 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELO-Rated Sequence Rewards: Advancing Reinforcement Learning Models
Sep 05, 2024Reinforcement Learning (RL) is highly dependent on the meticulous design of the reward function. However, accurately assigning rewards to each state-action pair in Long-Term RL (LTRL) challenges is formidable. Consequently, RL agents are predominantly trained with expert guidance. Drawing on the principles of ordinal utility theory from economics, we propose a novel reward estimation algorithm: ELO-Rating based RL (ERRL). This approach is distinguished by two main features. Firstly, it leverages expert preferences over trajectories instead of cardinal rewards (utilities) to compute the ELO rating of each trajectory as its reward. Secondly, a new reward redistribution algorithm is introduced to mitigate training volatility in the absence of a fixed anchor reward. Our method demonstrates superior performance over several leading baselines in long-term scenarios (extending up to 5000 steps), where conventional RL algorithms falter. Furthermore, we conduct a thorough analysis of how expert preferences affect the outcomes.
Recouple Event Field via Probabilistic Bias for Event Extraction
May 19, 2023
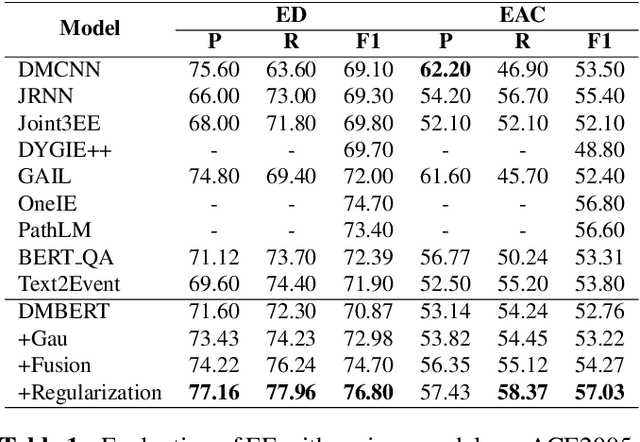
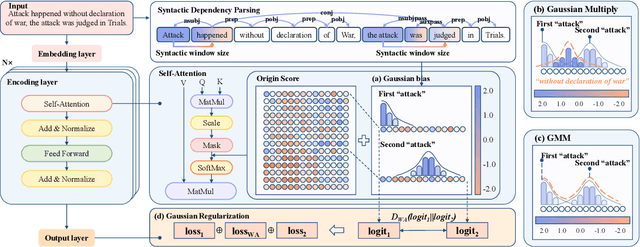
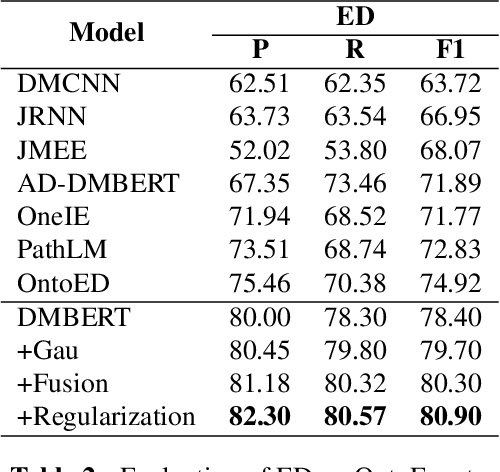
Event Extraction (EE), aiming to identify and classify event triggers and arguments from event mentions, has benefited from pre-trained language models (PLMs). However, existing PLM-based methods ignore the information of trigger/argument fields, which is crucial for understanding event schemas. To this end, we propose a Probabilistic reCoupling model enhanced Event extraction framework (ProCE). Specifically, we first model the syntactic-related event fields as probabilistic biases, to clarify the event fields from ambiguous entanglement. Furthermore, considering multiple occurrences of the same triggers/arguments in EE, we explore probabilistic interaction strategies among multiple fields of the same triggers/arguments, to recouple the corresponding clarified distributions and capture more latent information fields. Experiments on EE datasets demonstrate the effectiveness and generalization of our proposed approach.
