 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Intent Gap: Knowledge-Enhanced Visual Generation
May 21, 2024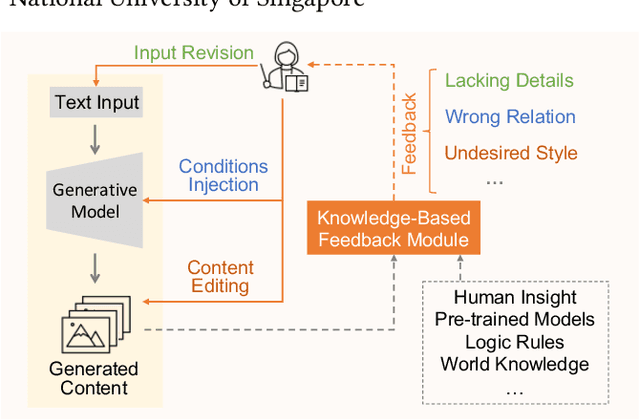
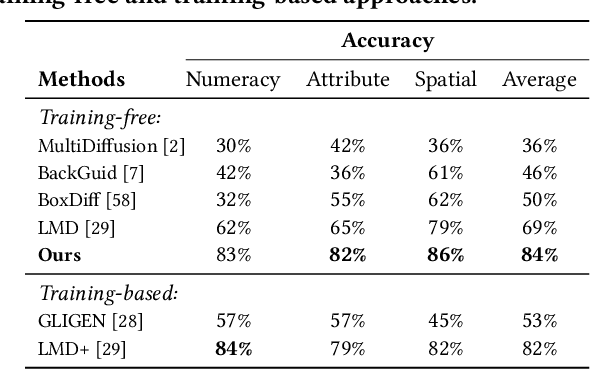
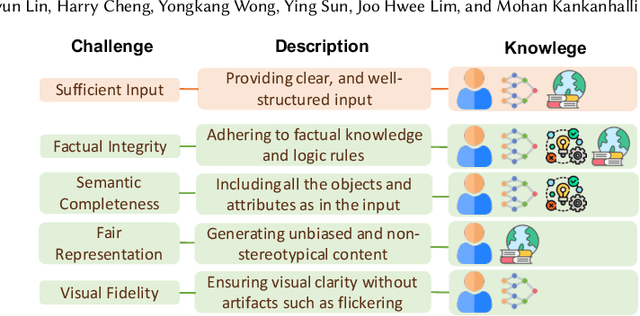
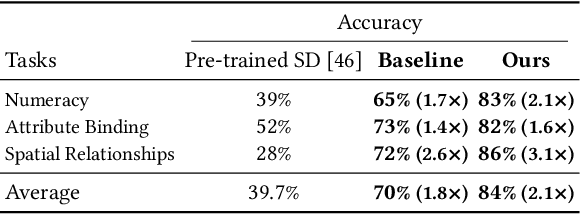
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
PEVA-Net: Prompt-Enhanced View Aggregation Network for Zero/Few-Shot Multi-View 3D Shape Recognition
Apr 30, 2024



Large vision-language models have impressively promote the performance of 2D visual recognition under zero/few-shot scenarios. In this paper, we focus on exploiting the large vision-language model, i.e., CLIP, to address zero/few-shot 3D shape recognition based on multi-view representations. The key challenge for both tasks is to generate a discriminative descriptor of the 3D shape represented by multiple view images under the scenarios of either without explicit training (zero-shot 3D shape recognition) or training with a limited number of data (few-shot 3D shape recognition). We analyze that both tasks are relevant and can be considered simultaneously. Specifically, leveraging the descriptor which is effective for zero-shot inference to guide the tuning of the aggregated descriptor under the few-shot training can significantly improve the few-shot learning efficacy. Hence, we propose Prompt-Enhanced View Aggregation Network (PEVA-Net) to simultaneously address zero/few-shot 3D shape recognition. Under the zero-shot scenario, we propose to leverage the prompts built up from candidate categories to enhance the aggregation process of multiple view-associated visual features. The resulting aggregated feature serves for effective zero-shot recognition of the 3D shapes. Under the few-shot scenario, we first exploit a transformer encoder to aggregate the view-associated visual features into a global descriptor. To tune the encoder, together with the main classification loss, we propose a self-distillation scheme via a feature distillation loss by treating the zero-shot descriptor as the guidance signal for the few-shot descriptor. This scheme can significantly enhance the few-shot learning efficacy.
