 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-body Motion Control of an Omnidirectional Wheel-Legged Mobile Manipulator via Contact-Aware Dynamic Optimization
Sep 17, 2025Wheel-legged robots with integrated manipulators hold great promise for mobile manipulation in logistics, industrial automation, and human-robot collaboration. However, unified control of such systems remains challenging due to the redundancy in degrees of freedom, complex wheel-ground contact dynamics, and the need for seamless coordination between locomotion and manipulation. In this work, we present the design and whole-body motion control of an omnidirectional wheel-legged quadrupedal robot equipped with a dexterous manipulator. The proposed platform incorporates independently actuated steering modules and hub-driven wheels, enabling agile omnidirectional locomotion with high maneuverability in structured environments. To address the challenges of contact-rich interaction, we develop a contact-aware whole-body dynamic optimization framework that integrates point-contact modeling for manipulation with line-contact modeling for wheel-ground interactions. A warm-start strategy is introduced to accelerate online optimization, ensuring real-time feasibility for high-dimensional control. Furthermore, a unified kinematic model tailored for the robot's 4WIS-4WID actuation scheme eliminates the need for mode switching across different locomotion strategies, improving control consistency and robustness. Simulation and experimental results validate the effectiveness of the proposed framework, demonstrating agile terrain traversal, high-speed omnidirectional mobility, and precise manipulation under diverse scenarios, underscoring the system's potential for factory automation, urban logistics, and service robotics in semi-structured environments.
Spatiotemporal Prediction of Secondary Crashes by Rebalancing Dynamic and Static Data with Generative Adversarial Networks
Jan 17, 2025



Data imbalance is a common issue in analyzing and predicting sudden traffic events. Secondary crashes constitute only a small proportion of all crashes. These secondary crashes, triggered by primary crashes, significantly exacerbate traffic congestion and increase the severity of incidents. However, the severe imbalance of secondary crash data poses significant challenges for prediction models, affecting their generalization ability and prediction accuracy. Existing methods fail to fully address the complexity of traffic crash data, particularly the coexistence of dynamic and static features, and often struggle to effectively handle data samples of varying lengths. Furthermore, most current studies predict the occurrence probability and spatiotemporal distribution of secondary crashes separately, lacking an integrated solution. To address these challenges, this study proposes a hybrid model named VarFusiGAN-Transformer, aimed at improving the fidelity of secondary crash data generation and jointly predicting the occurrence and spatiotemporal distribution of secondary crashes. The VarFusiGAN-Transformer model employs Long Short-Term Memory (LSTM) networks to enhance the generation of multivariate long-time series data, incorporating a static data generator and an auxiliary discriminator to model the joint distribution of dynamic and static features. In addition, the model's prediction module achieves simultaneous prediction of both the occurrence and spatiotemporal distribution of secondary crashes. Compared to existing methods, the proposed model demonstrates superior performance in generating high-fidelity data and improving prediction accuracy.
