 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason from Context with Self-supervised Learning
Paper and Code
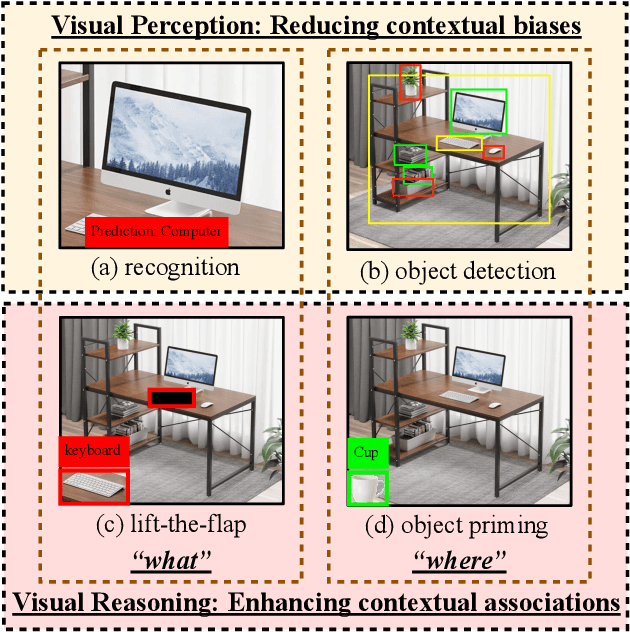
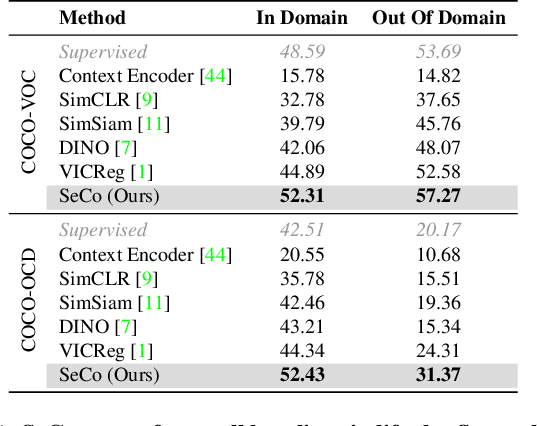
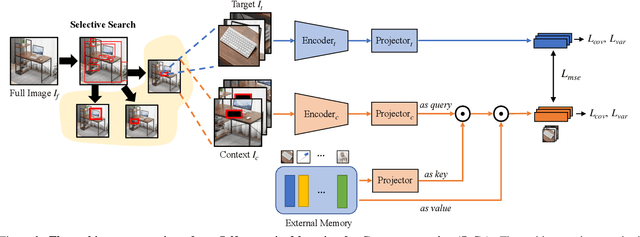
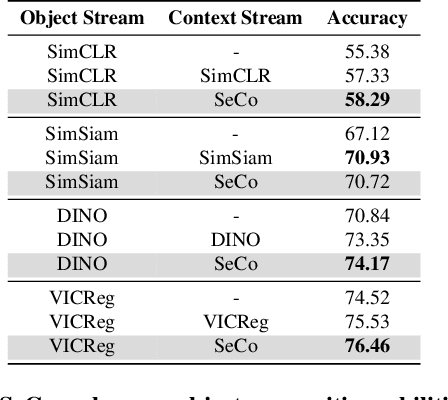
A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.