 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKDFlow: A User-Friendly and Efficient Knowledge Distillation Framework for Large Language Models
Mar 02, 2026Knowledge distillation (KD) is an essential technique to compress large language models (LLMs) into smaller ones. However, despite the distinct roles of the student model and the teacher model in KD, most existing frameworks still use a homogeneous training backend (e.g., FSDP and DeepSpeed) for both models, leading to suboptimal training efficiency. In this paper, we present a novel framework for LLM distillation, termed \textbf{KDFlow}, which features a decoupled architecture and employs SGLang for teacher inference. By bridging the training efficiency of FSDP2 and the inference efficiency of SGLang, KDFlow achieves full utilization of both advantages in a unified system. Moreover, instead of transferring full logits across different processes, our framework only transmits the teacher's hidden states using zero-copy data transfer and recomputes the logits on the student side, effectively balancing the communication cost and KD performance. Furthermore, our framework supports both off-policy and on-policy distillation and incorporates KD algorithms for cross-tokenizer KD through highly extensible and user-friendly APIs. Experiments show that KDFlow can achieve \textbf{1.44$\times$ to 6.36$\times$} speedup compared to current KD frameworks, enabling researchers to rapidly prototype and scale LLM distillation with minimal engineering overhead. Code is available at: https://github.com/songmzhang/KDFlow
AlignDistil: Token-Level Language Model Alignment as Adaptive Policy Distillation
Mar 04, 2025In modern large language models (LLMs), LLM alignment is of crucial importance and is typically achieved through methods such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). However, in most existing methods for LLM alignment, all tokens in the response are optimized using a sparse, response-level reward or preference annotation. The ignorance of token-level rewards may erroneously punish high-quality tokens or encourage low-quality tokens, resulting in suboptimal performance and slow convergence speed. To address this issue, we propose AlignDistil, an RLHF-equivalent distillation method for token-level reward optimization. Specifically, we introduce the reward learned by DPO into the RLHF objective and theoretically prove the equivalence between this objective and a token-level distillation process, where the teacher distribution linearly combines the logits from the DPO model and a reference model. On this basis, we further bridge the accuracy gap between the reward from the DPO model and the pure reward model, by building a contrastive DPO reward with a normal and a reverse DPO model. Moreover, to avoid under- and over-optimization on different tokens, we design a token adaptive logit extrapolation mechanism to construct an appropriate teacher distribution for each token. Experimental results demonstrate the superiority of our AlignDistil over existing methods and showcase fast convergence due to its token-level distributional reward optimization.
Improving End-to-end Speech Translation by Leveraging Auxiliary Speech and Text Data
Dec 04, 2022



We present a method for introducing a text encoder into pre-trained end-to-end speech translation systems. It enhances the ability of adapting one modality (i.e., source-language speech) to another (i.e., source-language text). Thus, the speech translation model can learn from both unlabeled and labeled data, especially when the source-language text data is abundant. Beyond this, we present a denoising method to build a robust text encoder that can deal with both normal and noisy text data. Our system sets new state-of-the-arts on the MuST-C En-De, En-Fr, and LibriSpeech En-Fr tasks.
Continual Learning of Neural Machine Translation within Low Forgetting Risk Regions
Nov 04, 2022



This paper considers continual learning of large-scale pretrained neural machine translation model without accessing the previous training data or introducing model separation. We argue that the widely used regularization-based methods, which perform multi-objective learning with an auxiliary loss, suffer from the misestimate problem and cannot always achieve a good balance between the previous and new tasks. To solve the problem, we propose a two-stage training method based on the local features of the real loss. We first search low forgetting risk regions, where the model can retain the performance on the previous task as the parameters are updated, to avoid the catastrophic forgetting problem. Then we can continually train the model within this region only with the new training data to fit the new task. Specifically, we propose two methods to search the low forgetting risk regions, which are based on the curvature of loss and the impacts of the parameters on the model output, respectively. We conduct experiments on domain adaptation and more challenging language adaptation tasks, and the experimental results show that our method can achieve significant improvements compared with several strong baselines.
Increasing Visual Awareness in Multimodal Neural Machine Translation from an Information Theoretic Perspective
Oct 16, 2022
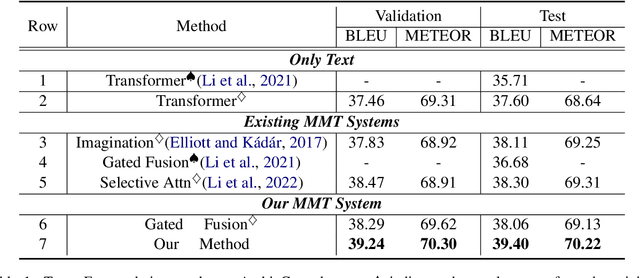

