 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
Oct 02, 2025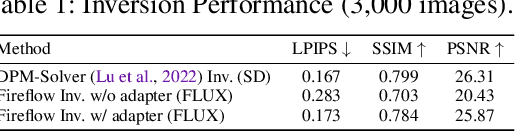
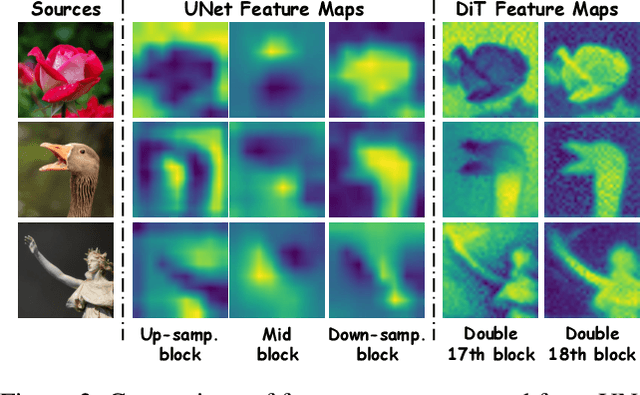
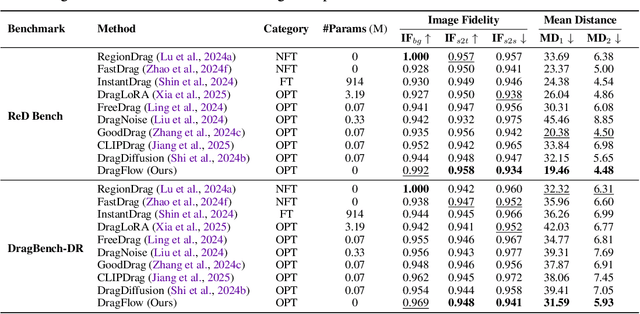
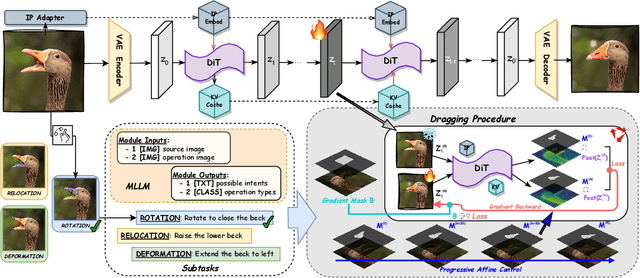
Drag-based image editing has long suffered from distortions in the target region, largely because the priors of earlier base models, Stable Diffusion, are insufficient to project optimized latents back onto the natural image manifold. With the shift from UNet-based DDPMs to more scalable DiT with flow matching (e.g., SD3.5, FLUX), generative priors have become significantly stronger, enabling advances across diverse editing tasks. However, drag-based editing has yet to benefit from these stronger priors. This work proposes the first framework to effectively harness FLUX's rich prior for drag-based editing, dubbed DragFlow, achieving substantial gains over baselines. We first show that directly applying point-based drag editing to DiTs performs poorly: unlike the highly compressed features of UNets, DiT features are insufficiently structured to provide reliable guidance for point-wise motion supervision. To overcome this limitation, DragFlow introduces a region-based editing paradigm, where affine transformations enable richer and more consistent feature supervision. Additionally, we integrate pretrained open-domain personalization adapters (e.g., IP-Adapter) to enhance subject consistency, while preserving background fidelity through gradient mask-based hard constraints. Multimodal large language models (MLLMs) are further employed to resolve task ambiguities. For evaluation, we curate a novel Region-based Dragging benchmark (ReD Bench) featuring region-level dragging instructions. Extensive experiments on DragBench-DR and ReD Bench show that DragFlow surpasses both point-based and region-based baselines, setting a new state-of-the-art in drag-based image editing. Code and datasets will be publicly available upon publication.
Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted Concepts
Apr 17, 2025Ensuring the ethical deployment of text-to-image models requires effective techniques to prevent the generation of harmful or inappropriate content. While concept erasure methods offer a promising solution, existing finetuning-based approaches suffer from notable limitations. Anchor-free methods risk disrupting sampling trajectories, leading to visual artifacts, while anchor-based methods rely on the heuristic selection of anchor concepts. To overcome these shortcomings, we introduce a finetuning framework, dubbed ANT, which Automatically guides deNoising Trajectories to avoid unwanted concepts. ANT is built on a key insight: reversing the condition direction of classifier-free guidance during mid-to-late denoising stages enables precise content modification without sacrificing early-stage structural integrity. This inspires a trajectory-aware objective that preserves the integrity of the early-stage score function field, which steers samples toward the natural image manifold, without relying on heuristic anchor concept selection. For single-concept erasure, we propose an augmentation-enhanced weight saliency map to precisely identify the critical parameters that most significantly contribute to the unwanted concept, enabling more thorough and efficient erasure. For multi-concept erasure, our objective function offers a versatile plug-and-play solution that significantly boosts performance. Extensive experiments demonstrate that ANT achieves state-of-the-art results in both single and multi-concept erasure, delivering high-quality, safe outputs without compromising the generative fidelity. Code is available at https://github.com/lileyang1210/ANT
MACS: Multi-source Audio-to-image Generation with Contextual Significance and Semantic Alignment
Mar 13, 2025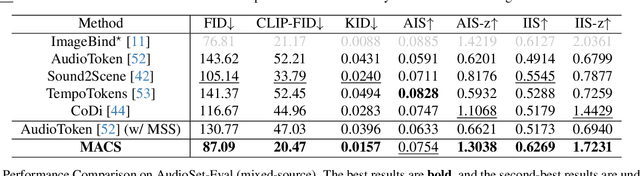
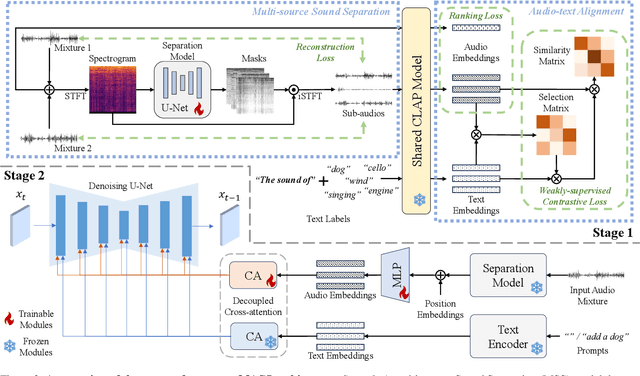
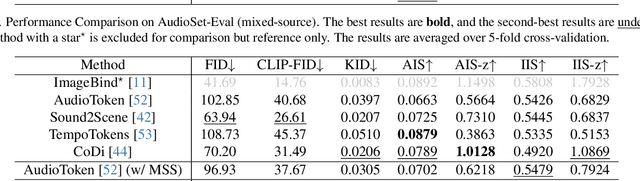
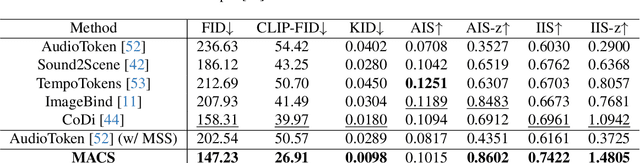
Propelled by the breakthrough in deep generative models, audio-to-image generation has emerged as a pivotal cross-model task that converts complex auditory signals into rich visual representations. However, previous works only focus on single-source audio inputs for image generation, ignoring the multi-source characteristic in natural auditory scenes, thus limiting the performance in generating comprehensive visual content. To bridge this gap, a method called MACS is proposed to conduct multi-source audio-to-image generation. This is the first work that explicitly separates multi-source audio to capture the rich audio components before image generation. MACS is a two-stage method. In the first stage, multi-source audio inputs are separated by a weakly supervised method, where the audio and text labels are semantically aligned by casting into a common space using the large pre-trained CLAP model. We introduce a ranking loss to consider the contextual significance of the separated audio signals. In the second stage, efficient image generation is achieved by mapping the separated audio signals to the generation condition using only a trainable adapter and a MLP layer. We preprocess the LLP dataset as the first full multi-source audio-to-image generation benchmark. The experiments are conducted on multi-source, mixed-source, and single-source audio-to-image generation tasks. The proposed MACS outperforms the current state-of-the-art methods in 17 of the 21 evaluation indexes on all tasks and delivers superior visual quality. The code will be publicly available.
