 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADE: Adversarial Concept Erasure in Flow Models
Jul 16, 2025

Diffusion models have demonstrated remarkable image generation capabilities, but also pose risks in privacy and fairness by memorizing sensitive concepts or perpetuating biases. We propose a novel \textbf{concept erasure} method for text-to-image diffusion models, designed to remove specified concepts (e.g., a private individual or a harmful stereotype) from the model's generative repertoire. Our method, termed \textbf{FADE} (Fair Adversarial Diffusion Erasure), combines a trajectory-aware fine-tuning strategy with an adversarial objective to ensure the concept is reliably removed while preserving overall model fidelity. Theoretically, we prove a formal guarantee that our approach minimizes the mutual information between the erased concept and the model's outputs, ensuring privacy and fairness. Empirically, we evaluate FADE on Stable Diffusion and FLUX, using benchmarks from prior work (e.g., object, celebrity, explicit content, and style erasure tasks from MACE). FADE achieves state-of-the-art concept removal performance, surpassing recent baselines like ESD, UCE, MACE, and ANT in terms of removal efficacy and image quality. Notably, FADE improves the harmonic mean of concept removal and fidelity by 5--10\% over the best prior method. We also conduct an ablation study to validate each component of FADE, confirming that our adversarial and trajectory-preserving objectives each contribute to its superior performance. Our work sets a new standard for safe and fair generative modeling by unlearning specified concepts without retraining from scratch.
Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted Concepts
Apr 17, 2025Ensuring the ethical deployment of text-to-image models requires effective techniques to prevent the generation of harmful or inappropriate content. While concept erasure methods offer a promising solution, existing finetuning-based approaches suffer from notable limitations. Anchor-free methods risk disrupting sampling trajectories, leading to visual artifacts, while anchor-based methods rely on the heuristic selection of anchor concepts. To overcome these shortcomings, we introduce a finetuning framework, dubbed ANT, which Automatically guides deNoising Trajectories to avoid unwanted concepts. ANT is built on a key insight: reversing the condition direction of classifier-free guidance during mid-to-late denoising stages enables precise content modification without sacrificing early-stage structural integrity. This inspires a trajectory-aware objective that preserves the integrity of the early-stage score function field, which steers samples toward the natural image manifold, without relying on heuristic anchor concept selection. For single-concept erasure, we propose an augmentation-enhanced weight saliency map to precisely identify the critical parameters that most significantly contribute to the unwanted concept, enabling more thorough and efficient erasure. For multi-concept erasure, our objective function offers a versatile plug-and-play solution that significantly boosts performance. Extensive experiments demonstrate that ANT achieves state-of-the-art results in both single and multi-concept erasure, delivering high-quality, safe outputs without compromising the generative fidelity. Code is available at https://github.com/lileyang1210/ANT
All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian Splatting
Mar 10, 2025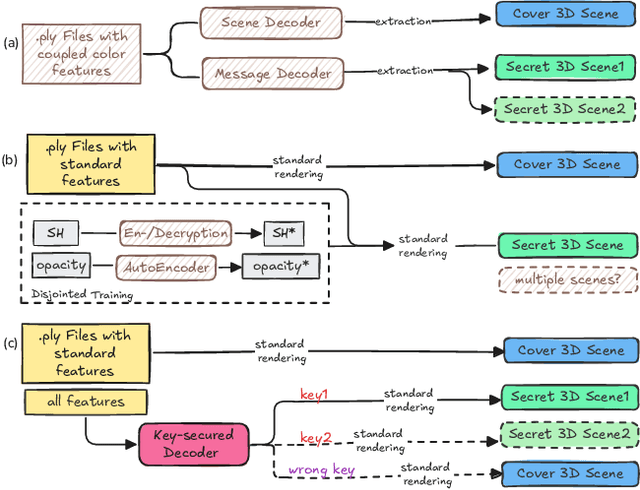



