 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Hand Grasp Generation for HOI and Efficient Evaluation Methods
Jan 27, 2025Controllable affordance Hand-Object Interaction (HOI) generation has become an increasingly important area of research in computer vision. In HOI generation, the hand grasp generation is a crucial step for effectively controlling the geometry of the hand. Current hand grasp generation methods rely on 3D information for both the hand and the object. In addition, these methods lack controllability concerning the hand's location and orientation. We treat the hand pose as the discrete graph structure and exploit the geometric priors. It is well established that higher order contextual dependency among the points improves the quality of the results in general. We propose a framework of higher order geometric representations (HOR's) inspired by spectral graph theory and vector algebra to improve the quality of generated hand poses. We demonstrate the effectiveness of our proposed HOR's in devising a controllable novel diffusion method (based on 2D information) for hand grasp generation that outperforms the state of the art (SOTA). Overcoming the limitations of existing methods: like lacking of controllability and dependency on 3D information. Once we have the generated pose, it is very natural to evaluate them using a metric. Popular metrics like FID and MMD are biased and inefficient for evaluating the generated hand poses. Using our proposed HOR's, we introduce an efficient and stable framework of evaluation metrics for grasp generation methods, addressing inefficiencies and biases in FID and MMD.
Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
May 21, 2024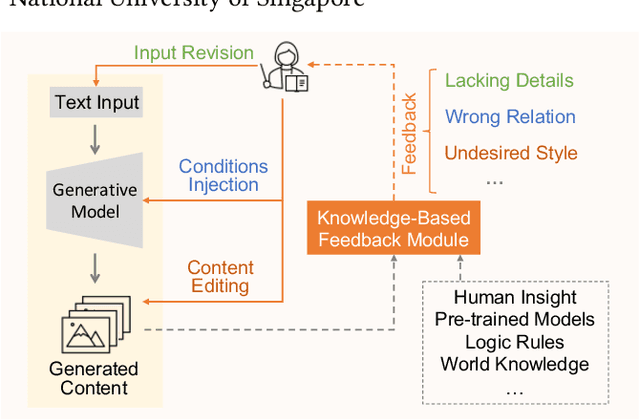
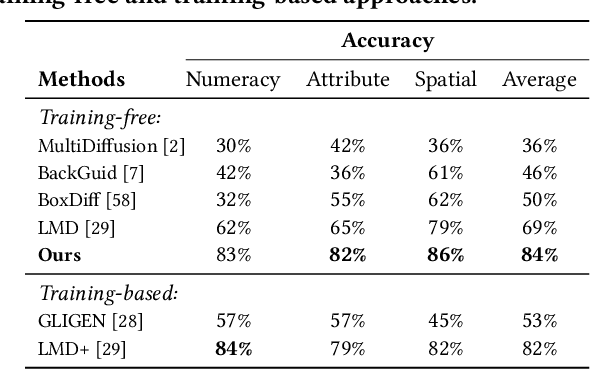
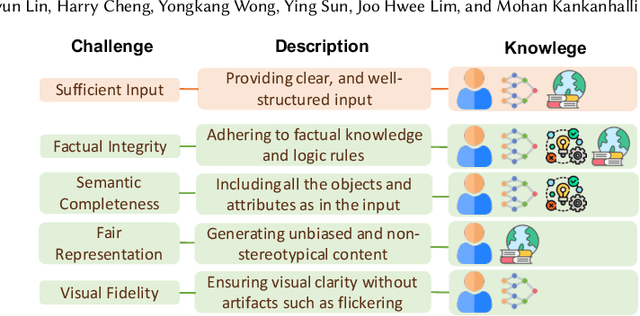
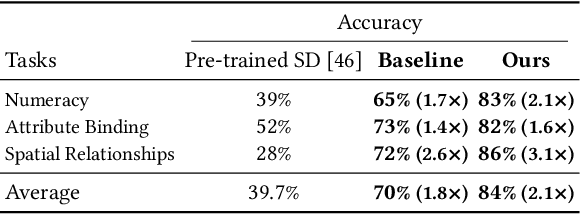
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
Towards Debiasing Frame Length Bias in Text-Video Retrieval via Causal Intervention
Sep 17, 2023



Many studies focus on improving pretraining or developing new backbones in text-video retrieval. However, existing methods may suffer from the learning and inference bias issue, as recent research suggests in other text-video-related tasks. For instance, spatial appearance features on action recognition or temporal object co-occurrences on video scene graph generation could induce spurious correlations. In this work, we present a unique and systematic study of a temporal bias due to frame length discrepancy between training and test sets of trimmed video clips, which is the first such attempt for a text-video retrieval task, to the best of our knowledge. We first hypothesise and verify the bias on how it would affect the model illustrated with a baseline study. Then, we propose a causal debiasing approach and perform extensive experiments and ablation studies on the Epic-Kitchens-100, YouCook2, and MSR-VTT datasets. Our model overpasses the baseline and SOTA on nDCG, a semantic-relevancy-focused evaluation metric which proves the bias is mitigated, as well as on the other conventional metrics.