Keyword-Aware Relative Spatio-Temporal Graph Networks for Video Question Answering
Jul 25, 2023



The main challenge in video question answering (VideoQA) is to capture and understand the complex spatial and temporal relations between objects based on given questions. Existing graph-based methods for VideoQA usually ignore keywords in questions and employ a simple graph to aggregate features without considering relative relations between objects, which may lead to inferior performance. In this paper, we propose a Keyword-aware Relative Spatio-Temporal (KRST) graph network for VideoQA. First, to make question features aware of keywords, we employ an attention mechanism to assign high weights to keywords during question encoding. The keyword-aware question features are then used to guide video graph construction. Second, because relations are relative, we integrate the relative relation modeling to better capture the spatio-temporal dynamics among object nodes. Moreover, we disentangle the spatio-temporal reasoning into an object-level spatial graph and a frame-level temporal graph, which reduces the impact of spatial and temporal relation reasoning on each other. Extensive experiments on the TGIF-QA, MSVD-QA and MSRVTT-QA datasets demonstrate the superiority of our KRST over multiple state-of-the-art methods.
SCA-PVNet: Self-and-Cross Attention Based Aggregation of Point Cloud and Multi-View for 3D Object Retrieval
Jul 20, 2023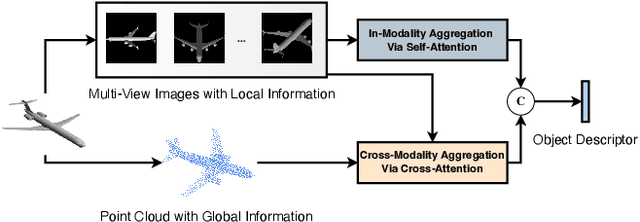
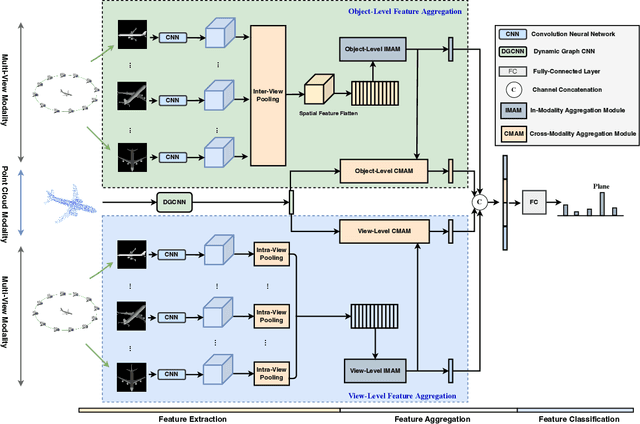
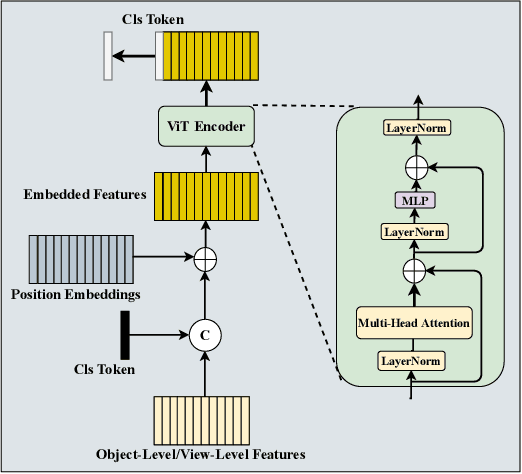
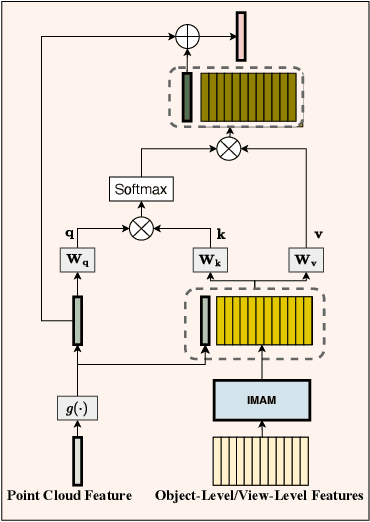
To address 3D object retrieval, substantial efforts have been made to generate highly discriminative descriptors of 3D objects represented by a single modality, e.g., voxels, point clouds or multi-view images. It is promising to leverage the complementary information from multi-modality representations of 3D objects to further improve retrieval performance. However, multi-modality 3D object retrieval is rarely developed and analyzed on large-scale datasets. In this paper, we propose self-and-cross attention based aggregation of point cloud and multi-view images (SCA-PVNet) for 3D object retrieval. With deep features extracted from