 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEVA-Net: Prompt-Enhanced View Aggregation Network for Zero/Few-Shot Multi-View 3D Shape Recognition
Apr 30, 2024



Large vision-language models have impressively promote the performance of 2D visual recognition under zero/few-shot scenarios. In this paper, we focus on exploiting the large vision-language model, i.e., CLIP, to address zero/few-shot 3D shape recognition based on multi-view representations. The key challenge for both tasks is to generate a discriminative descriptor of the 3D shape represented by multiple view images under the scenarios of either without explicit training (zero-shot 3D shape recognition) or training with a limited number of data (few-shot 3D shape recognition). We analyze that both tasks are relevant and can be considered simultaneously. Specifically, leveraging the descriptor which is effective for zero-shot inference to guide the tuning of the aggregated descriptor under the few-shot training can significantly improve the few-shot learning efficacy. Hence, we propose Prompt-Enhanced View Aggregation Network (PEVA-Net) to simultaneously address zero/few-shot 3D shape recognition. Under the zero-shot scenario, we propose to leverage the prompts built up from candidate categories to enhance the aggregation process of multiple view-associated visual features. The resulting aggregated feature serves for effective zero-shot recognition of the 3D shapes. Under the few-shot scenario, we first exploit a transformer encoder to aggregate the view-associated visual features into a global descriptor. To tune the encoder, together with the main classification loss, we propose a self-distillation scheme via a feature distillation loss by treating the zero-shot descriptor as the guidance signal for the few-shot descriptor. This scheme can significantly enhance the few-shot learning efficacy.
SCA-PVNet: Self-and-Cross Attention Based Aggregation of Point Cloud and Multi-View for 3D Object Retrieval
Jul 20, 2023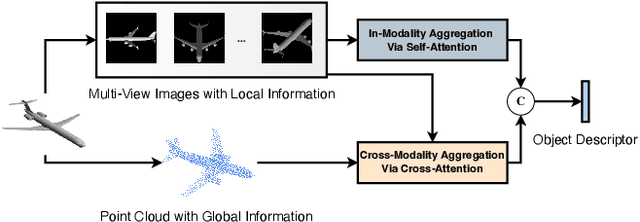
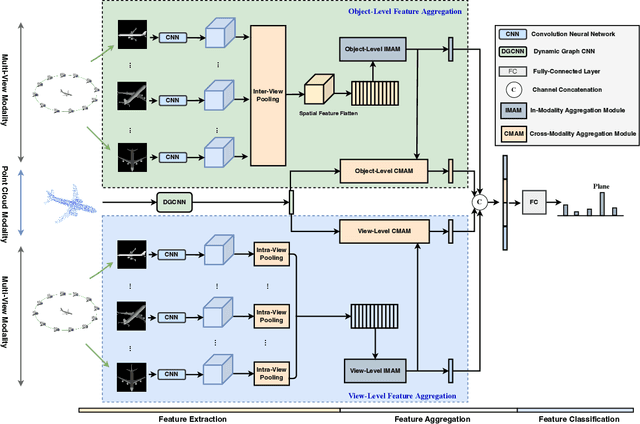
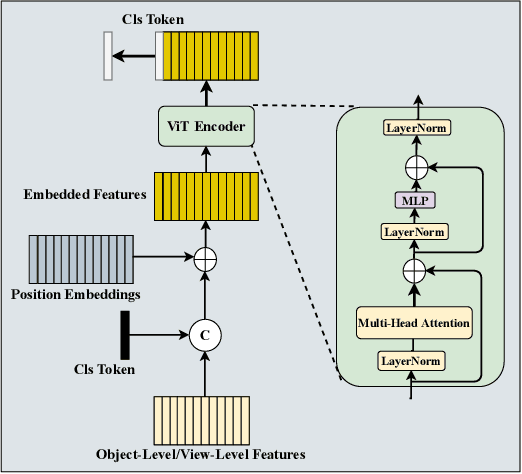
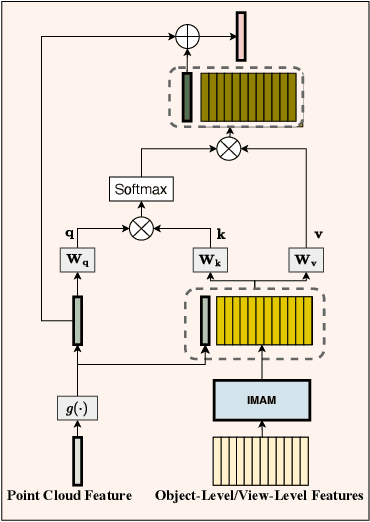
To address 3D object retrieval, substantial efforts have been made to generate highly discriminative descriptors of 3D objects represented by a single modality, e.g., voxels, point clouds or multi-view images. It is promising to leverage the complementary information from multi-modality representations of 3D objects to further improve retrieval performance. However, multi-modality 3D object retrieval is rarely developed and analyzed on large-scale datasets. In this paper, we propose self-and-cross attention based aggregation of point cloud and multi-view images (SCA-PVNet) for 3D object retrieval. With deep features extracted from point clouds and multi-view images, we design two types of feature aggregation modules, namely the In-Modality Aggregation Module (IMAM) and the Cross-Modality Aggregation Module (CMAM), for effective feature fusion. IMAM leverages a self-attention mechanism to aggregate multi-view features while CMAM exploits a cross-attention mechanism to interact point cloud features with multi-view features. The final descriptor of a 3D object for object retrieval can be obtained via concatenating the aggregated features from both modules. Extensive experiments and analysis are conducted on three datasets, ranging from small to large scale, to show the superiority of the proposed SCA-PVNet over the state-of-the-art methods.