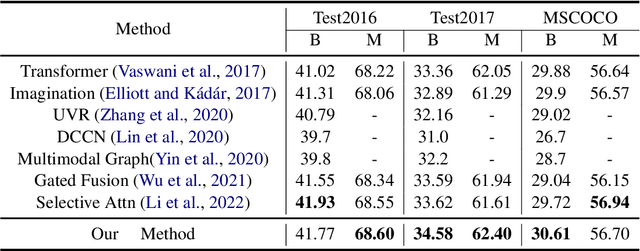
Multimodal machine translation (MMT) aims to improve translation quality by equipping the source sentence with its corresponding image. Despite the promising performance, MMT models still suffer the problem of input degradation: models focus more on textual information while visual information is generally overlooked. In this paper, we endeavor to improve MMT performance by increasing visual awareness from an information theoretic perspective. In detail, we decompose the informative visual signals into two parts: source-specific information and target-specific information. We use mutual information to quantify them and propose two methods for objective optimization to better leverage visual signals. Experiments on two datasets demonstrate that our approach can effectively enhance the visual awareness of MMT model and achieve superior results against strong baselines.
Stacked Acoustic-and-Textual Encoding: Integrating the Pre-trained Models into Speech Translation Encoders
May 12, 2021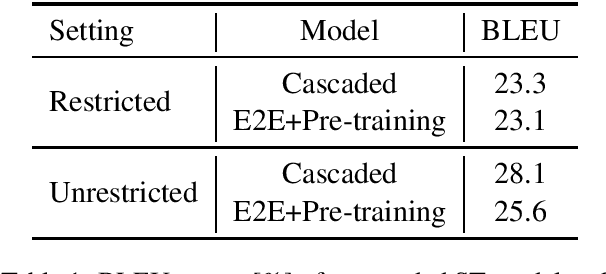
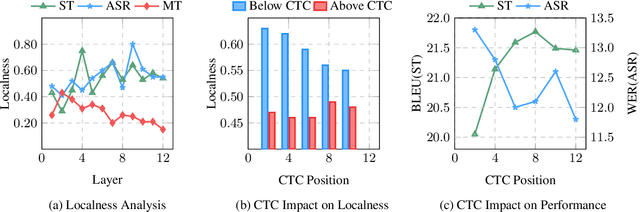
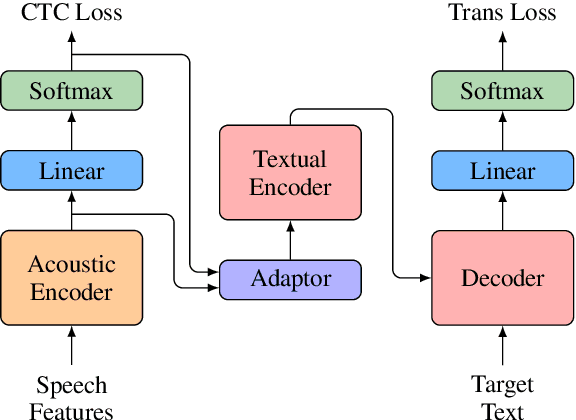
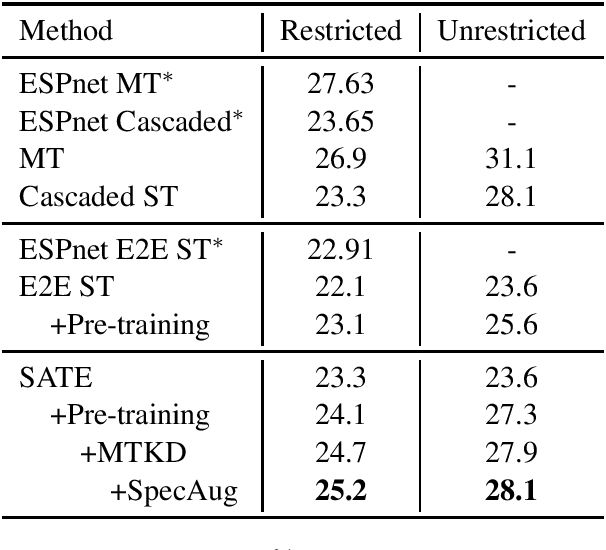
Encoder pre-training is promising in end-to-end Speech Translation (ST), given the fact that speech-to-translation data is scarce. But ST encoders are not simple instances of Automatic Speech Recognition (ASR) or Machine Translation (MT) encoders. For example, we find ASR encoders lack the global context representation, which is necessary for translation, whereas MT encoders are not designed to deal with long but locally attentive acoustic sequences. In this work, we propose a Stacked Acoustic-and-Textual Encoding (SATE) method for speech translation. Our encoder begins with processing the acoustic sequence as usual, but later behaves more like an MT encoder for a global representation of the input sequence. In this way, it is straightforward to incorporate the pre-trained models into the system. Also, we develop an adaptor module to alleviate the representation inconsistency between the pre-trained ASR encoder and MT encoder, and a multi-teacher knowledge distillation method to preserve the pre-training knowledge. Experimental results on the LibriSpeech En-Fr and MuST-C En-De show that our method achieves the state-of-the-art performance of 18.3 and 25.2 BLEU points. To our knowledge, we are the first to develop an end-to-end ST system that achieves comparable or even better BLEU performance than the cascaded ST counterpart when large-scale ASR and MT data is available.
Dynamic Curriculum Learning for Low-Resource Neural Machine Translation
Nov 30, 2020