point clouds and multi-view images, we design two types of feature aggregation modules, namely the In-Modality Aggregation Module (IMAM) and the Cross-Modality Aggregation Module (CMAM), for effective feature fusion. IMAM leverages a self-attention mechanism to aggregate multi-view features while CMAM exploits a cross-attention mechanism to interact point cloud features with multi-view features. The final descriptor of a 3D object for object retrieval can be obtained via concatenating the aggregated features from both modules. Extensive experiments and analysis are conducted on three datasets, ranging from small to large scale, to show the superiority of the proposed SCA-PVNet over the state-of-the-art methods.
A Study on Differentiable Logic and LLMs for EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2023
Jul 13, 2023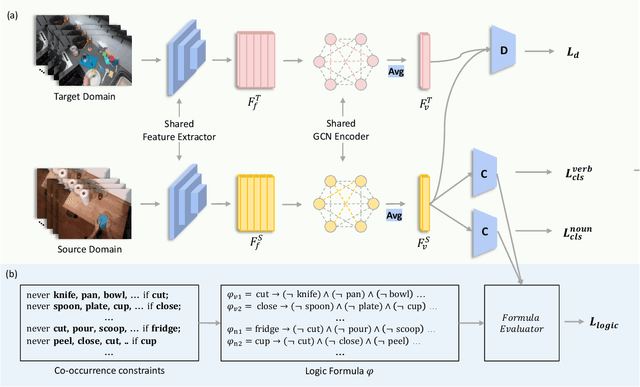
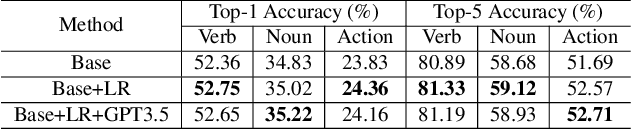
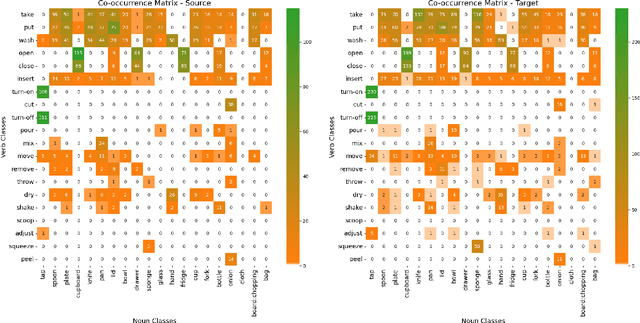

In this technical report, we present our findings from a study conducted on the EPIC-KITCHENS-100 Unsupervised Domain Adaptation task for Action Recognition. Our research focuses on the innovative application of a differentiable logic loss in the training to leverage the co-occurrence relations between verb and noun, as well as the pre-trained Large Language Models (LLMs) to generate the logic rules for the adaptation to unseen action labels. Specifically, the model's predictions are treated as the truth assignment of a co-occurrence logic formula to compute the logic loss, which measures the consistency between the predictions and the logic constraints. By using the verb-noun co-occurrence matrix generated from the dataset, we observe a moderate improvement in model performance compared to our baseline framework. To further enhance the model's adaptability to novel action labels, we experiment with rules generated using GPT-3.5, which leads to a slight decrease in performance. These findings shed light on the potential and challenges of incorporating differentiable logic and LLMs for knowledge extraction in unsupervised domain adaptation for action recognition. Our final submission (entitled `NS-LLM') achieved the first place in terms of top-1 action recognition accuracy.