Multi-stage Distillation Framework for Cross-Lingual Semantic Similarity Matching
Sep 13, 2022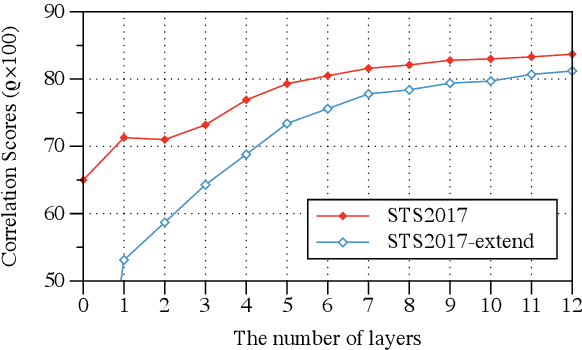
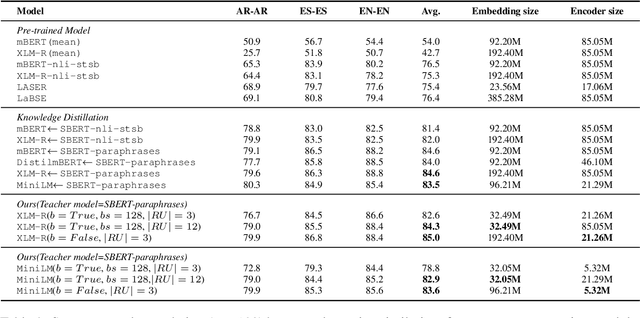
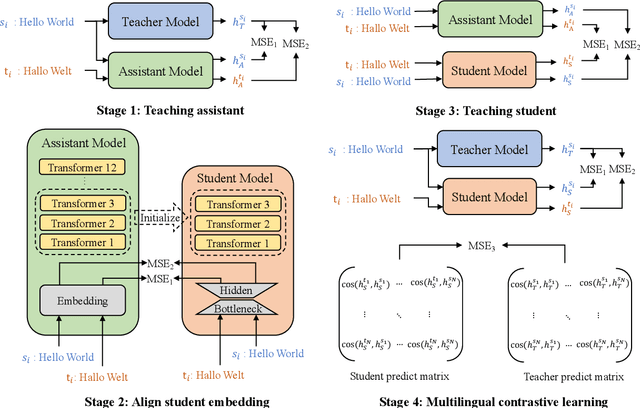
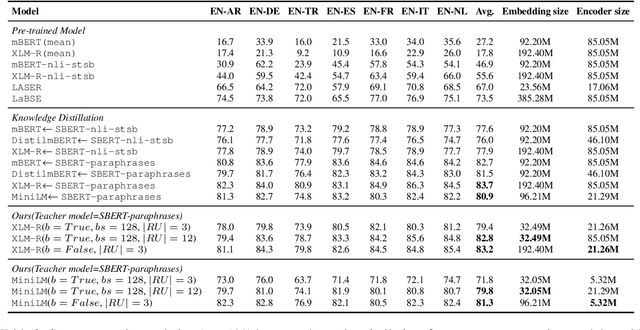
Previous studies have proved that cross-lingual knowledge distillation can significantly improve the performance of pre-trained models for cross-lingual similarity matching tasks. However, the student model needs to be large in this operation. Otherwise, its performance will drop sharply, thus making it impractical to be deployed to memory-limited devices. To address this issue, we delve into cross-lingual knowledge distillation and propose a multi-stage distillation framework for constructing a small-size but high-performance cross-lingual model. In our framework, contrastive learning, bottleneck, and parameter recurrent strategies are combined to prevent performance from being compromised during the compression process. The experimental results demonstrate that our method can compress the size of XLM-R and MiniLM by more than 50\%, while the performance is only reduced by about 1%.