An Overview of Challenges in Egocentric Text-Video Retrieval
Jun 07, 2023
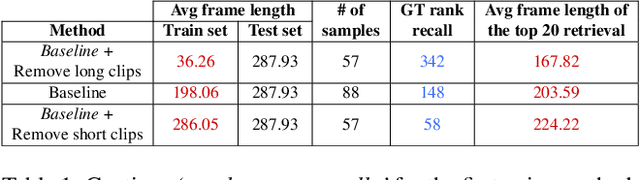

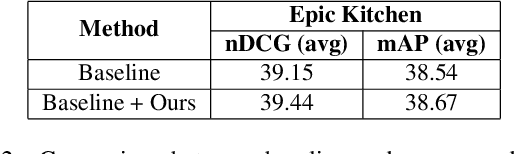
Text-video retrieval contains various challenges, including biases coming from diverse sources. We highlight some of them supported by illustrations to open a discussion. Besides, we address one of the biases, frame length bias, with a simple method which brings a very incremental but promising increase. We conclude with future directions.
Is Bio-Inspired Learning Better than Backprop? Benchmarking Bio Learning vs. Backprop
Dec 09, 2022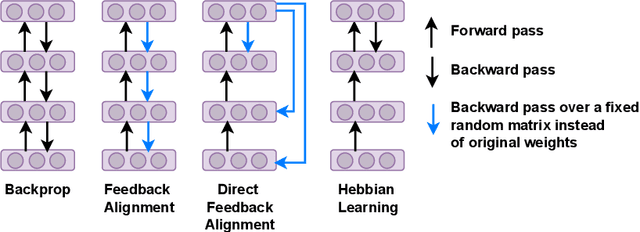
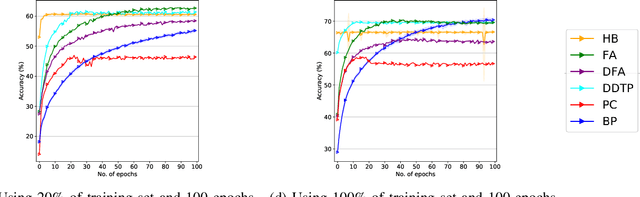
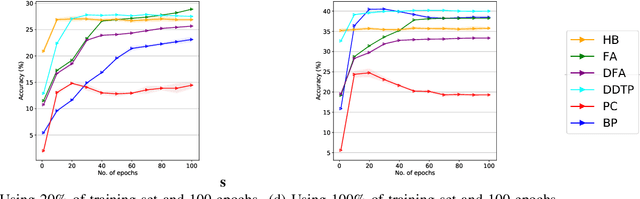
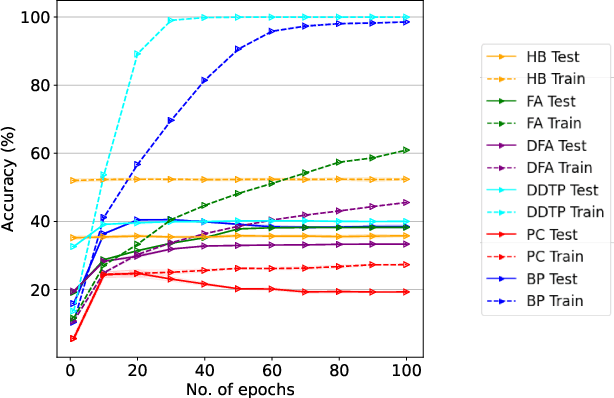
Bio-inspired learning has been gaining popularity recently given that Backpropagation (BP) is not considered biologically plausible. Many algorithms have been proposed in the literature which are all more biologically plausible than BP. However, apart from overcoming the biological implausibility of BP, a strong motivation for using Bio-inspired algorithms remains lacking. In this study, we undertake a holistic comparison of BP vs. multiple Bio-inspired algorithms to answer the question of whether Bio-learning offers additional benefits over BP, rather than just biological plausibility. We test Bio-algorithms under different design choices such as access to only partial training data, resource constraints in terms of the number of training epochs, sparsification of the neural network parameters and addition of noise to input samples. Through these experiments, we notably find two key advantages of Bio-algorithms over BP. Firstly, Bio-algorithms perform much better than BP when the entire training dataset is not supplied. Four of the five Bio-algorithms tested outperform BP by upto 