All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian Splatting
Mar 10, 2025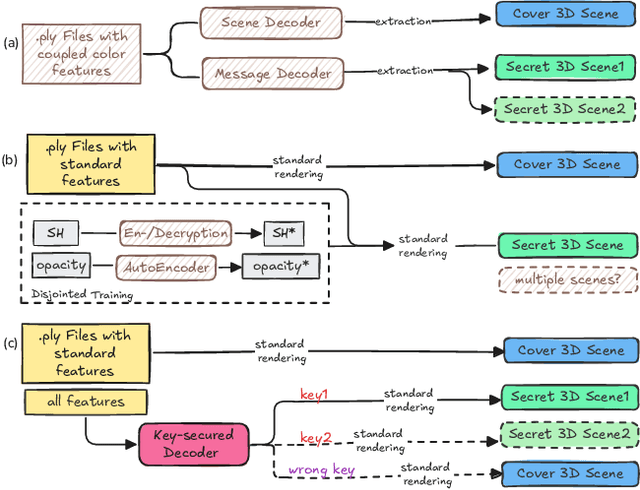



Recent advances in 3D Gaussian Splatting (3DGS) have revolutionized scene reconstruction, opening new possibilities for 3D steganography by hiding 3D secrets within 3D covers. The key challenge in steganography is ensuring imperceptibility while maintaining high-fidelity reconstruction. However, existing methods often suffer from detectability risks and utilize only suboptimal 3DGS features, limiting their full potential. We propose a novel end-to-end key-secured 3D steganography framework (KeySS) that jointly optimizes a 3DGS model and a key-secured decoder for secret reconstruction. Our approach reveals that Gaussian features contribute unequally to secret hiding. The framework incorporates a key-controllable mechanism enabling multi-secret hiding and unauthorized access prevention, while systematically exploring optimal feature update to balance fidelity and security. To rigorously evaluate steganographic imperceptibility beyond conventional 2D metrics, we introduce 3D-Sinkhorn distance analysis, which quantifies distributional differences between original and steganographic Gaussian parameters in the representation space. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both cover and secret reconstruction while maintaining high security levels, advancing the field of 3D steganography. Code is available at https://github.com/RY-Paper/KeySS
SparseMamba-PCL: Scribble-Supervised Medical Image Segmentation via SAM-Guided Progressive Collaborative Learning
Mar 03, 2025Scribble annotations significantly reduce the cost and labor required for dense labeling in large medical datasets with complex anatomical structures. However, current scribble-supervised learning methods are limited in their ability to effectively propagate sparse annotation labels to dense segmentation masks and accurately segment object boundaries. To address these issues, we propose a Progressive Collaborative Learning framework that leverages novel algorithms and the Med-SAM foundation model to enhance information quality during training. (1) We enrich ground truth scribble segmentation labels through a new algorithm, propagating scribbles to estimate object boundaries. (2) We enhance feature representation by optimizing Med-SAM-guided training through the fusion of feature embeddings from Med-SAM and our proposed Sparse Mamba network. This enriched representation also facilitates the fine-tuning of the Med-SAM decoder with enriched scribbles. (3) For inference, we introduce a Sparse Mamba network, which is highly capable of capturing local and global dependencies by replacing the traditional sequential patch processing method with a skip-sampling procedure. Experiments on the ACDC, CHAOS, and MSCMRSeg datasets validate the effectiveness of our framework, outperforming nine state-of-the-art methods. Our code is available at \href{https://github.com/QLYCode/SparseMamba-PCL}{SparseMamba-PCL.git}.
Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Advances
Oct 24, 2024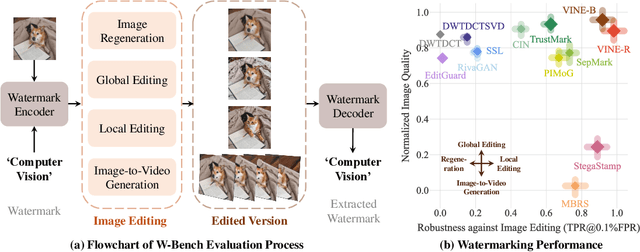
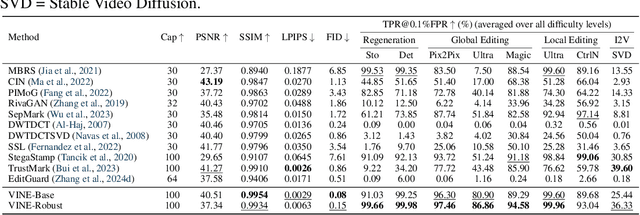
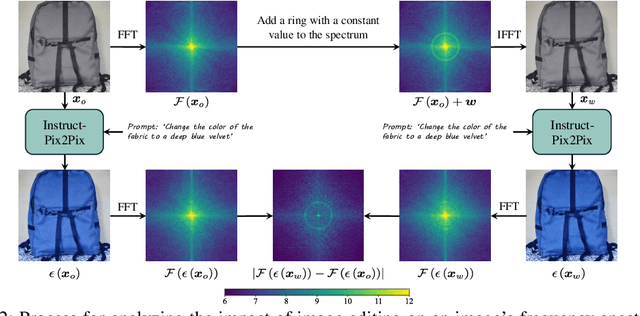
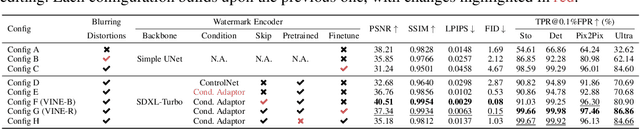
Current image watermarking methods are vulnerable to advanced image editing techniques enabled by large-scale text-to-image models. These models can distort embedded watermarks during editing, posing significant challenges to copyright protection. In this work, we introduce W-Bench, the first comprehensive benchmark designed to evaluate the robustness of watermarking methods against a wide range of image editing techniques, including image regeneration, global editing, local editing, and image-to-video generation. Through extensive evaluations of eleven representative watermarking methods against prevalent editing techniques, we demonstrate that most methods fail to detect watermarks after such edits. To address this limitation, we propose VINE, a watermarking method that significantly enhances robustness against various image editing techniques while maintaining high image quality. Our approach involves two key innovations: (1) we analyze the frequency characteristics of image editing and identify that blurring distortions exhibit similar frequency properties, which allows us to use them as surrogate attacks during training to bolster watermark robustness; (2) we leverage a large-scale pretrained diffusion model SDXL-Turbo, adapting it for the watermarking task to achieve more imperceptible and robust watermark embedding. Experimental results show that our method achieves outstanding watermarking performance under various image editing techniques, outperforming existing methods in both image quality and robustness. Code is available at https://github.com/Shilin-LU/VINE.
Benchmarking Cross-Domain Audio-Visual Deception Detection
May 11, 2024



Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection. Protocols and source code are available at \href{https://github.com/Redaimao/cross_domain_DD}{https://github.com/Redaimao/cross\_domain\_DD}.