Fully Self-Supervised Learning for Semantic Segmentation
Feb 24, 2022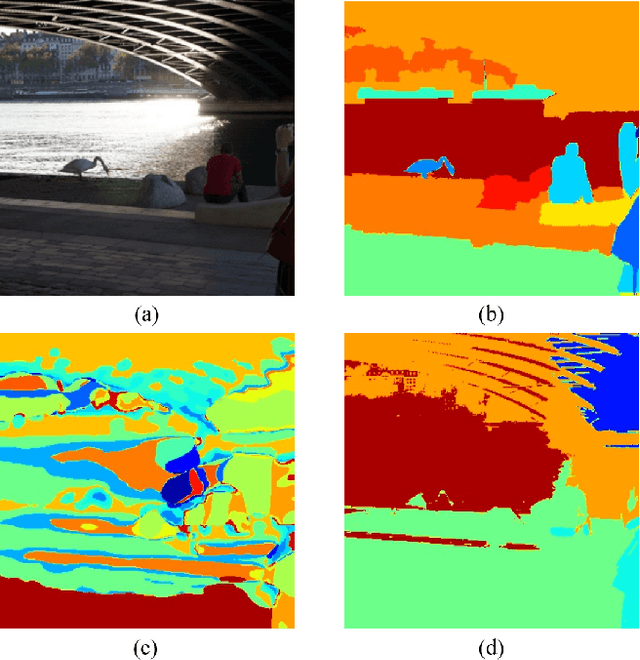
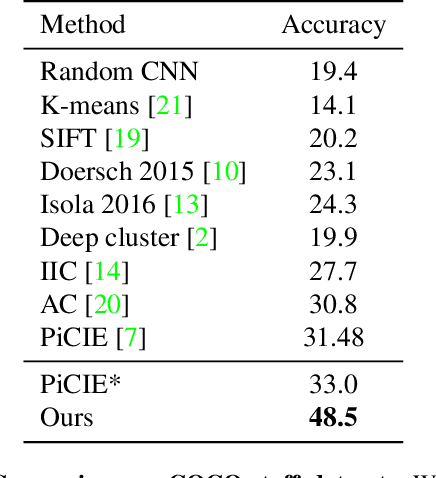
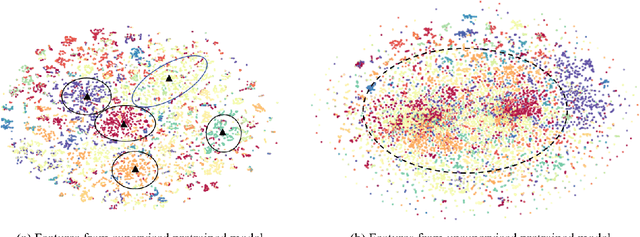
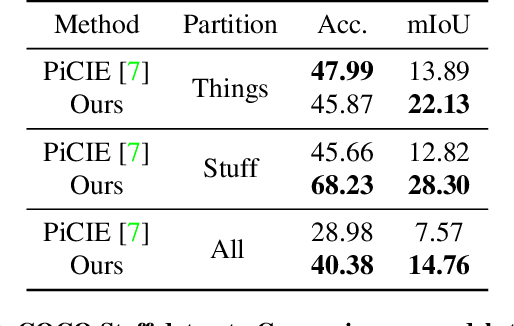
In this work, we present a fully self-supervised framework for semantic segmentation(FS^4). A fully bootstrapped strategy for semantic segmentation, which saves efforts for the huge amount of annotation, is crucial for building customized models from end-to-end for open-world domains. This application is eagerly needed in realistic scenarios. Even though recent self-supervised semantic segmentation methods have gained great progress, these works however heavily depend on the fully-supervised pretrained model and make it impossible a fully self-supervised pipeline. To solve this problem, we proposed a bootstrapped training scheme for semantic segmentation, which fully leveraged the global semantic knowledge for self-supervision with our proposed PGG strategy and CAE module. In particular, we perform pixel clustering and assignments for segmentation supervision. Preventing it from clustering a mess, we proposed 1) a pyramid-global-guided (PGG) training strategy to supervise the learning with pyramid image/patch-level pseudo labels, which are generated by grouping the unsupervised features. The stable global and pyramid semantic pseudo labels can prevent the segmentation from learning too many clutter regions or degrading to one background region; 2) in addition, we proposed context-aware embedding (CAE) module to generate global feature embedding in view of its neighbors close both in space and appearance in a non-trivial way. We evaluate our method on the large-scale COCO-Stuff dataset and achieved 7.19 mIoU improvements on both things and stuff objects
Semantic Matching from Different Perspectives
Feb 14, 2022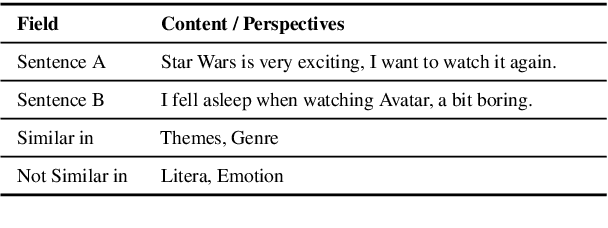
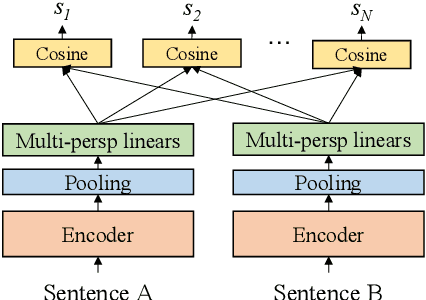
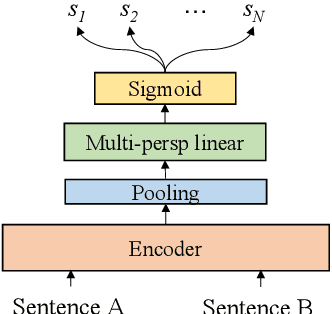