Traj-Explainer: An Explainable and Robust Multi-modal Trajectory Prediction Approach
Oct 22, 2024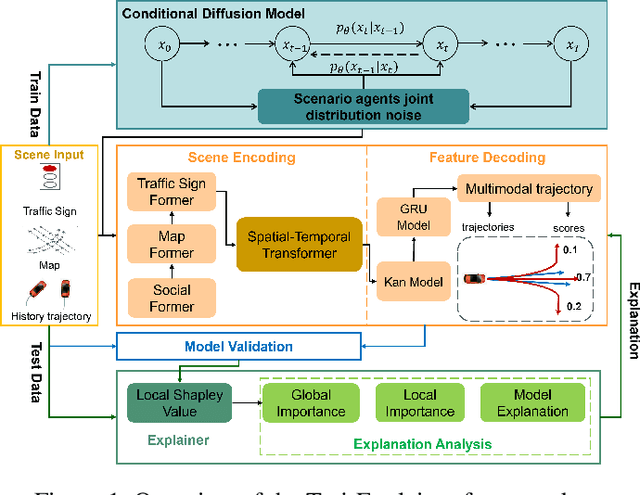
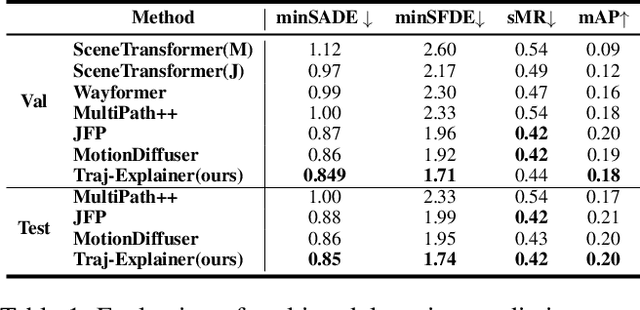

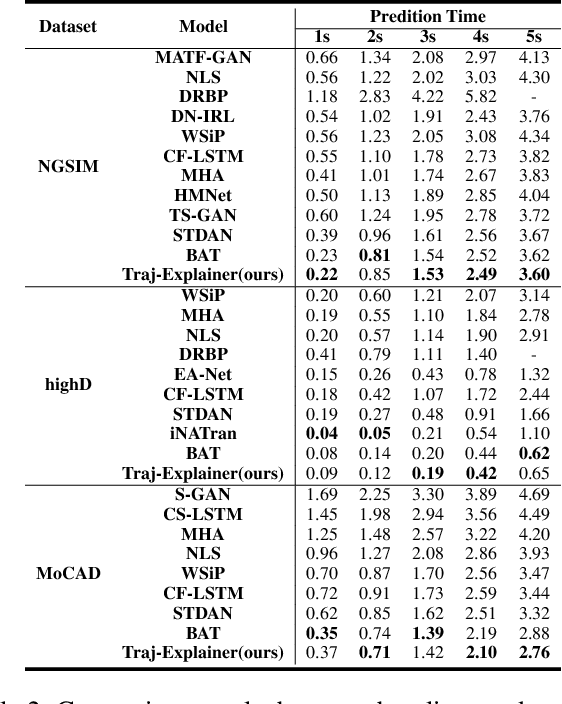
Navigating complex traffic environments has been significantly enhanced by advancements in intelligent technologies, enabling accurate environment perception and trajectory prediction for automated vehicles. However, existing research often neglects the consideration of the joint reasoning of scenario agents and lacks interpretability in trajectory prediction models, thereby limiting their practical application in real-world scenarios. To this purpose, an explainability-oriented trajectory prediction model is designed in this work, named Explainable Conditional Diffusion based Multimodal Trajectory Prediction Traj-Explainer, to retrieve the influencing factors of prediction and help understand the intrinsic mechanism of prediction. In Traj-Explainer, a modified conditional diffusion is well designed to capture the scenario multimodal trajectory pattern, and meanwhile, a modified Shapley Value model is assembled to rationally learn the importance of the global and scenario features. Numerical experiments are carried out by several trajectory prediction datasets, including Waymo, NGSIM, HighD, and MoCAD datasets. Furthermore, we evaluate the identified input factors which indicates that they are in agreement with the human driving experience, indicating the capability of the proposed model in appropriately learning the prediction. Code available in our open-source repository: \url{https://anonymous.4open.science/r/Interpretable-Prediction}.
