 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileBench-OL: A Comprehensive Chinese Benchmark for Evaluating Mobile GUI Agents in Real-World Environment
Jan 29, 2026Recent advances in mobile Graphical User Interface (GUI) agents highlight the growing need for comprehensive evaluation benchmarks. While new online benchmarks offer more realistic testing than offline ones, they tend to focus on the agents' task instruction-following ability while neglecting their reasoning and exploration ability. Moreover, these benchmarks do not consider the random noise in real-world mobile environments. This leads to a gap between benchmarks and real-world environments. To addressing these limitations, we propose MobileBench-OL, an online benchmark with 1080 tasks from 80 Chinese apps. It measures task execution, complex reasoning, and noise robustness of agents by including 5 subsets, which set multiple evaluation dimensions. We also provide an auto-eval framework with a reset mechanism, enabling stable and repeatable real-world benchmarking. Evaluating 12 leading GUI agents on MobileBench-OL shows significant room for improvement to meet real-world requirements. Human evaluation further confirms that MobileBench-OL can reliably measure the performance of leading GUI agents in real environments. Our data and code will be released upon acceptance.
BacktrackAgent: Enhancing GUI Agent with Error Detection and Backtracking Mechanism
May 27, 2025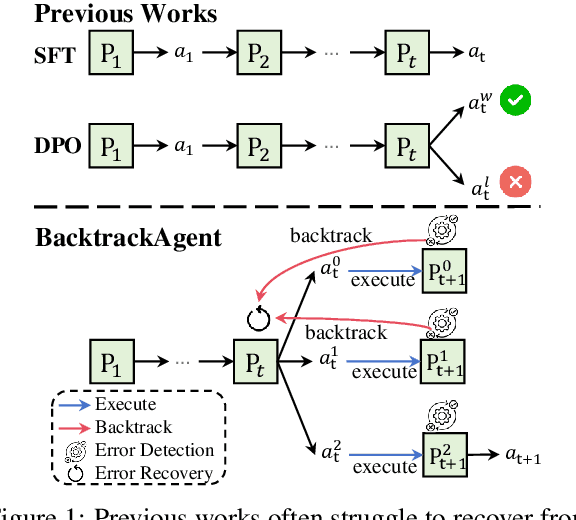
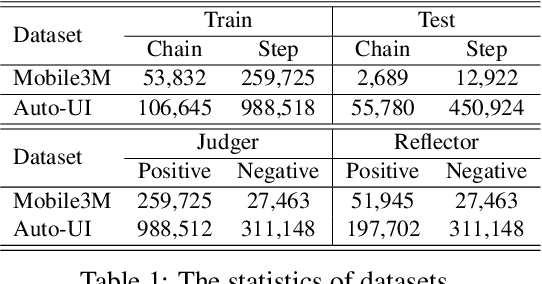
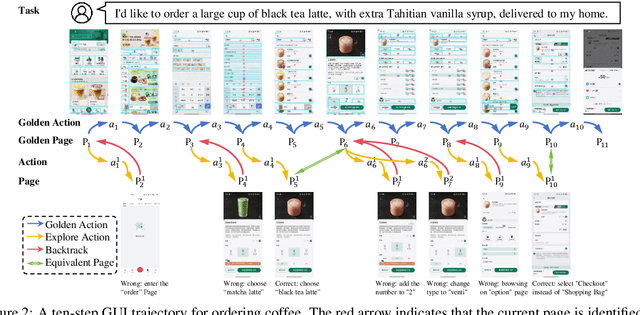
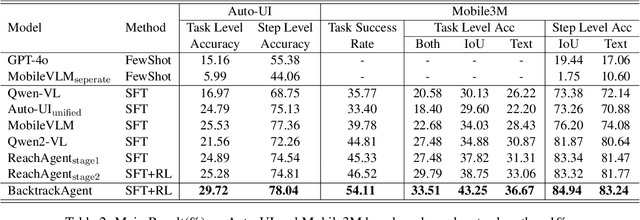
Graphical User Interface (GUI) agents have gained substantial attention due to their impressive capabilities to complete tasks through multiple interactions within GUI environments. However, existing agents primarily focus on enhancing the accuracy of individual actions and often lack effective mechanisms for detecting and recovering from errors. To address these shortcomings, we propose the BacktrackAgent, a robust framework that incorporates a backtracking mechanism to improve task completion efficiency. BacktrackAgent includes verifier, judger, and reflector components as modules for error detection and recovery, while also applying judgment rewards to further enhance the agent's performance. Additionally, we develop a training dataset specifically designed for the backtracking mechanism, which considers the outcome pages after action executions. Experimental results show that BacktrackAgent has achieved performance improvements in both task success rate and step accuracy on Mobile3M and Auto-UI benchmarks. Our data and code will be released upon acceptance.
ReachAgent: Enhancing Mobile Agent via Page Reaching and Operation
Feb 05, 2025



Recently, mobile AI agents have gained increasing attention. Given a task, mobile AI agents can interact with mobile devices in multiple steps and finally form a GUI flow that solves the task. However, existing agents tend to focus on most task-relevant elements at each step, leading to local optimal solutions and ignoring the overall GUI flow. To address this issue, we constructed a training dataset called MobileReach, which breaks the task into page reaching and operation subtasks. Furthermore, we propose ReachAgent, a two-stage framework that focuses on improving its task-completion abilities. It utilizes the page reaching and page operation subtasks, along with reward-based preference GUI flows, to further enhance the agent. Experimental results show that ReachAgent significantly improves the IoU Acc and Text Acc by 7.12% and 7.69% on the step-level and 4.72% and 4.63% on the task-level compared to the SOTA agent. Our data and code will be released upon acceptance.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.