In this paper, we pay attention to the issue which is usually overlooked, i.e., \textit{similarity should be determined from different perspectives}. To explore this issue, we release a Multi-Perspective Text Similarity (MPTS) dataset, in which sentence similarities are labeled from twelve perspectives. Furthermore, we conduct a series of experimental analysis on this task by retrofitting some famous text matching models. Finally, we obtain several conclusions and baseline models, laying the foundation for the following investigation of this issue. The dataset and code are publicly available at Github\footnote{\url{https://github.com/autoliuweijie/MPTS}
Learning Debiased Models with Dynamic Gradient Alignment and Bias-conflicting Sample Mining
Nov 25, 2021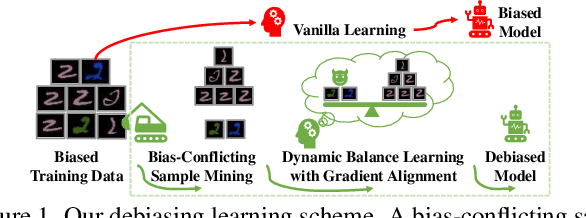
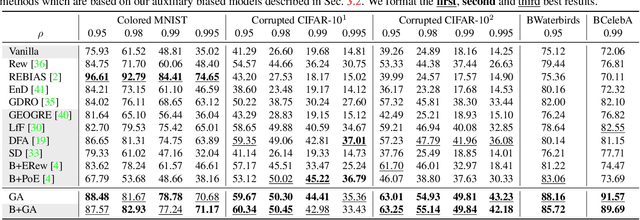

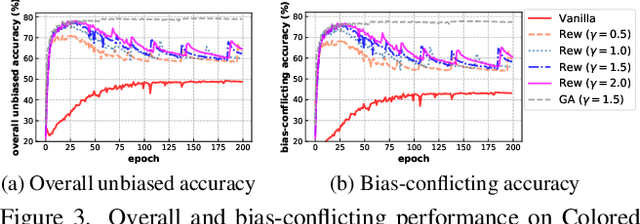
Deep neural networks notoriously suffer from dataset biases which are detrimental to model robustness, generalization and fairness. In this work, we propose a two-stage debiasing scheme to combat against the intractable unknown biases. Starting by analyzing the factors of the presence of biased models, we design a novel learning objective which cannot be reached by relying on biases alone. Specifically, debiased models are achieved with the proposed Gradient Alignment (GA) which dynamically balances the contributions of bias-aligned and bias-conflicting samples (refer to samples with/without bias cues respectively) throughout the whole training process, enforcing models to exploit intrinsic cues to make fair decisions. While in real-world scenarios, the potential biases are extremely hard to discover and prohibitively expensive to label manually. We further propose an automatic bias-conflicting sample mining method by peer-picking and training ensemble without prior knowledge of bias information. Experiments conducted on multiple datasets in various settings demonstrate the effectiveness and robustness of our proposed scheme, which successfully alleviates the negative impact of unknown biases and achieves state-of-the-art performance.
