 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025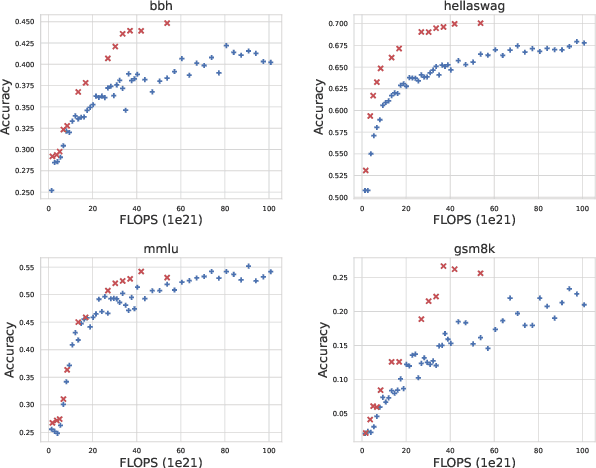
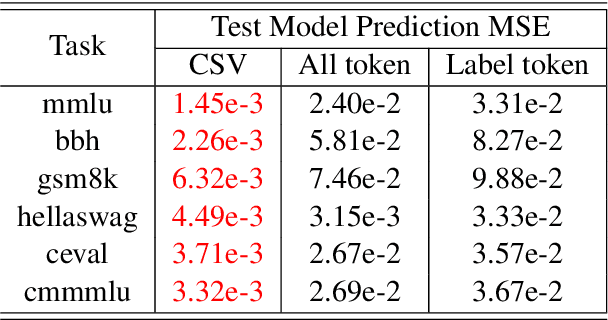
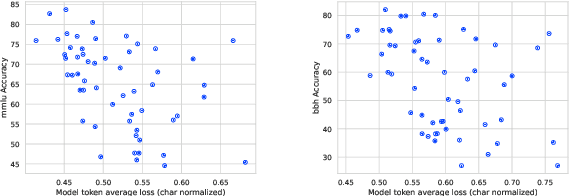
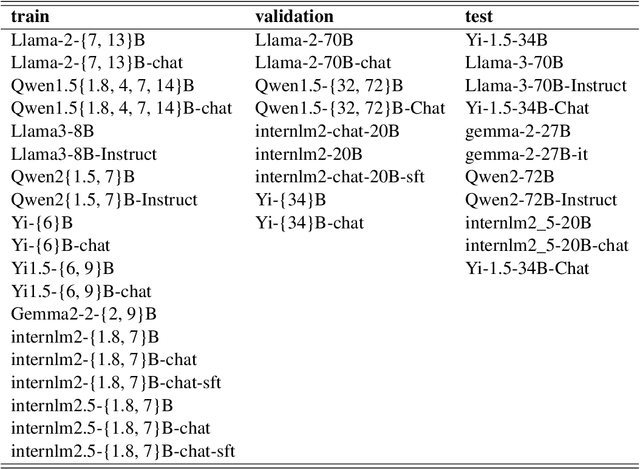
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Inverse-Q*: Token Level Reinforcement Learning for Aligning Large Language Models Without Preference Data
Aug 27, 2024Reinforcement Learning from Human Feedback (RLHF) has proven effective in aligning large language models with human intentions, yet it often relies on complex methodologies like Proximal Policy Optimization (PPO) that require extensive hyper-parameter tuning and present challenges in sample efficiency and stability. In this paper, we introduce Inverse-Q*, an innovative framework that transcends traditional RL methods by optimizing token-level reinforcement learning without the need for additional reward or value models. Inverse-Q* leverages direct preference optimization techniques but extends them by estimating the conditionally optimal policy directly from the model's responses, facilitating more granular and flexible policy shaping. Our approach reduces reliance on human annotation and external supervision, making it especially suitable for low-resource settings. We present extensive experimental results demonstrating that Inverse-Q* not only matches but potentially exceeds the effectiveness of PPO in terms of convergence speed and the alignment of model responses with human preferences. Our findings suggest that Inverse-Q* offers a practical and robust alternative to conventional RLHF approaches, paving the way for more efficient and adaptable model training approaches.
Navigating the OverKill in Large Language Models
Jan 31, 2024



Large language models are meticulously aligned to be both helpful and harmless. However, recent research points to a potential overkill which means models may refuse to answer benign queries. In this paper, we investigate the factors for overkill by exploring how models handle and determine the safety of queries. Our findings reveal the presence of shortcuts within models, leading to an over-attention of harmful words like 'kill' and prompts emphasizing safety will exacerbate overkill. Based on these insights, we introduce Self-Contrastive Decoding (Self-CD), a training-free and model-agnostic strategy, to alleviate this phenomenon. We first extract such over-attention by amplifying the difference in the model's output distributions when responding to system prompts that either include or omit an emphasis on safety. Then we determine the final next-token predictions by downplaying the over-attention from the model via contrastive decoding. Empirical results indicate that our method has achieved an average reduction of the refusal rate by 20\% while having almost no impact on safety.
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Jan 21, 2024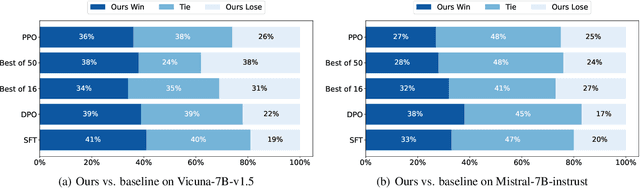
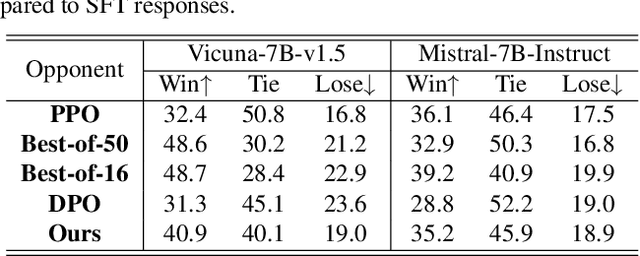


The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce \textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset will be published on \url{https://github.com/Wizardcoast/Linear_Alignment.git}.
Orthogonal Subspace Learning for Language Model Continual Learning
Oct 22, 2023Benefiting from massive corpora and advanced hardware, large language models (LLMs) exhibit remarkable capabilities in language understanding and generation. However, their performance degrades in scenarios where multiple tasks are encountered sequentially, also known as catastrophic forgetting. In this paper, we propose orthogonal low-rank adaptation (O-LoRA), a simple and efficient approach for continual learning in language models, effectively mitigating catastrophic forgetting while learning new tasks. Specifically, O-LoRA learns tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Our method induces only marginal additional parameter costs and requires no user data storage for replay. Experimental results on continual learning benchmarks show that our method outperforms state-of-the-art methods. Furthermore, compared to previous approaches, our method excels in preserving the generalization ability of LLMs on unseen tasks.