 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Neural Networks via {-1, +1} Encoding Decomposition and Acceleration
Jun 18, 2021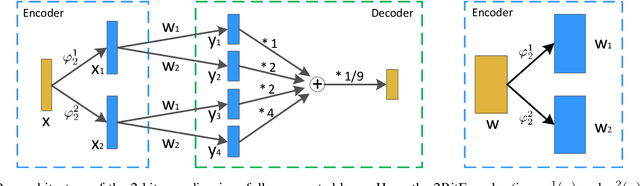
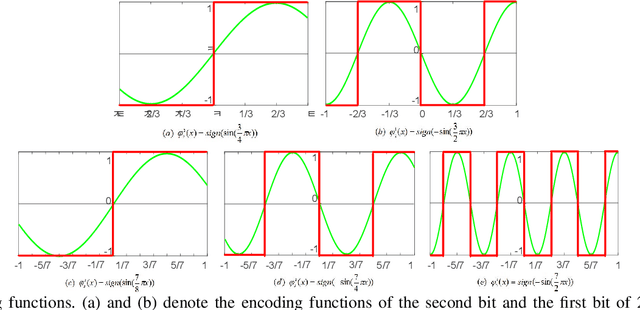


The training of deep neural networks (DNNs) always requires intensive resources for both computation and data storage. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which severely limits their applicability in industrial applications. To address this issue, we propose a novel encoding scheme using {-1, +1} to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (i.e., xnor and bitcount) to achieve model compression, computational acceleration, and resource saving. By using our method, users can achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is highly suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on large-scale image classification (e.g., ImageNet), object detection, and semantic segmentation tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its high-bit counterparts.
One Model for All Quantization: A Quantized Network Supporting Hot-Swap Bit-Width Adjustment
May 04, 2021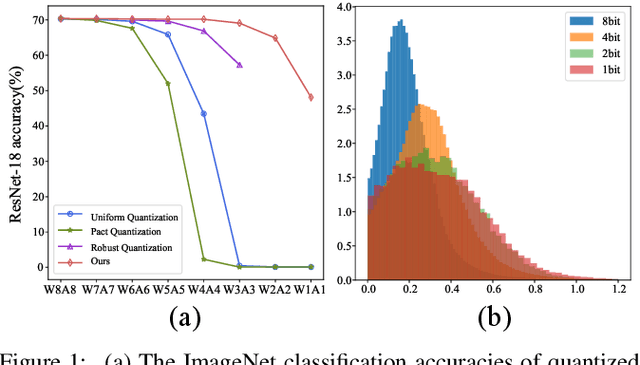
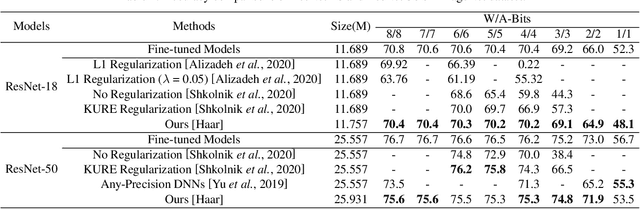
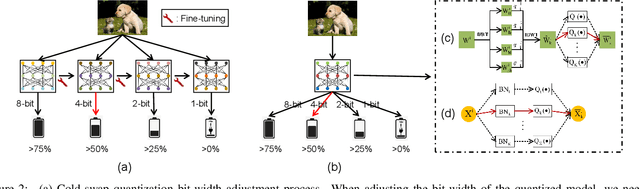
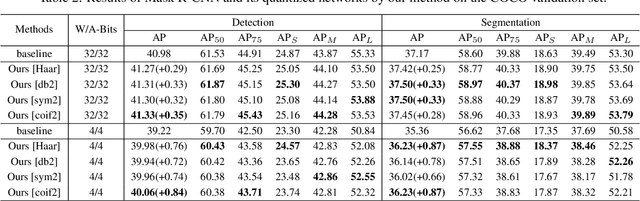
As an effective technique to achieve the implementation of deep neural networks in edge devices, model quantization has been successfully applied in many practical applications. No matter the methods of quantization aware training (QAT) or post-training quantization (PTQ), they all depend on the target bit-widths. When the precision of quantization is adjusted, it is necessary to fine-tune the quantized model or minimize the quantization noise, which brings inconvenience in practical applications. In this work, we propose a method to train a model for all quantization that supports diverse bit-widths (e.g., form 8-bit to 1-bit) to satisfy the online quantization bit-width adjustment. It is hot-swappable that can provide specific quantization strategies for different candidates through multiscale quantization. We use wavelet decomposition and reconstruction to increase the diversity of weights, thus significantly improving the performance of each quantization candidate, especially at ultra-low bit-widths (e.g., 3-bit, 2-bit, and 1-bit). Experimental results on ImageNet and COCO show that our method can achieve accuracy comparable performance to dedicated models trained at the same precision.