5% accuracy when only 20% of the training dataset is available. Secondly, even when the full dataset is available, Bio-algorithms learn much quicker and converge to a stable accuracy in far lesser training epochs than BP. Hebbian learning, specifically, is able to learn in just 5 epochs compared to around 100 epochs required by BP. These insights present practical reasons for utilising Bio-learning rather than just its biological plausibility and also point towards interesting new directions for future work on Bio-learning.
On the Robustness, Generalization, and Forgetting of Shape-Texture Debiased Continual Learning
Nov 26, 2022Tremendous progress has been made in continual learning to maintain good performance on old tasks when learning new tasks by tackling the catastrophic forgetting problem of neural networks. This paper advances continual learning by further considering its out-of-distribution robustness, in response to the vulnerability of continually trained models to distribution shifts (e.g., due to data corruptions and domain shifts) in inference. To this end, we propose shape-texture debiased continual learning. The key idea is to learn generalizable and robust representations for each task with shape-texture debiased training. In order to transform standard continual learning to shape-texture debiased continual learning, we propose shape-texture debiased data generation and online shape-texture debiased self-distillation. Experiments on six datasets demonstrate the benefits of our approach in improving generalization and robustness, as well as reducing forgetting. Our analysis on the flatness of the loss landscape explains the advantages. Moreover, our approach can be easily combined with new advanced architectures such as vision transformer, and applied to more challenging scenarios such as exemplar-free continual learning.