Maximize the Exploration of Congeneric Semantics for Weakly Supervised Semantic Segmentation
Oct 08, 2021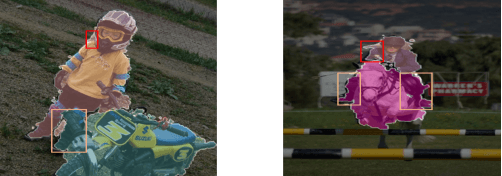

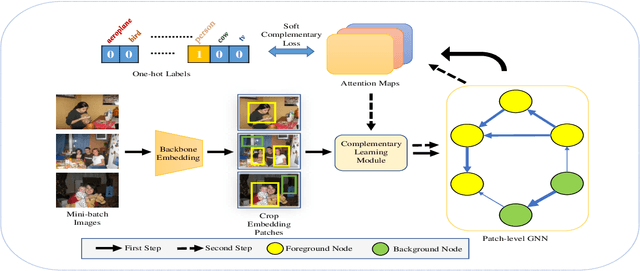
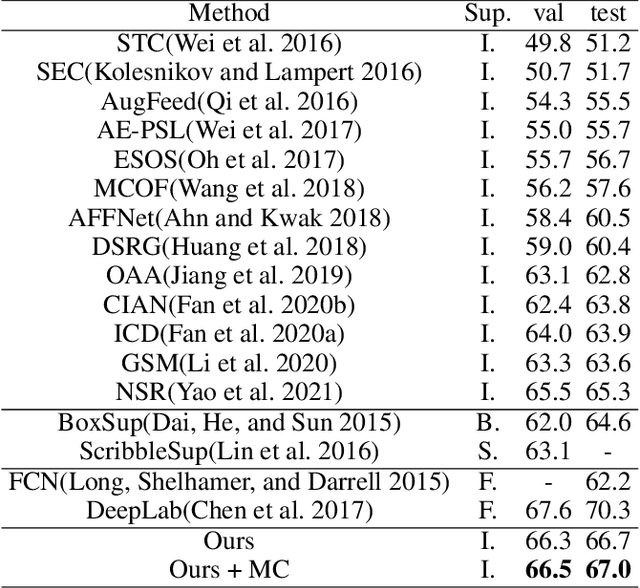
With the increase in the number of image data and the lack of corresponding labels, weakly supervised learning has drawn a lot of attention recently in computer vision tasks, especially in the fine-grained semantic segmentation problem. To alleviate human efforts from expensive pixel-by-pixel annotations, our method focuses on weakly supervised semantic segmentation (WSSS) with image-level tags, which are much easier to obtain. As a huge gap exists between pixel-level segmentation and image-level labels, how to reflect the image-level semantic information on each pixel is an important question. To explore the congeneric semantic regions from the same class to the maximum, we construct the patch-level graph neural network (P-GNN) based on the self-detected patches from different images that contain the same class labels. Patches can frame the objects as much as possible and include as little background as possible. The graph network that is established with patches as the nodes can maximize the mutual learning of similar objects. We regard the embedding vectors of patches as nodes, and use transformer-based complementary learning module to construct weighted edges according to the embedding similarity between different nodes. Moreover, to better supplement semantic information, we propose soft-complementary loss functions matched with the whole network structure. We conduct experiments on the popular PASCAL VOC 2012 benchmarks, and our model yields state-of-the-art performance.
Energy Aligning for Biased Models
Jun 07, 2021
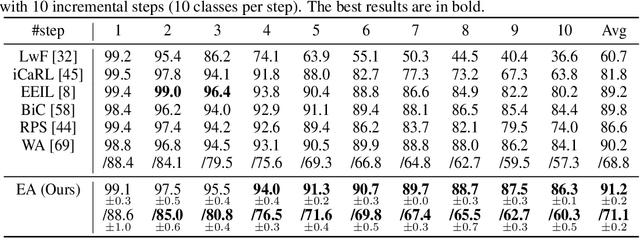
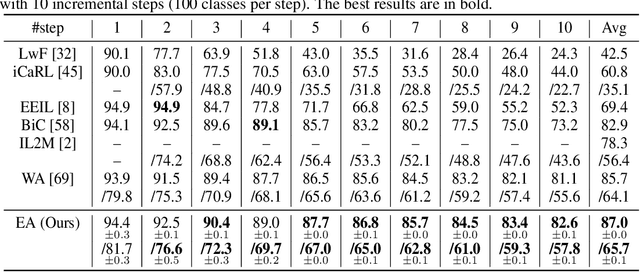
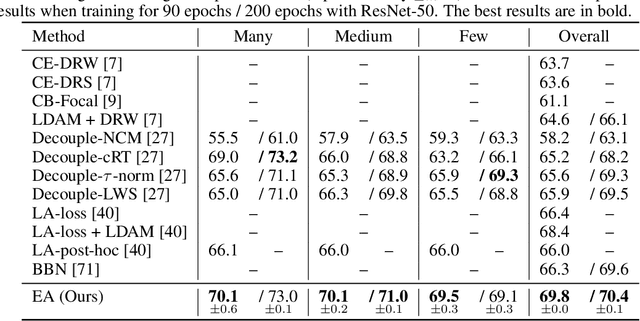
