 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Low-level Representations for Ultra-Fast Road Segmentation
Feb 06, 2024



Achieving real-time and accuracy on embedded platforms has always been the pursuit of road segmentation methods. To this end, they have proposed many lightweight networks. However, they ignore the fact that roads are "stuff" (background or environmental elements) rather than "things" (specific identifiable objects), which inspires us to explore the feasibility of representing roads with low-level instead of high-level features. Surprisingly, we find that the primary stage of mainstream network models is sufficient to represent most pixels of the road for segmentation. Motivated by this, we propose a Low-level Feature Dominated Road Segmentation network (LFD-RoadSeg). Specifically, LFD-RoadSeg employs a bilateral structure. The spatial detail branch is firstly designed to extract low-level feature representation for the road by the first stage of ResNet-18. To suppress texture-less regions mistaken as the road in the low-level feature, the context semantic branch is then designed to extract the context feature in a fast manner. To this end, in the second branch, we asymmetrically downsample the input image and design an aggregation module to achieve comparable receptive fields to the third stage of ResNet-18 but with less time consumption. Finally, to segment the road from the low-level feature, a selective fusion module is proposed to calculate pixel-wise attention between the low-level representation and context feature, and suppress the non-road low-level response by this attention. On KITTI-Road, LFD-RoadSeg achieves a maximum F1-measure (MaxF) of 95.21% and an average precision of 93.71%, while reaching 238 FPS on a single TITAN Xp and 54 FPS on a Jetson TX2, all with a compact model size of just 936k parameters. The source code is available at https://github.com/zhouhuan-hust/LFD-RoadSeg.
Fully Self-Supervised Learning for Semantic Segmentation
Feb 24, 2022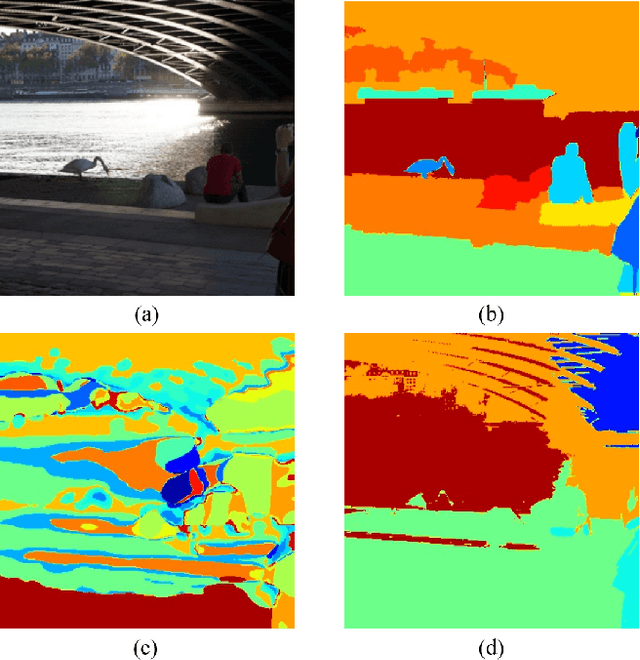
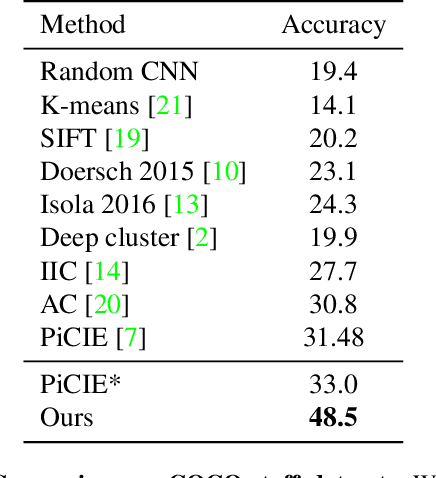
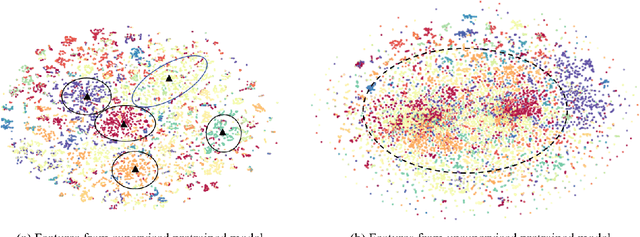
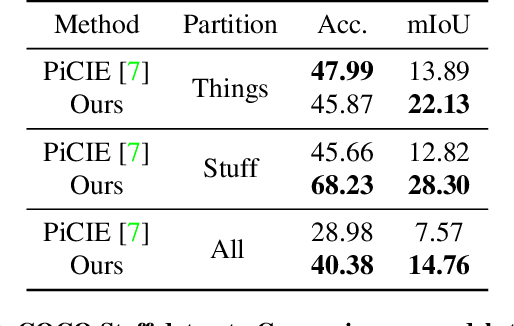
In this work, we present a fully self-supervised framework for semantic segmentation(FS^4). A fully bootstrapped strategy for semantic segmentation, which saves efforts for the huge amount of annotation, is crucial for building customized models from end-to-end for open-world domains. This application is eagerly needed in realistic scenarios. Even though recent self-supervised semantic segmentation methods have gained great progress, these works however heavily depend on the fully-supervised pretrained model and make it impossible a fully self-supervised