Kaninfradet3D:A Road-side Camera-LiDAR Fusion 3D Perception Model based on Nonlinear Feature Extraction and Intrinsic Correlation
Oct 21, 2024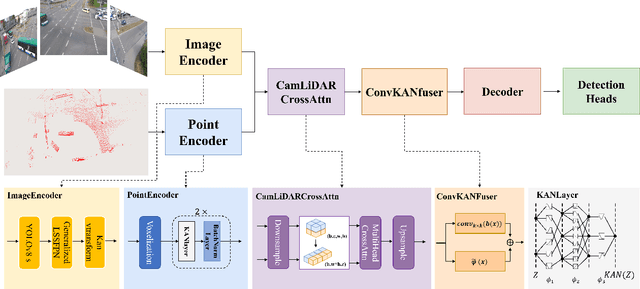


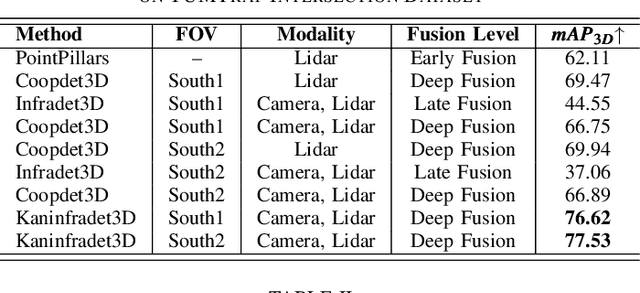
With the development of AI-assisted driving, numerous methods have emerged for ego-vehicle 3D perception tasks, but there has been limited research on roadside perception. With its ability to provide a global view and a broader sensing range, the roadside perspective is worth developing. LiDAR provides precise three-dimensional spatial information, while cameras offer semantic information. These two modalities are complementary in 3D detection. However, adding camera data does not increase accuracy in some studies since the information extraction and fusion procedure is not sufficiently reliable. Recently, Kolmogorov-Arnold Networks (KANs) have been proposed as replacements for MLPs, which are better suited for high-dimensional, complex data. Both the camera and the LiDAR provide high-dimensional information, and employing KANs should enhance the extraction of valuable features to produce better fusion outcomes. This paper proposes Kaninfradet3D, which optimizes the feature extraction and fusion modules. To extract features from complex high-dimensional data, the model's encoder and fuser modules were improved using KAN Layers. Cross-attention was applied to enhance feature fusion, and visual comparisons verified that camera features were more evenly integrated. This addressed the issue of camera features being abnormally concentrated, negatively impacting fusion. Compared to the benchmark, our approach shows improvements of +9.87 mAP and +10.64 mAP in the two viewpoints of the TUMTraf Intersection Dataset and an improvement of +1.40 mAP in the roadside end of the TUMTraf V2X Cooperative Perception Dataset. The results indicate that Kaninfradet3D can effectively fuse features, demonstrating the potential of applying KANs in roadside perception tasks.