Training on class-imbalanced data usually results in biased models that tend to predict samples into the majority classes, which is a common and notorious problem. From the perspective of energy-based model, we demonstrate that the free energies of categories are aligned with the label distribution theoretically, thus the energies of different classes are expected to be close to each other when aiming for ``balanced'' performance. However, we discover a severe energy-bias phenomenon in the models trained on class-imbalanced dataset. To eliminate the bias, we propose a simple and effective method named Energy Aligning by merely adding the calculated shift scalars onto the output logits during inference, which does not require to (i) modify the network architectures, (ii) intervene the standard learning paradigm, (iii) perform two-stage training. The proposed algorithm is evaluated on two class imbalance-related tasks under various settings: class incremental learning and long-tailed recognition. Experimental results show that energy aligning can effectively alleviate class imbalance issue and outperform state-of-the-art methods on several benchmarks.
Stacked Acoustic-and-Textual Encoding: Integrating the Pre-trained Models into Speech Translation Encoders
May 12, 2021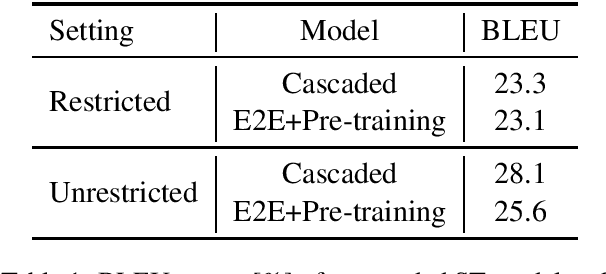
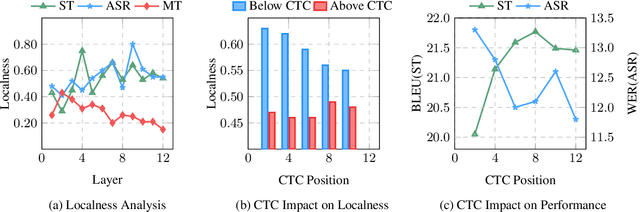
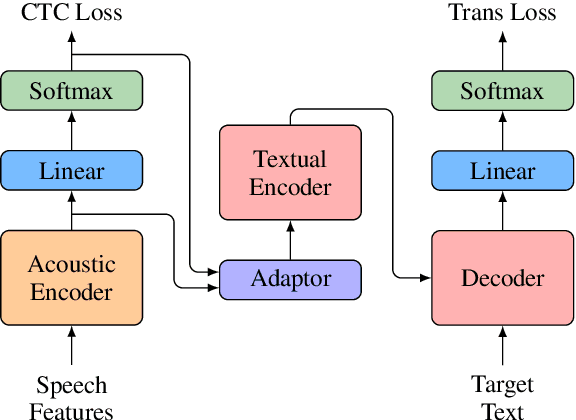
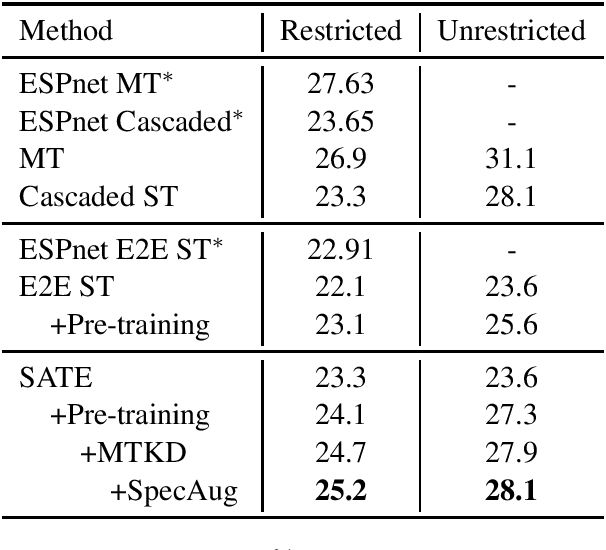
Encoder pre-training is promising in end-to-end Speech Translation (ST), given the fact that speech-to-translation data is scarce. But ST encoders are not simple instances of Automatic Speech Recognition (ASR) or Machine Translation (MT) encoders. For example, we find ASR encoders lack the global context representation, which is necessary for translation, whereas MT encoders are not designed to deal with long but locally attentive acoustic sequences. In this work, we propose a Stacked Acoustic-and-Textual Encoding (SATE) method for speech translation. Our encoder begins with processing the acoustic sequence as usual, but later behaves more like an MT encoder for a global representation of the input sequence. In this way, it is straightforward to incorporate the pre-trained models into the system. Also, we develop an adaptor module to alleviate the representation inconsistency between the pre-trained