Recent advances in 3D Gaussian Splatting (3DGS) have revolutionized scene reconstruction, opening new possibilities for 3D steganography by hiding 3D secrets within 3D covers. The key challenge in steganography is ensuring imperceptibility while maintaining high-fidelity reconstruction. However, existing methods often suffer from detectability risks and utilize only suboptimal 3DGS features, limiting their full potential. We propose a novel end-to-end key-secured 3D steganography framework (KeySS) that jointly optimizes a 3DGS model and a key-secured decoder for secret reconstruction. Our approach reveals that Gaussian features contribute unequally to secret hiding. The framework incorporates a key-controllable mechanism enabling multi-secret hiding and unauthorized access prevention, while systematically exploring optimal feature update to balance fidelity and security. To rigorously evaluate steganographic imperceptibility beyond conventional 2D metrics, we introduce 3D-Sinkhorn distance analysis, which quantifies distributional differences between original and steganographic Gaussian parameters in the representation space. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both cover and secret reconstruction while maintaining high security levels, advancing the field of 3D steganography. Code is available at https://github.com/RY-Paper/KeySS
Denoising of 3D MR images using a voxel-wise hybrid residual MLP-CNN model to improve small lesion diagnostic confidence
Sep 28, 2022Small lesions in magnetic resonance imaging (MRI) images are crucial for clinical diagnosis of many kinds of diseases. However, the MRI quality can be easily degraded by various noise, which can greatly affect the accuracy of diagnosis of small lesion. Although some methods for denoising MR images have been proposed, task-specific denoising methods for improving the diagnosis confidence of small lesions are lacking. In this work, we propose a voxel-wise hybrid residual MLP-CNN model to denoise three-dimensional (3D) MR images with small lesions. We combine basic deep learning architecture, MLP and CNN, to obtain an appropriate inherent bias for the image denoising and integrate each output layers in MLP and CNN by adding residual connections to leverage long-range information. We evaluate the proposed method on 720 T2-FLAIR brain images with small lesions at different noise levels. The results show the superiority of our method in both quantitative and visual evaluations on testing dataset compared to state-of-the-art methods. Moreover, two experienced radiologists agreed that at moderate and high noise levels, our method outperforms other methods in terms of recovery of small lesions and overall image denoising quality. The implementation of our method is available at https://github.com/laowangbobo/Residual_MLP_CNN_Mixer.
DESCN: Deep Entire Space Cross Networks for Individual Treatment Effect Estimation
Jul 19, 2022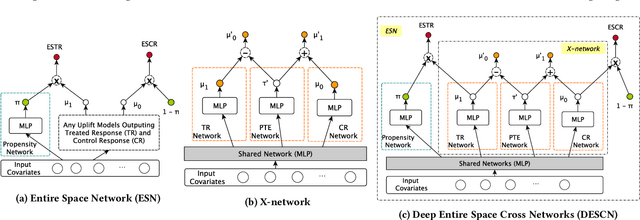

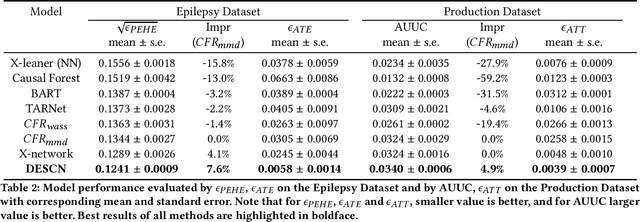

Causal Inference has wide applications in various areas such as E-commerce and precision medicine, and its performance heavily relies on the accurate estimation of the Individual Treatment Effect (ITE). Conventionally, ITE is predicted by modeling the treated and control response functions separately in their individual sample spaces. However, such an approach usually encounters two issues in practice, i.e. divergent distribution between treated and control groups due to treatment bias, and significant sample imbalance of their population sizes. This paper proposes Deep Entire Space Cross Networks (DESCN) to model treatment effects from an end-to-end perspective. DESCN captures the integrated information of the treatment propensity, the response, and the hidden treatment effect through a cross network in a multi-task learning manner. Our method jointly learns the treatment and response functions in the entire sample space to avoid treatment bias and employs an intermediate pseudo treatment effect prediction network to relieve sample imbalance. Extensive experiments are conducted on a synthetic dataset and a large-scaled production dataset from the E-commerce voucher distribution business. The results indicate that DESCN can successfully enhance the accuracy of ITE estimation and improve the uplift ranking performance. A sample of the production dataset and the source code are released to facilitate future research in the community, which is, to the best of our knowledge, the first large-scale public biased treatment dataset for causal inference.