Optimal Multilayered Motion Planning for Multiple Differential Drive Mobile Robots with Hierarchical Prioritization (OM-MP)
May 11, 2024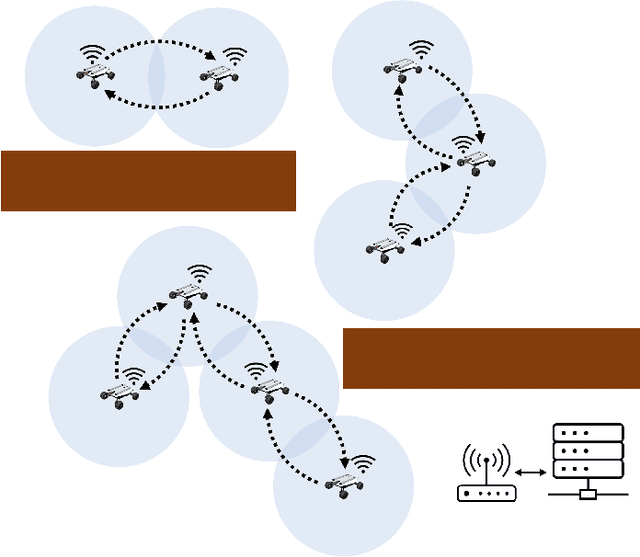
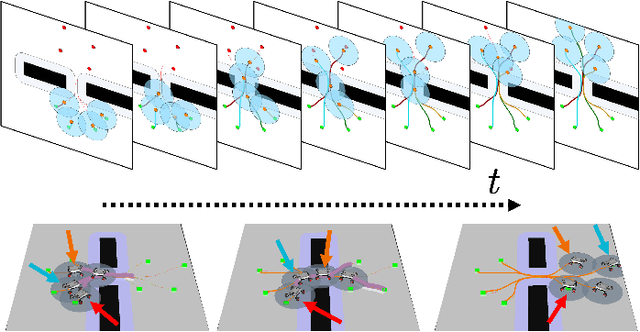
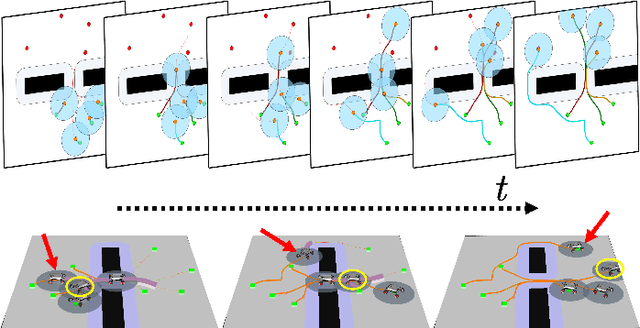
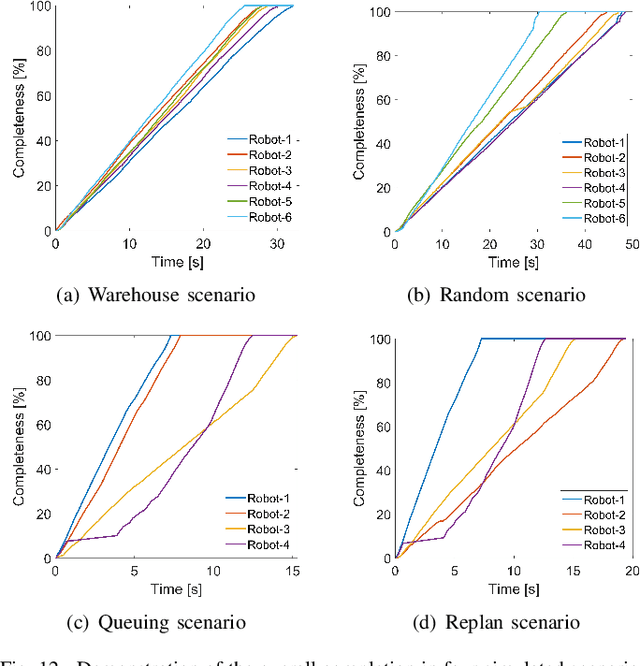
We present a novel framework for addressing the challenges of multi-Agent planning and formation control within intricate and dynamic environments. This framework transforms the Multi-Agent Path Finding (MAPF) problem into a Multi-Agent Trajectory Planning (MATP) problem. Unlike traditional MAPF solutions, our multilayer optimization scheme consists of a global planner optimization solver, which is dedicated to determining concise global paths for each individual robot, and a local planner with an embedded optimization solver aimed at ensuring the feasibility of local robot trajectories. By implementing a hierarchical prioritization strategy, we enhance robots' efficiency and approximate the global optimal solution. Specifically, within the global planner, we employ the Augmented Graph Search (AGS) algorithm, which significantly improves the speed of solutions. Meanwhile, within the local planner optimization solver, we utilize Control Barrier functions (CBFs) and introduced an oblique cylindrical obstacle bounding box based on the time axis for obstacle avoidance and construct a single-robot locally aware-communication circle to ensure the simplicity, speed, and accuracy of locally optimized solutions. Additionally, we integrate the weight and priority of path traces to prevent deadlocks in limiting scenarios. Compared to the other state-of-the-art methods, including CBS, ECBS and other derivative algorithms, our proposed method demonstrates superior performance in terms of capacity, flexible scalability and overall task optimality in theory, as validated through simulations and experiments.