pipeline. To solve this problem, we proposed a bootstrapped training scheme for semantic segmentation, which fully leveraged the global semantic knowledge for self-supervision with our proposed PGG strategy and CAE module. In particular, we perform pixel clustering and assignments for segmentation supervision. Preventing it from clustering a mess, we proposed 1) a pyramid-global-guided (PGG) training strategy to supervise the learning with pyramid image/patch-level pseudo labels, which are generated by grouping the unsupervised features. The stable global and pyramid semantic pseudo labels can prevent the segmentation from learning too many clutter regions or degrading to one background region; 2) in addition, we proposed context-aware embedding (CAE) module to generate global feature embedding in view of its neighbors close both in space and appearance in a non-trivial way. We evaluate our method on the large-scale COCO-Stuff dataset and achieved 7.19 mIoU improvements on both things and stuff objects
Maximize the Exploration of Congeneric Semantics for Weakly Supervised Semantic Segmentation
Oct 08, 2021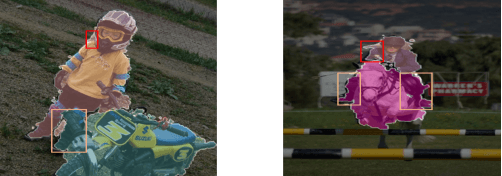

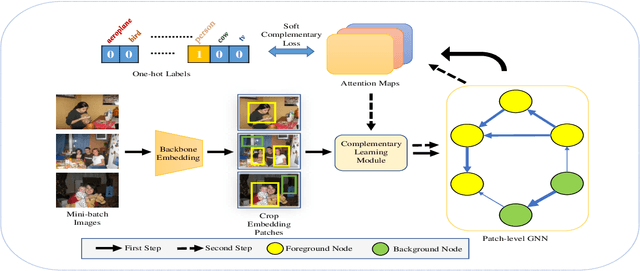
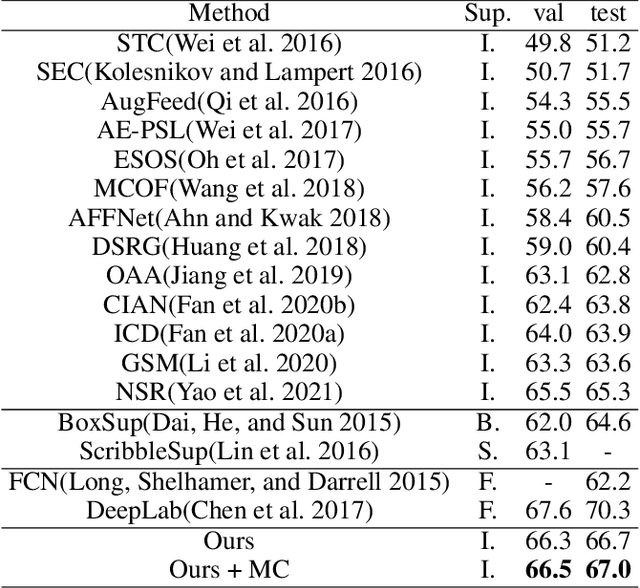
With the increase in the number of image data and the lack of corresponding labels, weakly supervised learning has drawn a lot of attention recently in computer vision tasks, especially in the fine-grained semantic segmentation problem. To alleviate human efforts from expensive pixel-by-pixel annotations, our method focuses on weakly supervised semantic segmentation (WSSS) with image-level tags, which are much easier to obtain. As a huge gap exists between pixel-level segmentation and image-level labels, how to reflect the image-level semantic information on each pixel is an important question. To explore the congeneric semantic regions from the same class to the maximum, we construct the patch-level graph neural network (P-GNN) based on the self-detected patches from different images that contain the same class labels. Patches can frame the objects as much as possible and include as little background as possible. The graph network that is established with patches as the nodes can maximize the mutual learning of similar objects. We regard the embedding vectors of patches as nodes, and use transformer-based complementary learning module to construct weighted edges according to the embedding similarity between different nodes. Moreover, to better supplement semantic information, we propose soft-complementary loss functions matched with the whole network structure. We conduct experiments on the popular PASCAL VOC 2012 benchmarks, and our model yields state-of-the-art performance.