* KDD 2022
Multi-core fiber enabled fading noise suppression in φ-OFDR based quantitative distributed vibration sensing
May 03, 2022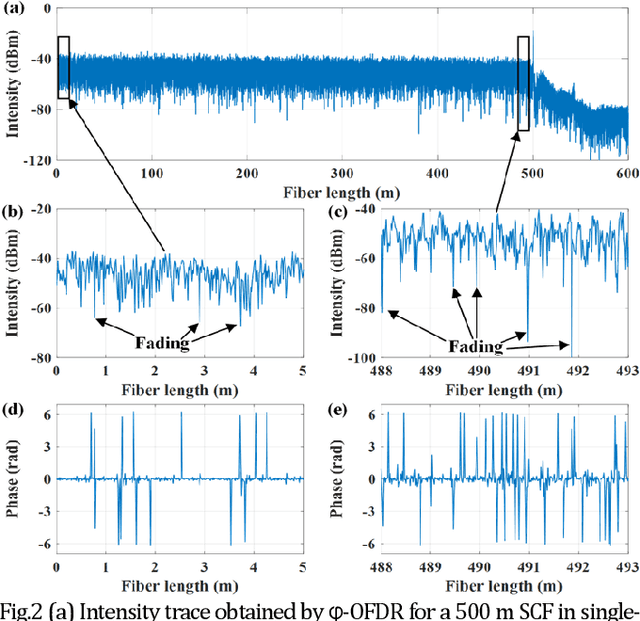
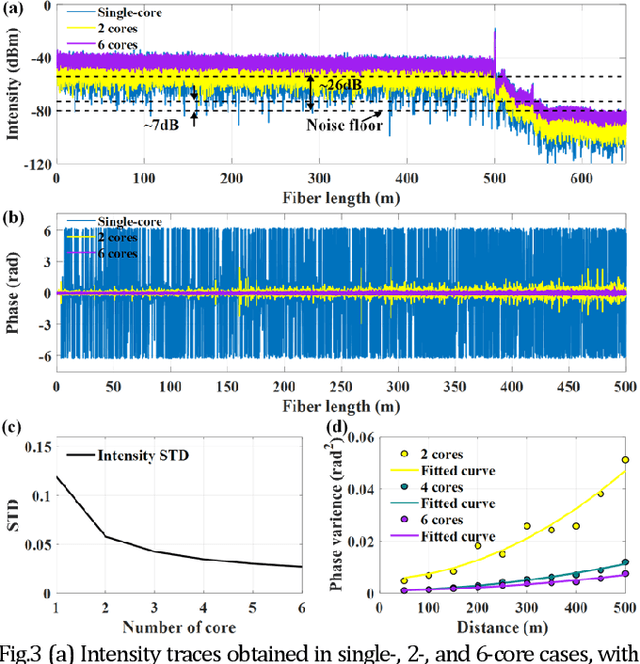
Coherent fading has been regarded as a critical issue in phase-sensitive optical frequency domain reflectometry ({\phi}-OFDR) based distributed fiber-optic sensing. Here, we report on an approach for fading noise suppression in {\phi}-OFDR with multi-core fiber. By exploiting the independent nature of the randomness in the distribution of reflective index in each of the cores, the drastic phase fluctuations due to the fading phenomina can be effectively alleviated by applying weighted vectorial averaging for the Rayleigh backscattering traces from each of the cores with distinct fading distributions. With the consistent linear response with respect to external excitation of interest for each of the cores, demonstration for the propsoed {\phi}-OFDR with a commercial seven-core fiber has achieved highly sensitive quantitative distributed vibration sensing with about 2.2 nm length precision and 2 cm sensing resolution along the 500 m fiber, corresponding to a range resolution factor as high as about about 4E-5. Featuring long distance, high sensitivity, high resolution, and fading robustness, this approach has shown promising potentials in various sensing techniques for a wide range of practical scenarios.