ASR encoder and MT encoder, and a multi-teacher knowledge distillation method to preserve the pre-training knowledge. Experimental results on the LibriSpeech En-Fr and MuST-C En-De show that our method achieves the state-of-the-art performance of 18.3 and 25.2 BLEU points. To our knowledge, we are the first to develop an end-to-end ST system that achieves comparable or even better BLEU performance than the cascaded ST counterpart when large-scale ASR and MT data is available.
Towards A Category-extended Object Detector without Relabeling or Conflicts
Dec 28, 2020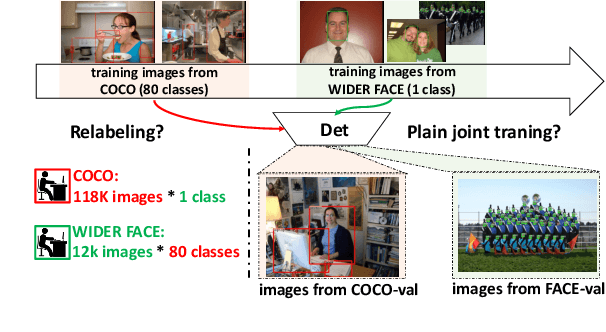

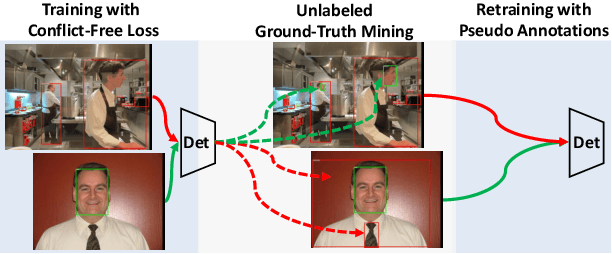
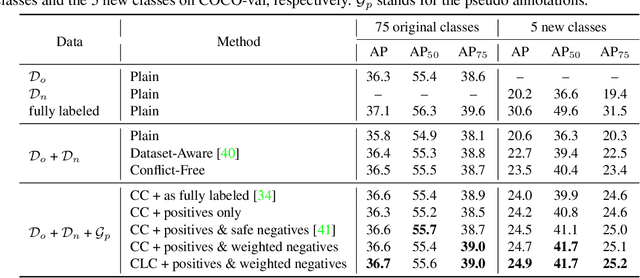
Object detectors are typically learned based on fully-annotated training data with fixed pre-defined categories. However, not all possible categories of interest can be known beforehand, as classes are often required to be increased progressively in many realistic applications. In such scenario, only the original training set annotated with the old classes and some new training data labeled with the new classes are available. In this paper, we aim at leaning a strong unified detector that can handle all categories based on the limited datasets without extra manual labor. Vanilla joint training without considering label ambiguity leads to heavy biases and poor performance due to the incomplete annotations. To avoid such situation, we propose a practical framework which focuses on three aspects: better base model, better unlabeled ground-truth mining strategy and better retraining method with pseudo annotations. First, a conflict-free loss is proposed to obtain a usable base detector. Second, we employ Monte Carlo Dropout to calculate the localization confidence, combined with the classification confidence, to mine more accurate bounding boxes. Third, we explore several strategies for making better use of pseudo annotations during retraining to achieve more powerful detectors. Extensive experiments conducted on multiple datasets demonstrate the effectiveness of our framework for category-extended object detectors.