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
May 03, 2024
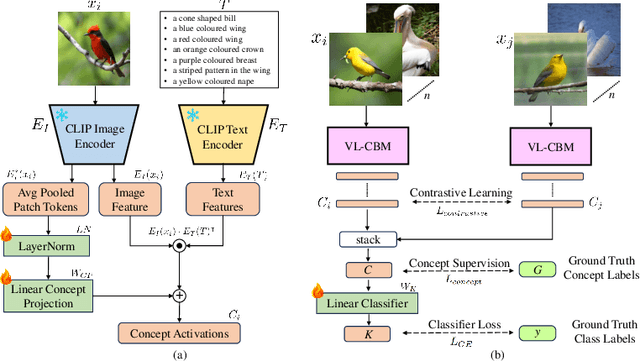


Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
MACE: Mass Concept Erasure in Diffusion Models
Mar 10, 2024

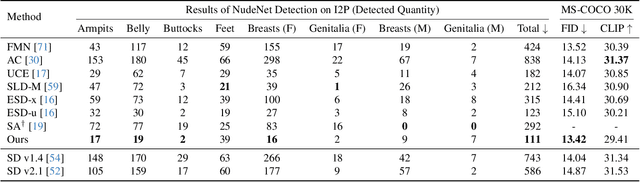
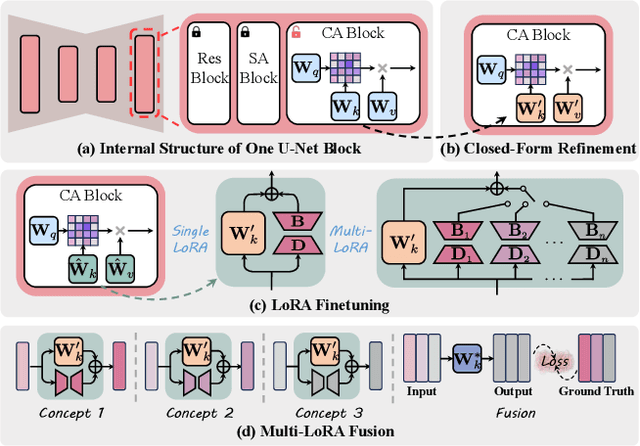
The rapid expansion of large-scale text-to-image diffusion models has raised growing concerns regarding their potential misuse in creating harmful or misleading content. In this paper, we introduce MACE, a finetuning framework for the task of mass concept erasure. This task aims to prevent models from generating images that embody unwanted concepts when prompted. Existing concept erasure methods are typically restricted to handling fewer than five concepts simultaneously and struggle to find a balance between erasing concept synonyms (generality) and maintaining unrelated concepts (specificity). In contrast, MACE differs by successfully scaling the erasure scope up to 100 concepts and by achieving an effective balance between generality and specificity. This is achieved by leveraging closed-form cross-attention refinement along with LoRA finetuning, collectively eliminating the information of undesirable concepts. Furthermore, MACE integrates multiple LoRAs without mutual interference. We conduct extensive evaluations of MACE against prior methods across four different tasks: object erasure, celebrity erasure, explicit content erasure, and artistic style erasure. Our results reveal that MACE surpasses prior methods in all evaluated tasks. Code is available at https://github.com/Shilin-LU/MACE.
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
Jul 25, 2023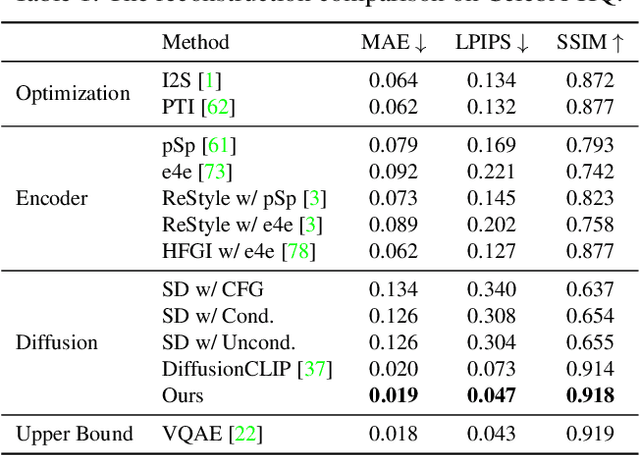
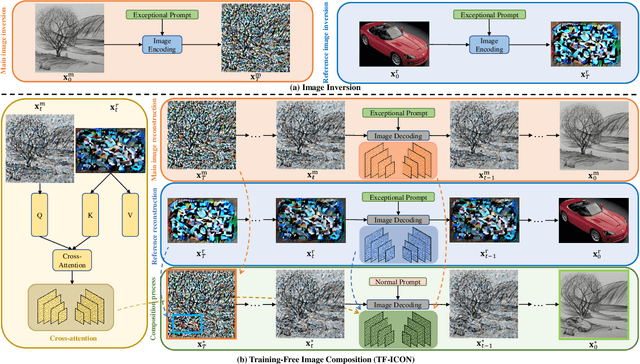
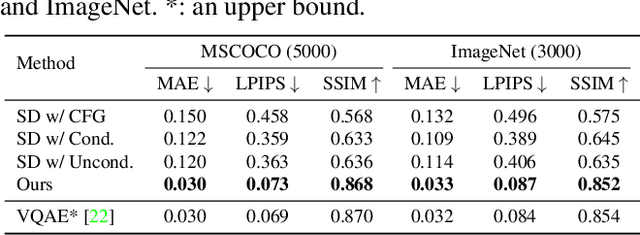

Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains. Code is available at https://github.com/Shilin-LU/TF-ICON