Team VI-I2R Technical Report on EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2022
Jan 29, 2023



In this report, we present the technical details of our submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation (UDA) Challenge for Action Recognition 2022. This task aims to adapt an action recognition model trained on a labeled source domain to an unlabeled target domain. To achieve this goal, we propose an action-aware domain adaptation framework that leverages the prior knowledge induced from the action recognition task during the adaptation. Specifically, we disentangle the source features into action-relevant features and action-irrelevant features using the learned action classifier and then align the target features with the action-relevant features. To further improve the action prediction performance, we exploit the verb-noun co-occurrence matrix to constrain and refine the action predictions. Our final submission achieved the first place in terms of top-1 action recognition accuracy.
Few-Shot Defect Segmentation Leveraging Abundant Normal Training Samples Through Normal Background Regularization and Crop-and-Paste Operation
Jul 18, 2020

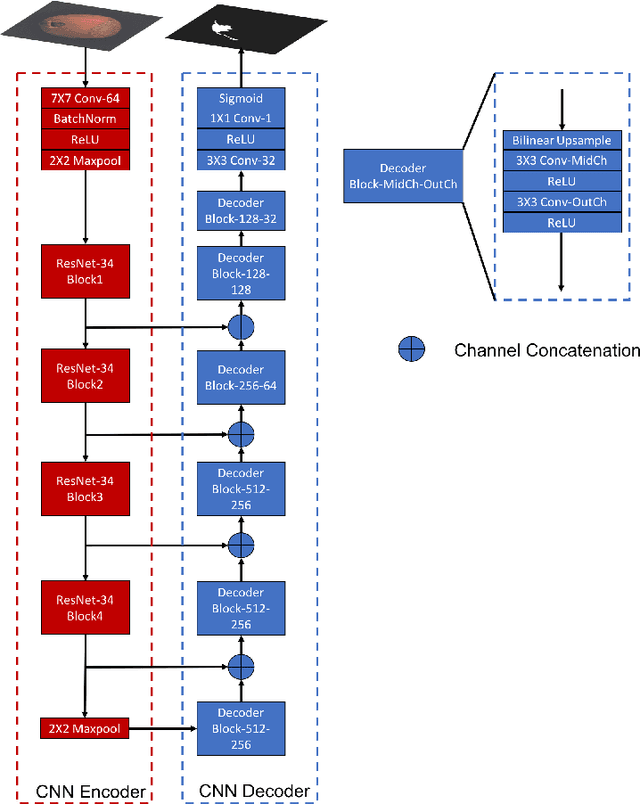
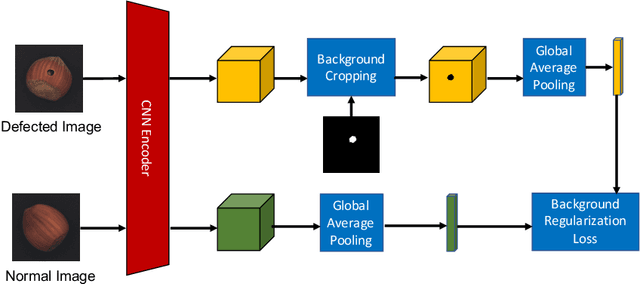
In industrial product quality assessment, it is essential to determine whether a product is defect-free and further analyze the severity of anomality. To this end, accurate defect segmentation on images of products provides an important functionality. In industrial inspection tasks, it is common to capture abundant defect-free image samples but very limited anomalous ones. Therefore, it is critical to develop automatic and accurate defect segmentation systems using only a small number of annotated anomalous training images. This paper tackles the challenging few-shot defect segmentation task with sufficient normal (defect-free) training images but very few anomalous ones. We present two effective regularization techniques via incorporating abundant defect-free images into the training of a UNet-like encoder-decoder defect segmentation network. We first propose a Normal Background Regularization (NBR) loss which is jointly minimized with the segmentation loss, enhancing the encoder network to produce distinctive representations for normal regions. Secondly, we crop/paste defective regions to the randomly selected normal images for data augmentation and propose a weighted binary cross-entropy loss to enhance the training by emphasizing more realistic crop-and-pasted augmented images based on feature-level similarity comparison. Both techniques are implemented on an encoder-decoder segmentation network backboned by ResNet-34 for few-shot defect segmentation. Extensive experiments are conducted on the recently released MVTec Anomaly Detection dataset with high-resolution industrial images. Under both 1-shot and 5-shot defect segmentation settings, the proposed method significantly outperforms several benchmarking methods.