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
Nov 05, 2021
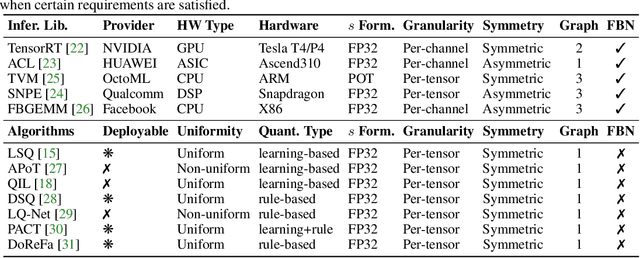

Model quantization has emerged as an indispensable technique to accelerate deep learning inference. While researchers continue to push the frontier of quantization algorithms, existing quantization work is often unreproducible and undeployable. This is because researchers do not choose consistent training pipelines and ignore the requirements for hardware deployments. In this work, we propose Model Quantization Benchmark (MQBench), a first attempt to evaluate, analyze, and benchmark the reproducibility and deployability for model quantization algorithms. We choose multiple different platforms for real-world deployments, including CPU, GPU, ASIC, DSP, and evaluate extensive state-of-the-art quantization algorithms under a unified training pipeline. MQBench acts like a bridge to connect the algorithm and the hardware. We conduct a comprehensive analysis and find considerable intuitive or counter-intuitive insights. By aligning the training settings, we find existing algorithms have about the same performance on the conventional academic track. While for the hardware-deployable quantization, there is a huge accuracy gap which remains unsettled. Surprisingly, no existing algorithm wins every challenge in MQBench, and we hope this work could inspire future research directions.
One Model for All Quantization: A Quantized Network Supporting Hot-Swap Bit-Width Adjustment
May 04, 2021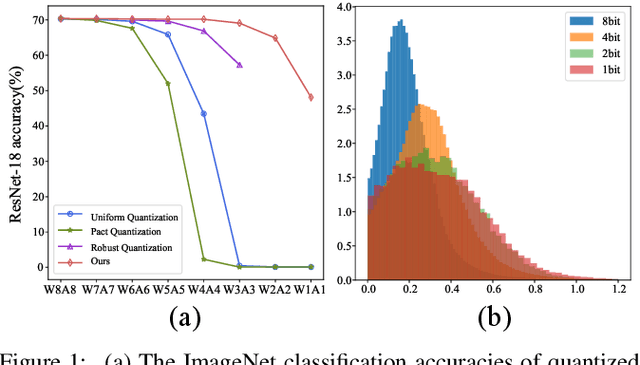