Reason from Context with Self-supervised Learning
Nov 23, 2022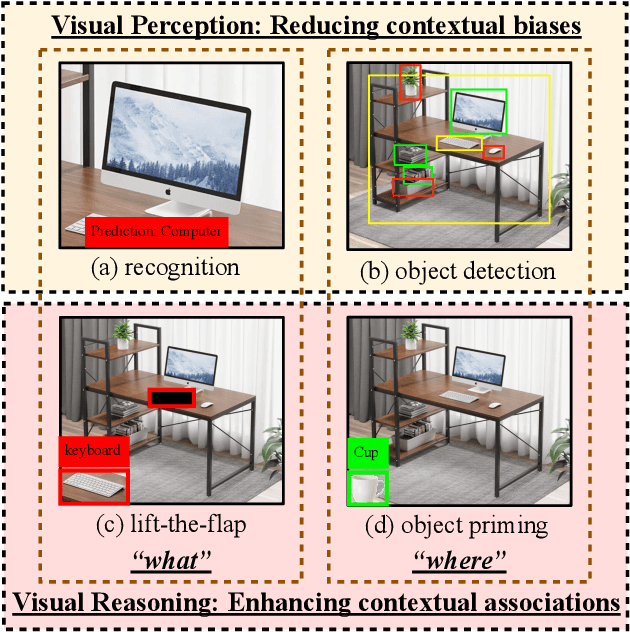
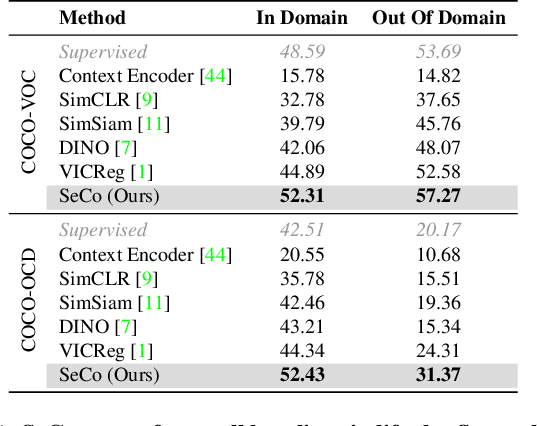
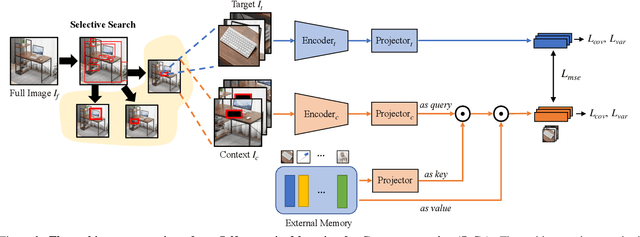
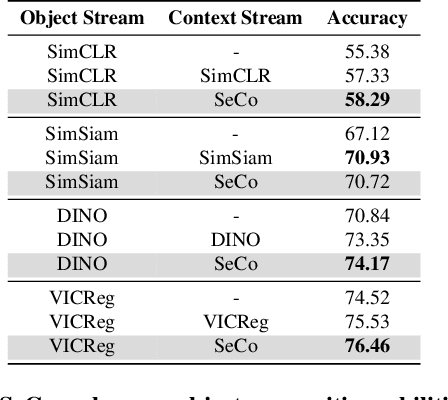
A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.
Portmanteauing Features for Scene Text Recognition
Nov 09, 2022



Scene text images have different shapes and are subjected to various distortions, e.g. perspective distortions. To handle these challenges, the state-of-the-art methods rely on a rectification network, which is connected to the text recognition network. They form a linear pipeline which uses text rectification on all input images, even for images that can be recognized without it. Undoubtedly, the rectification network improves the overall text recognition performance. However, in some cases, the rectification network generates unnecessary distortions on images, resulting in incorrect predictions in images that would have otherwise been correct without it. In order to alleviate the unnecessary distortions, the portmanteauing of features is proposed. The portmanteau feature, inspired by the portmanteau word, is a feature containing information from both the original text image and the rectified image. To generate the portmanteau feature, a non-linear input pipeline with a block matrix initialization is presented. In this work, the transformer is chosen as the recognition network due to its utilization of attention and inherent parallelism, which can effectively handle the portmanteau feature. The proposed method is examined on 6 benchmarks and compared with 13 state-of-the-art methods. The experimental results show that the proposed method outperforms the state-of-the-art methods on various of the benchmarks.