FDSPC: Fast and Direct Smooth Path Planning via Continuous Curvature Integration
May 06, 2024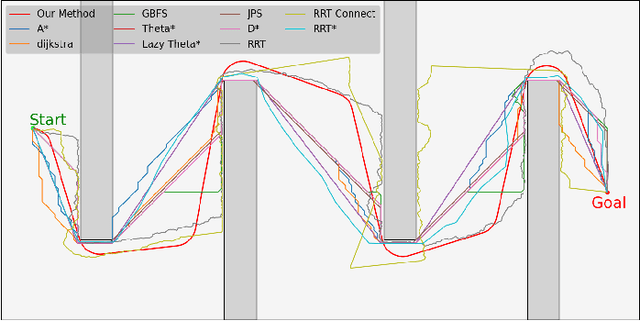
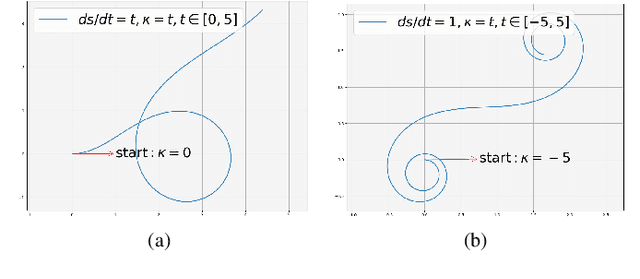
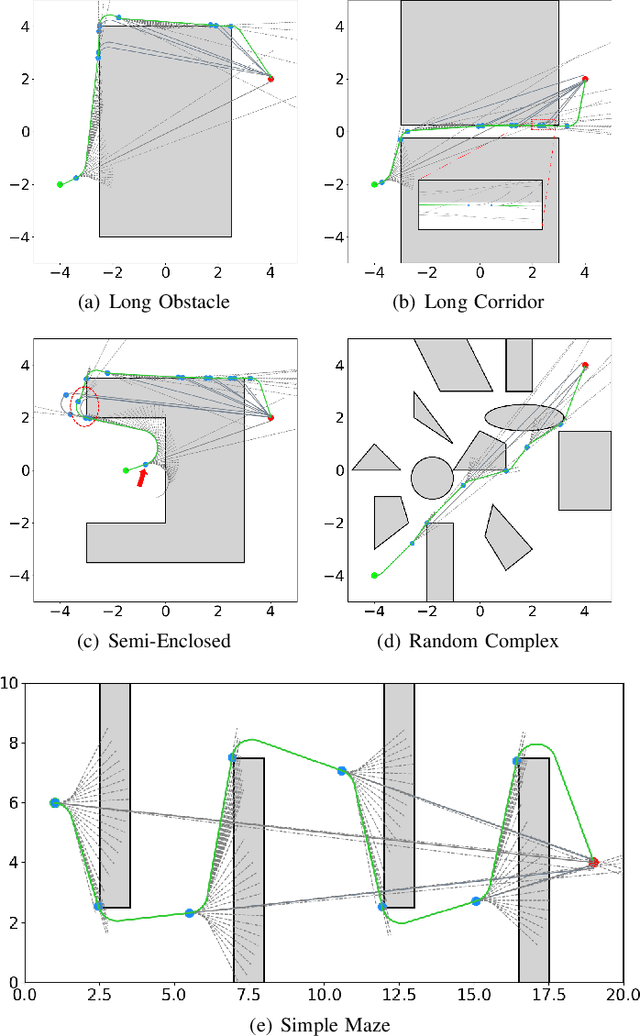
In recent decades, global path planning of robot has seen significant advancements. Both heuristic search-based methods and probability sampling-based methods have shown capabilities to find feasible solutions in complex scenarios. However, mainstream global path planning algorithms often produce paths with bends, requiring additional smoothing post-processing. In this work, we propose a fast and direct path planning method based on continuous curvature integration. This method ensures path feasibility while directly generating global smooth paths with constant velocity, thus eliminating the need for post-path-smoothing. Furthermore, we compare the proposed method with existing approaches in terms of solution time, path length, memory usage, and smoothness under multiple scenarios. The proposed method is vastly superior to the average performance of state-of-the-art (SOTA) methods, especially in terms of the self-defined $\mathcal{S}_2 $ smoothness (mean angle of steering). These results demonstrate the effectiveness and superiority of our approach in several representative environments.