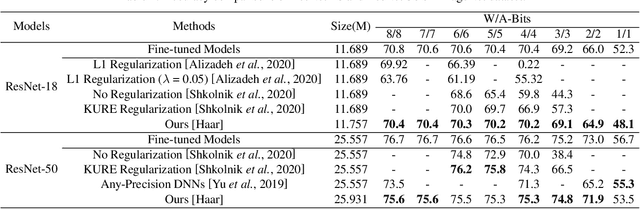
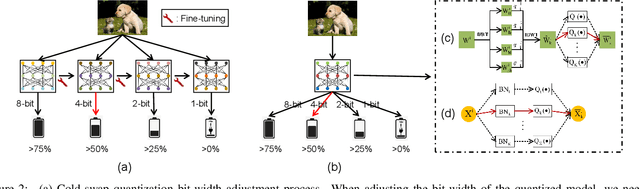
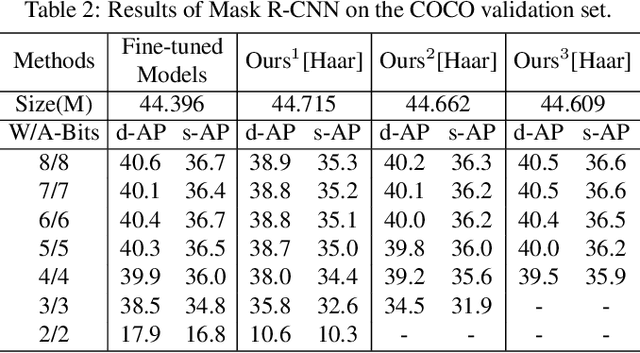
As an effective technique to achieve the implementation of deep neural networks in edge devices, model quantization has been successfully applied in many practical applications. No matter the methods of quantization aware training (QAT) or post-training quantization (PTQ), they all depend on the target bit-widths. When the precision of quantization is adjusted, it is necessary to fine-tune the quantized model or minimize the quantization noise, which brings inconvenience in practical applications. In this work, we propose a method to train a model for all quantization that supports diverse bit-widths (e.g., form 8-bit to 1-bit) to satisfy the online quantization bit-width adjustment. It is hot-swappable that can provide specific quantization strategies for different candidates through multiscale quantization. We use wavelet decomposition and reconstruction to increase the diversity of weights, thus significantly improving the performance of each quantization candidate, especially at ultra-low bit-widths (e.g., 3-bit, 2-bit, and 1-bit). Experimental results on ImageNet and COCO show that our method can achieve accuracy comparable performance to dedicated models trained at the same precision.
MWQ: Multiscale Wavelet Quantized Neural Networks
Mar 09, 2021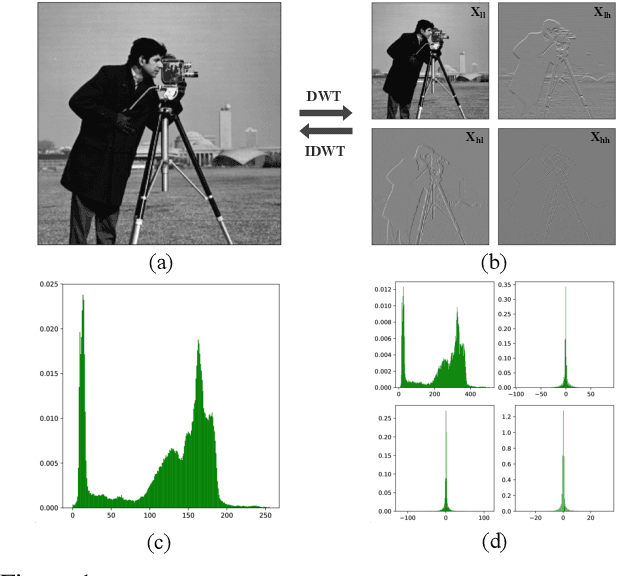
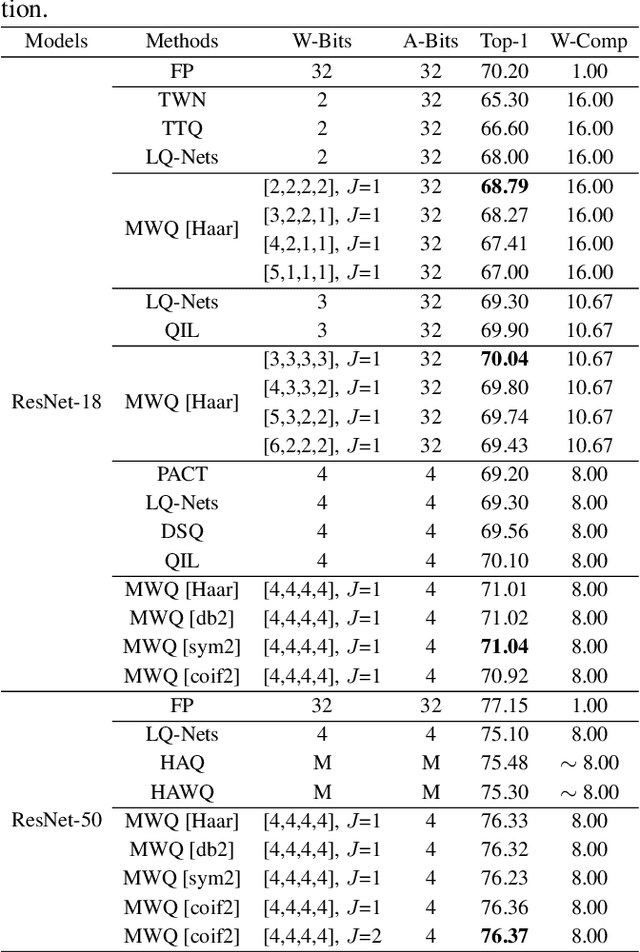
