 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Paper and Code
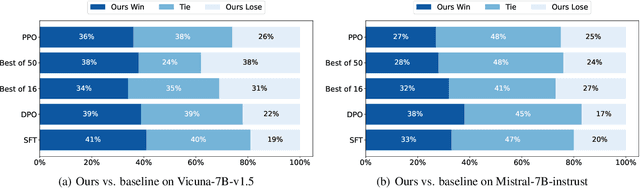
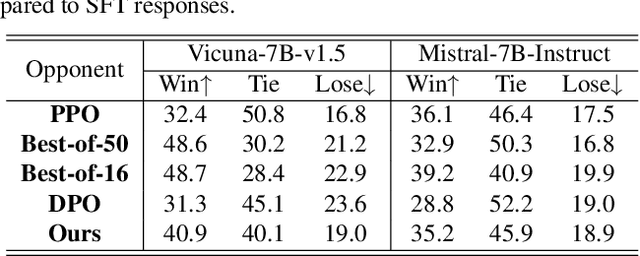


The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce \textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset will be published on \url{https://github.com/Wizardcoast/Linear_Alignment.git}.