Combined CNN Transformer Encoder for Enhanced Fine-grained Human Action Recognition
Aug 03, 2022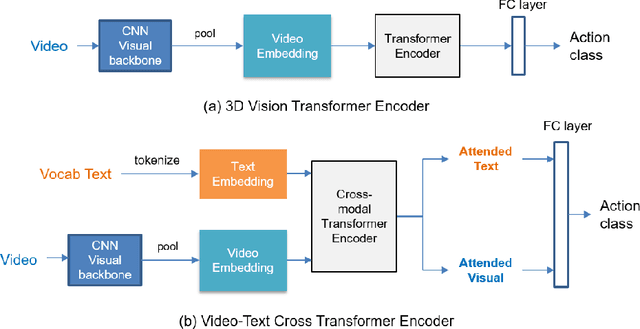

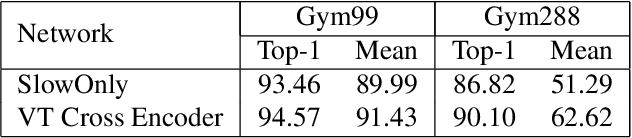
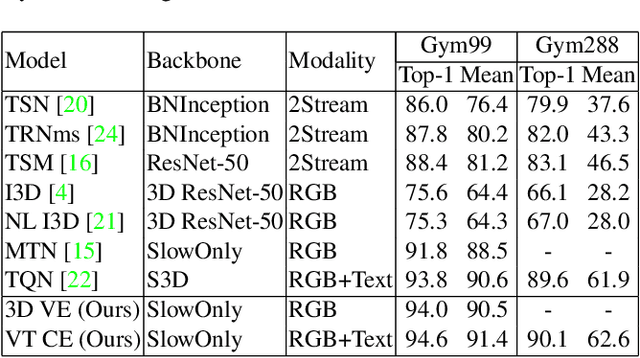
Fine-grained action recognition is a challenging task in computer vision. As fine-grained datasets have small inter-class variations in spatial and temporal space, fine-grained action recognition model requires good temporal reasoning and discrimination of attribute action semantics. Leveraging on CNN's ability in capturing high level spatial-temporal feature representations and Transformer's modeling efficiency in capturing latent semantics and global dependencies, we investigate two frameworks that combine CNN vision backbone and Transformer Encoder to enhance fine-grained action recognition: 1) a vision-based encoder to learn latent temporal semantics, and 2) a multi-modal video-text cross encoder to exploit additional text input and learn cross association between visual and text semantics. Our experimental results show that both our Transformer encoder frameworks effectively learn latent temporal semantics and cross-modality association, with improved recognition performance over CNN vision model. We achieve new state-of-the-art performance on the FineGym benchmark dataset for both proposed architectures.
Exploiting Semantic Role Contextualized Video Features for Multi-Instance Text-Video Retrieval EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jun 29, 2022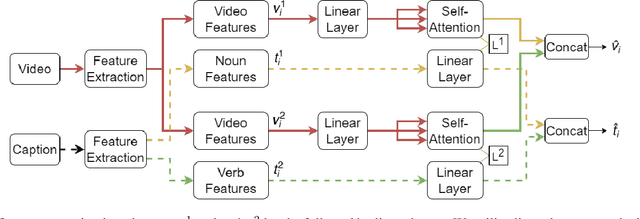
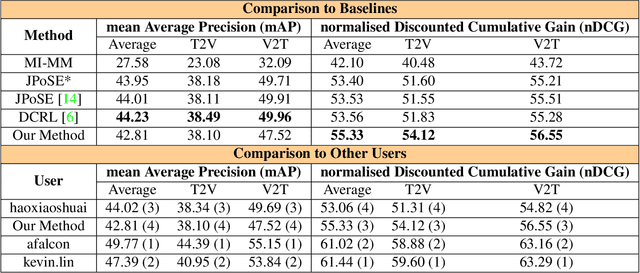
In this report, we present our approach for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022. We first parse sentences into semantic roles corresponding to verbs and nouns; then utilize self-attentions to exploit semantic role contextualized video features along with textual features via triplet losses in multiple embedding spaces. Our method overpasses the strong baseline in normalized Discounted Cumulative Gain (nDCG), which is more valuable for semantic similarity. Our submission is ranked 3rd for nDCG and ranked 4th for mAP.