Large amounts of data has made neural machine translation (NMT) a big success in recent years. But it is still a challenge if we train these models on small-scale corpora. In this case, the way of using data appears to be more important. Here, we investigate the effective use of training data for low-resource NMT. In particular, we propose a dynamic curriculum learning (DCL) method to reorder training samples in training. Unlike previous work, we do not use a static scoring function for reordering. Instead, the order of training samples is dynamically determined in two ways - loss decline and model competence. This eases training by highlighting easy samples that the current model has enough competence to learn. We test our DCL method in a Transformer-based system. Experimental results show that DCL outperforms several strong baselines on three low-resource machine translation benchmarks and different sized data of WMT' 16 En-De.
Code-switching pre-training for neural machine translation
Sep 17, 2020
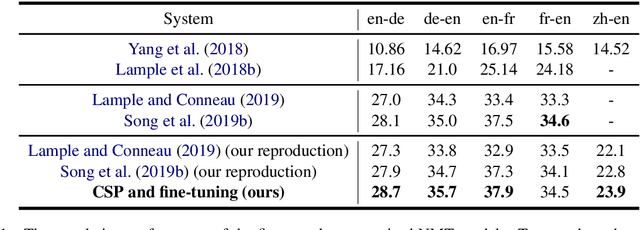

This paper proposes a new pre-training method, called Code-Switching Pre-training (CSP for short) for Neural Machine Translation (NMT). Unlike traditional pre-training method which randomly masks some fragments of the input sentence, the proposed CSP randomly replaces some words in the source sentence with their translation words in the target language. Specifically, we firstly perform lexicon induction with unsupervised word embedding mapping between the source and target languages, and then randomly replace some words in the input sentence with their translation words according to the extracted translation lexicons. CSP adopts the encoder-decoder framework: its encoder takes the code-mixed sentence as input, and its decoder predicts the replaced fragment of the input sentence. In this way, CSP is able to pre-train the NMT model by explicitly making the most of the cross-lingual alignment information extracted from the source and target monolingual corpus. Additionally, we relieve the pretrain-finetune discrepancy caused by the artificial symbols like [mask]. To verify the effectiveness of the proposed method, we conduct extensive experiments on unsupervised and supervised NMT. Experimental results show that CSP achieves significant improvements over baselines without pre-training or with other pre-training methods.
Learn to Segment Retinal Lesions and Beyond
Dec 25, 2019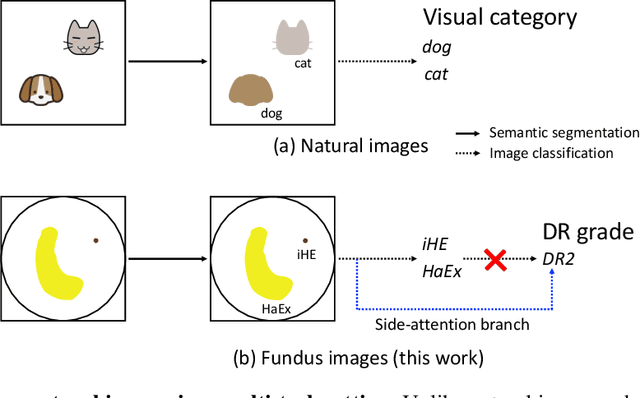

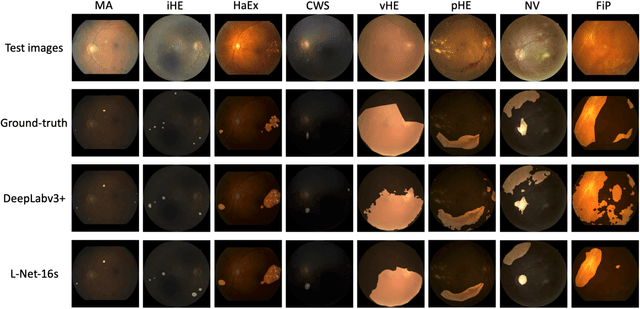

Towards automated retinal screening, this paper makes an endeavor to simultaneously achieve pixel-level retinal lesion segmentation and image-level disease classification. Such a multi-task approach is crucial for accurate and clinically interpretable disease diagnosis. Prior art is insufficient due to three challenges, that is, lesions lacking objective boundaries, clinical importance of lesions irrelevant to their size, and the lack of one-to-one correspondence between lesion and disease classes. This paper attacks the three challenges in the context of diabetic retinopathy (DR) grading. We propose L-Net, a new variant of fully convolutional networks, with its expansive path re-designed to tackle the first challenge. A dual loss that leverages both semantic segmentation and image classification losses is devised to resolve the second challenge. We propose Side-Attention Net (SiAN) as our multi-task framework. Harnessing L-Net as a side-attention branch, SiAN simultaneously improves DR grading and interprets the decision with lesion maps. A set of 12K fundus images is manually segmented by 45 ophthalmologists for 8 DR-related lesions, resulting in 290K manual segments in total. Extensive experiments on this large-scale dataset show that our proposed approach surpasses the prior art for multiple tasks including lesion segmentation, lesion classification and DR grading.