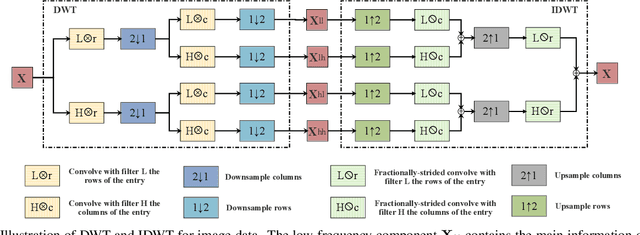
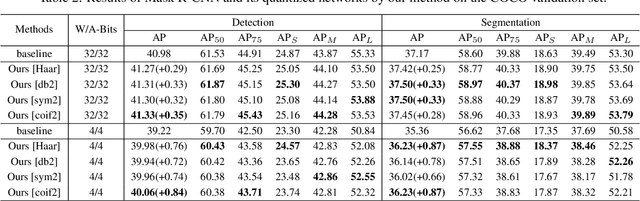
Model quantization can reduce the model size and computational latency, it has become an essential technique for the deployment of deep neural networks on resourceconstrained hardware (e.g., mobile phones and embedded devices). The existing quantization methods mainly consider the numerical elements of the weights and activation values, ignoring the relationship between elements. The decline of representation ability and information loss usually lead to the performance degradation. Inspired by the characteristics of images in the frequency domain, we propose a novel multiscale wavelet quantization (MWQ) method. This method decomposes original data into multiscale frequency components by wavelet transform, and then quantizes the components of different scales, respectively. It exploits the multiscale frequency and spatial information to alleviate the information loss caused by quantization in the spatial domain. Because of the flexibility of MWQ, we demonstrate three applications (e.g., model compression, quantized network optimization, and information enhancement) on the ImageNet and COCO datasets. Experimental results show that our method has stronger representation ability and can play an effective role in quantized neural networks.
Effective and Fast: A Novel Sequential Single Path Search for Mixed-Precision Quantization
Mar 04, 2021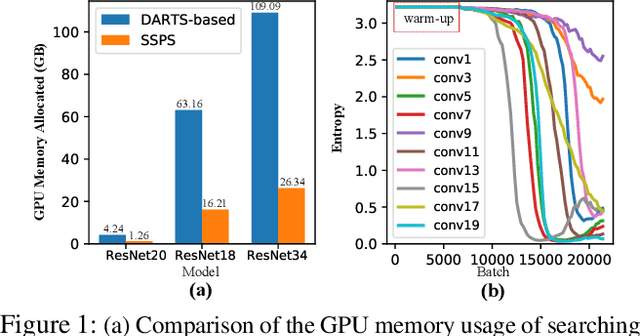
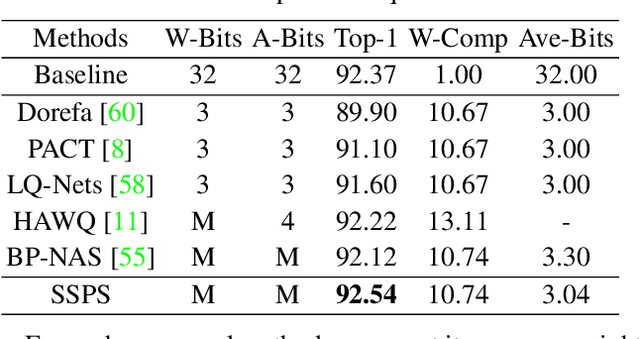
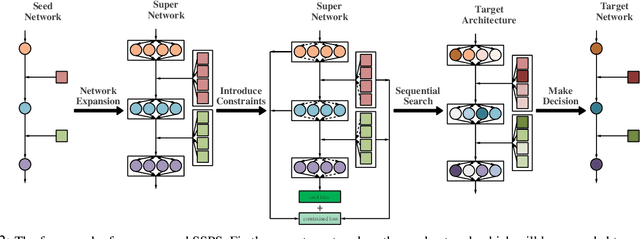
