are not effective in yielding satisfactory results, particularly when it comes to reasoning with altered knowledge and cross-lingual knowledge transfer.
Actively Supervised Clustering for Open Relation Extraction
Jun 08, 2023Current clustering-based Open Relation Extraction (OpenRE) methods usually adopt a two-stage pipeline. The first stage simultaneously learns relation representations and assignments. The second stage manually labels several instances and thus names the relation for each cluster. However, unsupervised objectives struggle to optimize the model to derive accurate clustering assignments, and the number of clusters has to be supplied in advance. In this paper, we present a novel setting, named actively supervised clustering for OpenRE. Our insight lies in that clustering learning and relation labeling can be alternately performed, providing the necessary guidance for clustering without a significant increase in human effort. The key to the setting is selecting which instances to label. Instead of using classical active labeling strategies designed for fixed known classes, we propose a new strategy, which is applicable to dynamically discover clusters of unknown relations. Experimental results show that our method is able to discover almost all relational clusters in the data and improve the SOTA methods by 10.3\% and 5.2\%, on two datasets respectively.
RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction
Jun 08, 2023Semantic matching is a mainstream paradigm of zero-shot relation extraction, which matches a given input with a corresponding label description. The entities in the input should exactly match their hypernyms in the description, while the irrelevant contexts should be ignored when matching. However, general matching methods lack explicit modeling of the above matching pattern. In this work, we propose a fine-grained semantic matching method tailored for zero-shot relation extraction. Following the above matching pattern, we decompose the sentence-level similarity score into entity and context matching scores. Due to the lack of explicit annotations of the redundant components, we design a feature distillation module to adaptively identify the relation-irrelevant features and reduce their negative impact on context matching. Experimental results show that our method achieves higher matching $F_1$ score and has an inference speed 10 times faster, when compared with the state-of-the-art methods.
How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks
Mar 01, 2023

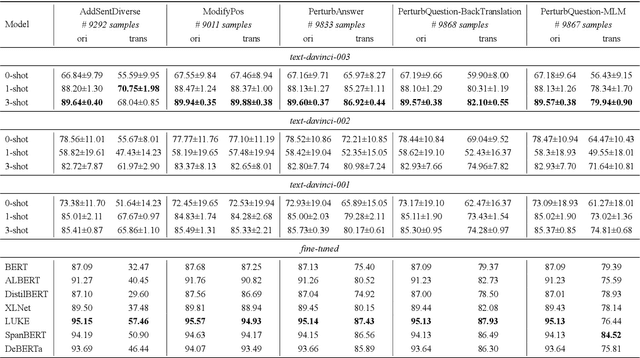

The GPT-3.5 models have demonstrated impressive performance in various Natural Language Processing (NLP) tasks, showcasing their strong understanding and reasoning capabilities. However, their robustness and abilities to handle various complexities of the open world have yet to be explored, which is especially crucial in assessing the stability of models and is a key aspect of trustworthy AI. In this study, we perform a comprehensive experimental analysis of GPT-3.5, exploring its robustness using 21 datasets (about 116K test samples) with 66 text transformations from TextFlint that cover 9 popular Natural Language Understanding (NLU) tasks. Our findings indicate that while GPT-3.5 outperforms existing fine-tuned models on some tasks, it still encounters significant robustness degradation, such as its average performance dropping by up to 35.74\% and 43.59\% in natural language inference and sentiment analysis tasks, respectively. We also show that GPT-3.5 faces some specific robustness challenges, including robustness instability, prompt sensitivity, and number sensitivity. These insights are valuable for understanding its limitations and guiding future research in addressing these challenges to enhance GPT-3.5's overall performance and generalization abilities.
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022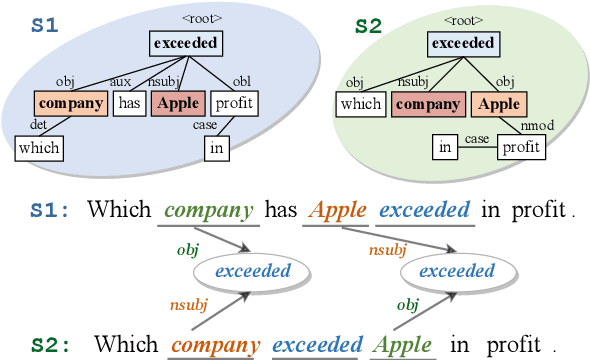
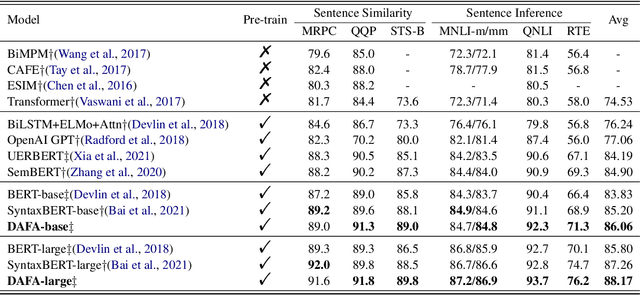
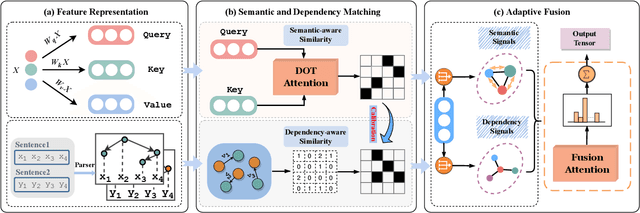
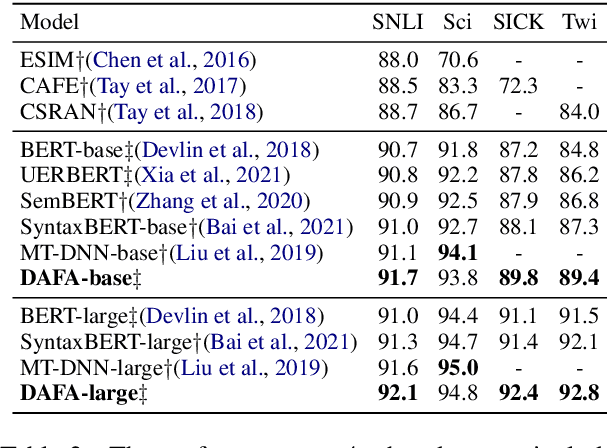
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.