DDR-ID: Dual Deep Reconstruction Networks Based Image Decomposition for Anomaly Detection
Jul 18, 2020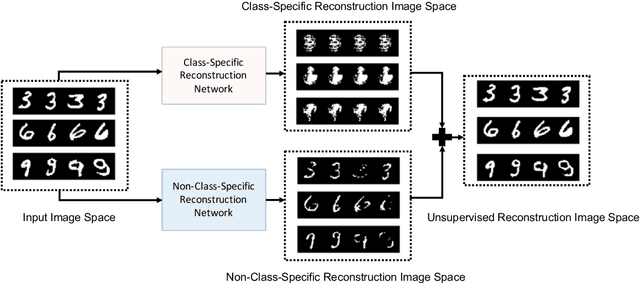
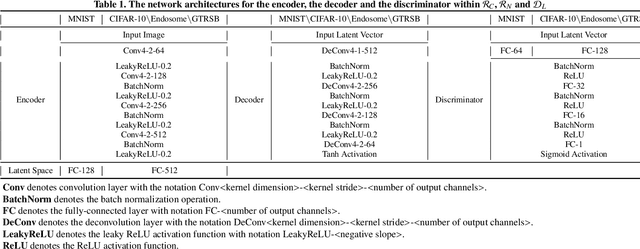
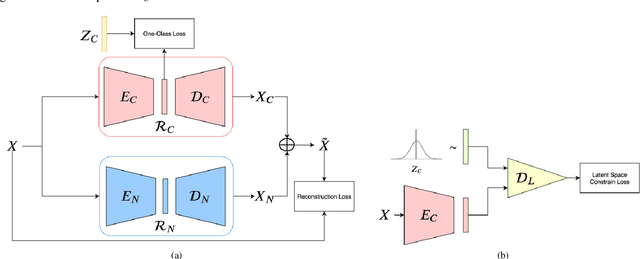
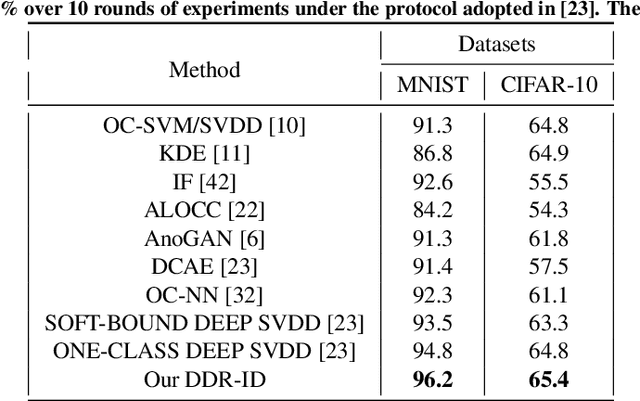
One pivot challenge for image anomaly (AD) detection is to learn discriminative information only from normal class training images. Most image reconstruction based AD methods rely on the discriminative capability of reconstruction error. This is heuristic as image reconstruction is unsupervised without incorporating normal-class-specific information. In this paper, we propose an AD method called dual deep reconstruction networks based image decomposition (DDR-ID). The networks are trained by jointly optimizing for three losses: the one-class loss, the latent space constrain loss and the reconstruction loss. After training, DDR-ID can decompose an unseen image into its normal class and the residual components, respectively. Two anomaly scores are calculated to quantify the anomalous degree of the image in either normal class latent space or reconstruction image space. Thereby, anomaly detection can be performed via thresholding the anomaly score. The experiments demonstrate that DDR-ID outperforms multiple related benchmarking methods in image anomaly detection using MNIST, CIFAR-10 and Endosome datasets and adversarial attack detection using GTSRB dataset.