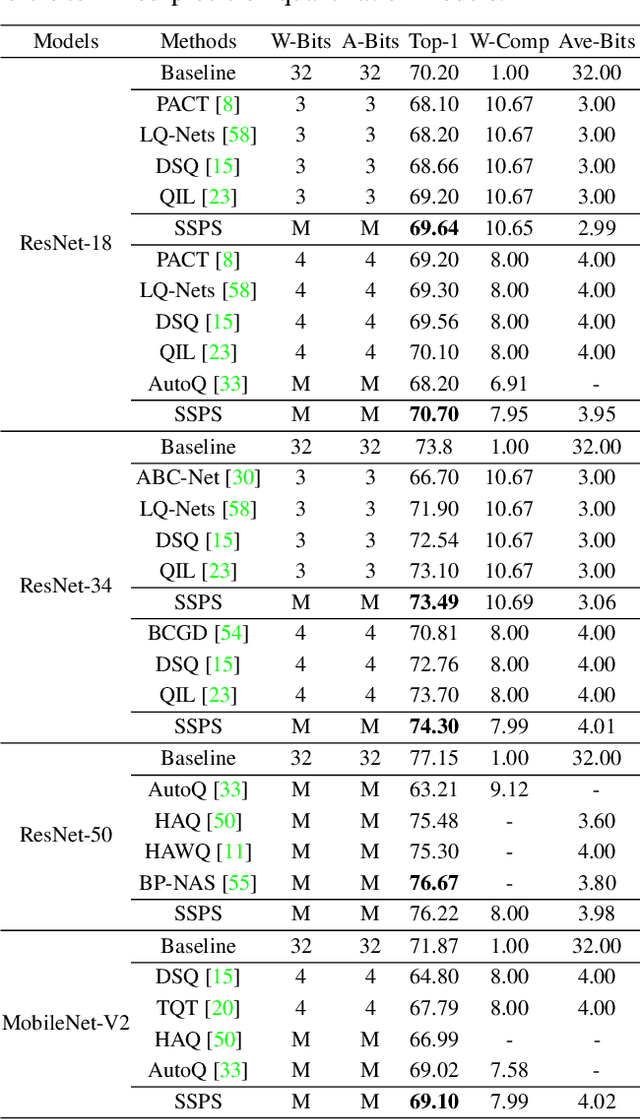
Since model quantization helps to reduce the model size and computation latency, it has been successfully applied in many applications of mobile phones, embedded devices and smart chips. The mixed-precision quantization model can match different quantization bit-precisions according to the sensitivity of different layers to achieve great performance. However, it is a difficult problem to quickly determine the quantization bit-precision of each layer in deep neural networks according to some constraints (e.g., hardware resources, energy consumption, model size and computation latency). To address this issue, we propose a novel sequential single path search (SSPS) method for mixed-precision quantization,in which the given constraints are introduced into its loss function to guide searching process. A single path search cell is used to combine a fully differentiable supernet, which can be optimized by gradient-based algorithms. Moreover, we sequentially determine the candidate precisions according to the selection certainties to exponentially reduce the search space and speed up the convergence of searching process. Experiments show that our method can efficiently search the mixed-precision models for different architectures (e.g., ResNet-20, 18, 34, 50 and MobileNet-V2) and datasets (e.g., CIFAR-10, ImageNet and COCO) under given constraints, and our experimental results verify that SSPS significantly outperforms their uniform counterparts.