 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Framework for Solving High-Frequency Helmholtz Equations via Diffusion Models
Feb 03, 2026Deterministic neural operators perform well on many PDEs but can struggle with the approximation of high-frequency wave phenomena, where strong input-to-output sensitivity makes operator learning challenging, and spectral bias blurs oscillations. We argue for adopting a probabilistic approach for approximating waves in high-frequency regime, and develop our probabilistic framework using a score-based conditional diffusion operator. After demonstrating a stability analysis of the Helmholtz operator, we present our numerical experiments across a wide range of frequencies, benchmarked against other popular data-driven and machine learning approaches for waves. We show that our probabilistic neural operator consistently produces robust predictions with the lowest errors in $L^2$, $H^1$, and energy norms. Moreover, unlike all the other tested deterministic approaches, our framework remarkably captures uncertainties in the input sound speed map propagated to the solution field. We envision that our results position probabilistic operator learning as a principled and effective approach for solving complex PDEs such as Helmholtz in the challenging high-frequency regime.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025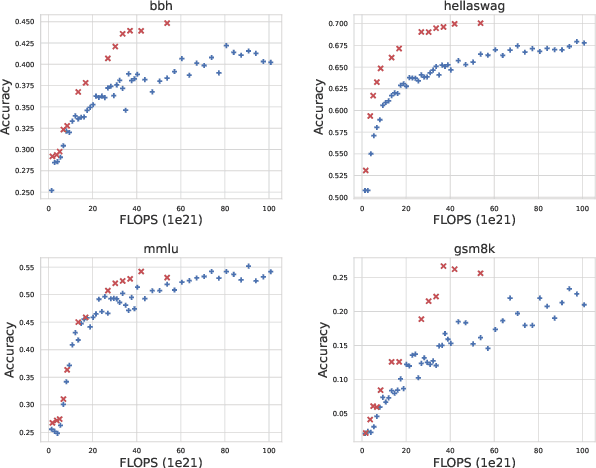
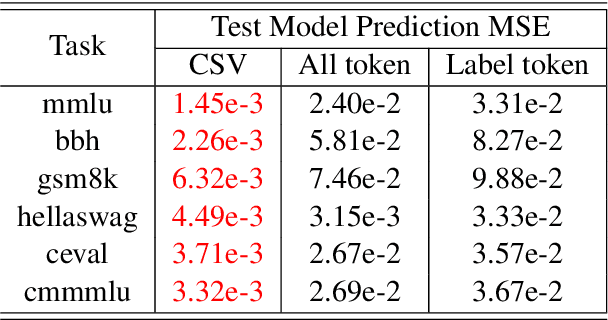
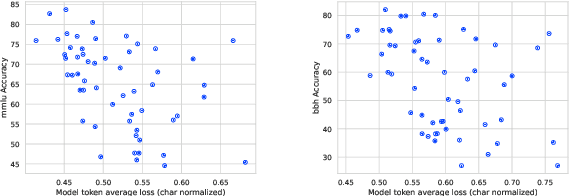
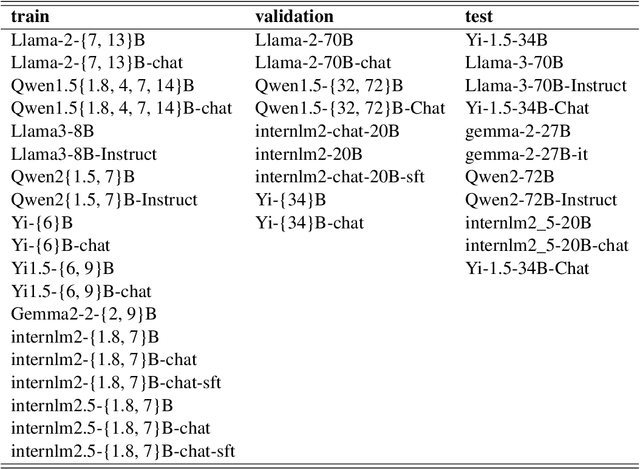
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices
Sep 03, 2024



Recent advancements in large language models (LLMs) with extended context windows have significantly improved tasks such as information extraction, question answering, and complex planning scenarios. In order to achieve success in long context tasks, a large amount of work has been done to enhance the long context capabilities of the model through synthetic data. Existing methods typically utilize the Self-Instruct framework to generate instruction tuning data for better long context capability improvement. However, our preliminary experiments indicate that less than 35% of generated samples are multi-hop, and more than 40% exhibit poor quality, limiting comprehensive understanding and further research. To improve the quality of synthetic data, we propose the Multi-agent Interactive Multi-hop Generation (MIMG) framework, incorporating a Quality Verification Agent, a Single-hop Question Generation Agent, a Multiple Question Sampling Strategy, and a Multi-hop Question Merger Agent. This framework improves the data quality, with the proportion of high-quality, multi-hop, and diverse data exceeding 85%. Furthermore, we systematically investigate strategies for document selection, question merging, and validation techniques through extensive experiments across various models. Our findings show that our synthetic high-quality long-context instruction data significantly enhances model performance, even surpassing models trained on larger amounts of human-annotated data. Our code is available at: https://github.com/WowCZ/LongMIT.
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Jun 06, 2024



Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
EasyJailbreak: A Unified Framework for Jailbreaking Large Language Models
Mar 18, 2024



Jailbreak attacks are crucial for identifying and mitigating the security vulnerabilities of Large Language Models (LLMs). They are designed to bypass safeguards and elicit prohibited outputs. However, due to significant differences among various jailbreak methods, there is no standard implementation framework available for the community, which limits comprehensive security evaluations. This paper introduces EasyJailbreak, a unified framework simplifying the construction and evaluation of jailbreak attacks against LLMs. It builds jailbreak attacks using four components: Selector, Mutator, Constraint, and Evaluator. This modular framework enables researchers to easily construct attacks from combinations of novel and existing components. So far, EasyJailbreak supports 11 distinct jailbreak methods and facilitates the security validation of a broad spectrum of LLMs. Our validation across 10 distinct LLMs reveals a significant vulnerability, with an average breach probability of 60% under various jailbreaking attacks. Notably, even advanced models like GPT-3.5-Turbo and GPT-4 exhibit average Attack Success Rates (ASR) of 57% and 33%, respectively. We have released a wealth of resources for researchers, including a web platform, PyPI published package, screencast video, and experimental outputs.
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Jan 21, 2024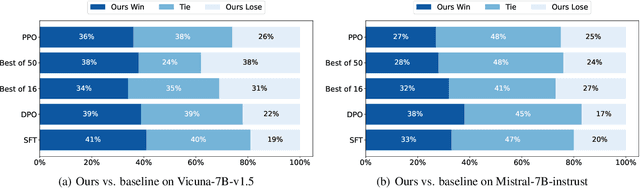
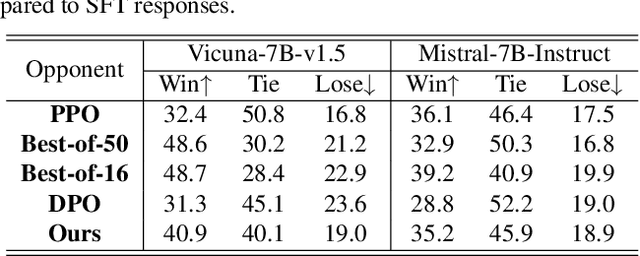


The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce \textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset will be published on \url{https://github.com/Wizardcoast/Linear_Alignment.git}.
TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models
Oct 10, 2023Aligned large language models (LLMs) demonstrate exceptional capabilities in task-solving, following instructions, and ensuring safety. However, the continual learning aspect of these aligned LLMs has been largely overlooked. Existing continual learning benchmarks lack sufficient challenge for leading aligned LLMs, owing to both their simplicity and the models' potential exposure during instruction tuning. In this paper, we introduce TRACE, a novel benchmark designed to evaluate continual learning in LLMs. TRACE consists of 8 distinct datasets spanning challenging tasks including domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. All datasets are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Our experiments show that after training on TRACE, aligned LLMs exhibit significant declines in both general ability and instruction-following capabilities. For example, the accuracy of llama2-chat 13B on gsm8k dataset declined precipitously from 28.8\% to 2\% after training on our datasets. This highlights the challenge of finding a suitable tradeoff between achieving performance on specific tasks while preserving the original prowess of LLMs. Empirical findings suggest that tasks inherently equipped with reasoning paths contribute significantly to preserving certain capabilities of LLMs against potential declines. Motivated by this, we introduce the Reasoning-augmented Continual Learning (RCL) approach. RCL integrates task-specific cues with meta-rationales, effectively reducing catastrophic forgetting in LLMs while expediting convergence on novel tasks.
The Rise and Potential of Large Language Model Based Agents: A Survey
Sep 19, 2023



For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent agents, but they mainly focus on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many researchers have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. In this paper, we perform a comprehensive survey on LLM-based agents. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for agents. Building upon this, we present a general framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored for different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge from an agent society, and the insights they offer for human society. Finally, we discuss several key topics and open problems within the field. A repository for the related papers at https://github.com/WooooDyy/LLM-Agent-Paper-List.