PEVA-Net: Prompt-Enhanced View Aggregation Network for Zero/Few-Shot Multi-View 3D Shape Recognition
Apr 30, 2024



Large vision-language models have impressively promote the performance of 2D visual recognition under zero/few-shot scenarios. In this paper, we focus on exploiting the large vision-language model, i.e., CLIP, to address zero/few-shot 3D shape recognition based on multi-view representations. The key challenge for both tasks is to generate a discriminative descriptor of the 3D shape represented by multiple view images under the scenarios of either without explicit training (zero-shot 3D shape recognition) or training with a limited number of data (few-shot 3D shape recognition). We analyze that both tasks are relevant and can be considered simultaneously. Specifically, leveraging the descriptor which is effective for zero-shot inference to guide the tuning of the aggregated descriptor under the few-shot training can significantly improve the few-shot learning efficacy. Hence, we propose Prompt-Enhanced View Aggregation Network (PEVA-Net) to simultaneously address zero/few-shot 3D shape recognition. Under the zero-shot scenario, we propose to leverage the prompts built up from candidate categories to enhance the aggregation process of multiple view-associated visual features. The resulting aggregated feature serves for effective zero-shot recognition of the 3D shapes. Under the few-shot scenario, we first exploit a transformer encoder to aggregate the view-associated visual features into a global descriptor. To tune the encoder, together with the main classification loss, we propose a self-distillation scheme via a feature distillation loss by treating the zero-shot descriptor as the guidance signal for the few-shot descriptor. This scheme can significantly enhance the few-shot learning efficacy.
Exploiting Low-level Representations for Ultra-Fast Road Segmentation
Feb 06, 2024



Achieving real-time and accuracy on embedded platforms has always been the pursuit of road segmentation methods. To this end, they have proposed many lightweight networks. However, they ignore the fact that roads are "stuff" (background or environmental elements) rather than "things" (specific identifiable objects), which inspires us to explore the feasibility of representing roads with low-level instead of high-level features. Surprisingly, we find that the primary stage of mainstream network models is sufficient to represent most pixels of the road for segmentation. Motivated by this, we propose a Low-level Feature Dominated Road Segmentation network (LFD-RoadSeg). Specifically, LFD-RoadSeg employs a bilateral structure. The spatial detail branch is firstly designed to extract low-level feature representation for the road by the first stage of ResNet-18. To suppress texture-less regions mistaken as the road in the low-level feature, the context semantic branch is then designed to extract the context feature in a fast manner. To this end, in the second branch, we asymmetrically downsample the input image and design an aggregation module to achieve comparable receptive fields to the third stage of ResNet-18 but with less time consumption. Finally, to segment the road from the low-level feature, a selective fusion module is proposed to calculate pixel-wise attention between the low-level representation and context feature, and suppress the non-road low-level response by this attention. On KITTI-Road, LFD-RoadSeg achieves a maximum F1-measure (MaxF) of 95.21% and an average precision of 93.71%, while reaching 238 FPS on a single TITAN Xp and 54 FPS on a Jetson TX2, all with a compact model size of just 936k parameters. The source code is available at https://github.com/zhouhuan-hust/LFD-RoadSeg.
Fast Safe Rectangular Corridor-based Online AGV Trajectory Optimization with Obstacle Avoidance
Sep 14, 2023



Automated Guided Vehicles (AGVs) are widely adopted in various industries due to their efficiency and adaptability. However, safely deploying AGVs in dynamic environments remains a significant challenge. This paper introduces an online trajectory optimization framework, the Fast Safe Rectangular Corridor (FSRC), designed for AGVs in obstacle-rich settings. The primary challenge is efficiently planning trajectories that prioritize safety and collision avoidance. To tackle this challenge, the FSRC algorithm constructs convex regions, represented as rectangular corridors, to address obstacle avoidance constraints within an optimal control problem. This conversion from non-convex to box constraints improves the collision avoidance efficiency and quality. Additionally, the Modified Visibility Graph algorithm speeds up path planning, and a boundary discretization strategy expedites FSRC construction. The framework also includes a dynamic obstacle avoidance strategy for real-time adaptability. Our framework's effectiveness and superiority have been demonstrated in experiments, particularly in computational efficiency (see Fig. \ref{fig:case1} and \ref{fig:case23}). Compared to state-of-the-art frameworks, our trajectory planning framework significantly enhances computational efficiency, ranging from 1 to 2 orders of magnitude (see Table \ref{tab:res}). Notably, the FSRC algorithm outperforms other safe convex corridor-based methods, substantially improving computational efficiency by 1 to 2 orders of magnitude (see Table \ref{tab:FRSC}).
SCA-PVNet: Self-and-Cross Attention Based Aggregation of Point Cloud and Multi-View for 3D Object Retrieval
Jul 20, 2023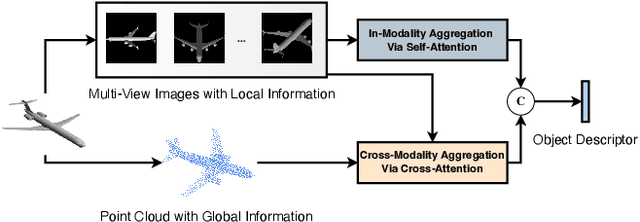
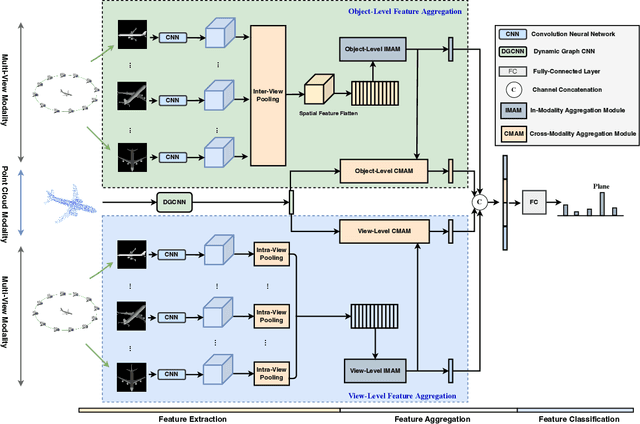
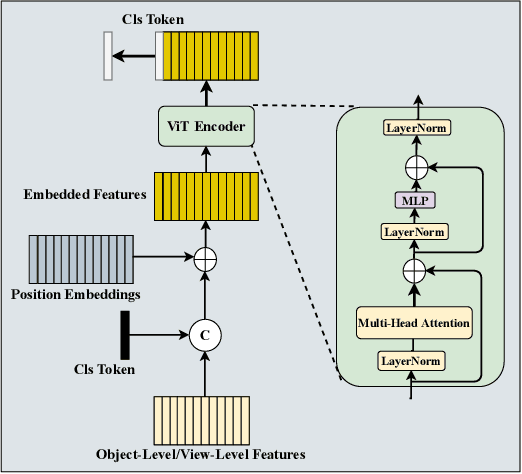
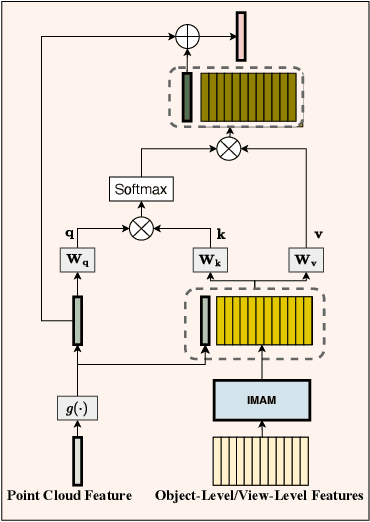
To address 3D object retrieval, substantial efforts have been made to generate highly discriminative descriptors of 3D objects represented by a single modality, e.g., voxels, point clouds or multi-view images. It is promising to leverage the complementary information from multi-modality representations of 3D objects to further improve retrieval performance. However, multi-modality 3D object retrieval is rarely developed and analyzed on large-scale datasets. In this paper, we propose self-and-cross attention based aggregation of point cloud and multi-view images (SCA-PVNet) for 3D object retrieval. With deep features extracted from point clouds and multi-view images, we design two types of feature aggregation modules, namely the In-Modality Aggregation Module (IMAM) and the Cross-Modality Aggregation Module (CMAM), for effective feature fusion. IMAM leverages a self-attention mechanism to aggregate multi-view features while CMAM exploits a cross-attention mechanism to interact point cloud features with multi-view features. The final descriptor of a 3D object for object retrieval can be obtained via concatenating the aggregated features from both modules. Extensive experiments and analysis are conducted on three datasets, ranging from small to large scale, to show the superiority of the proposed SCA-PVNet over the state-of-the-art methods.