MWQ: Multiscale Wavelet Quantized Neural Networks
Mar 09, 2021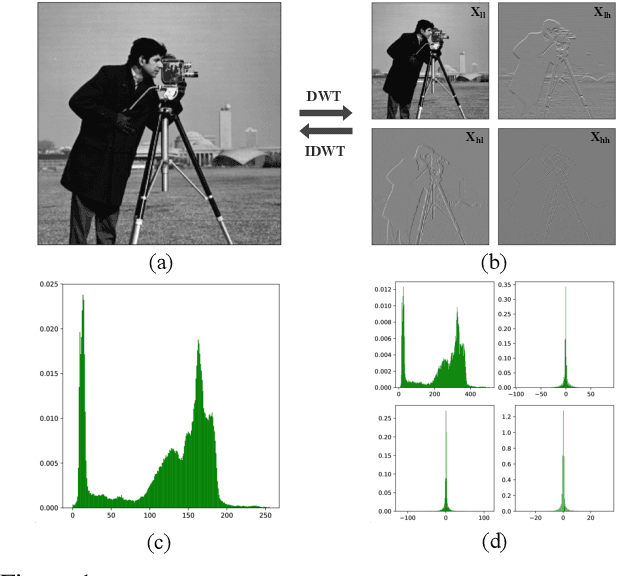
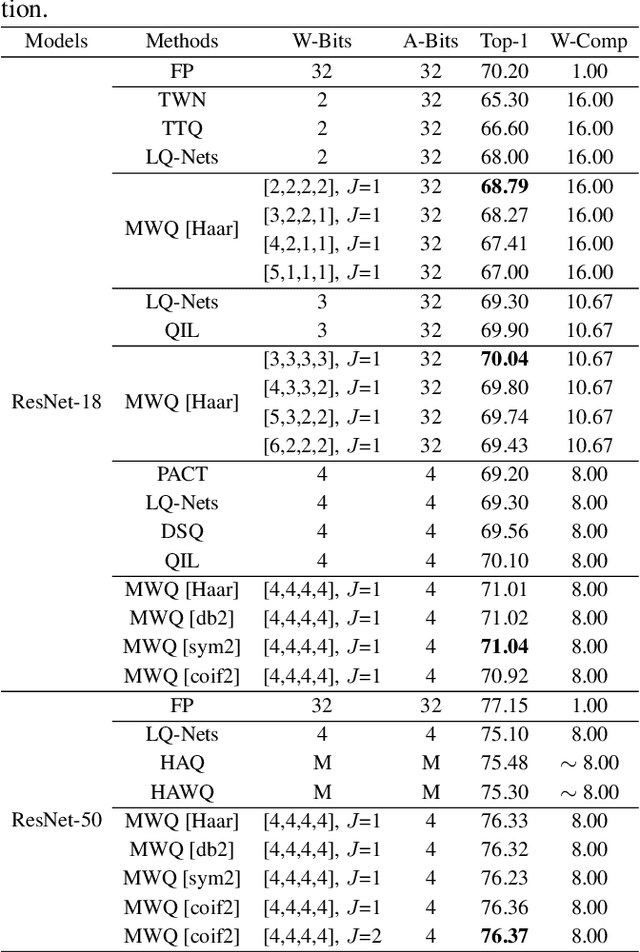
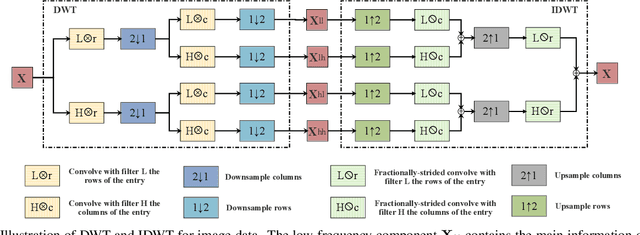
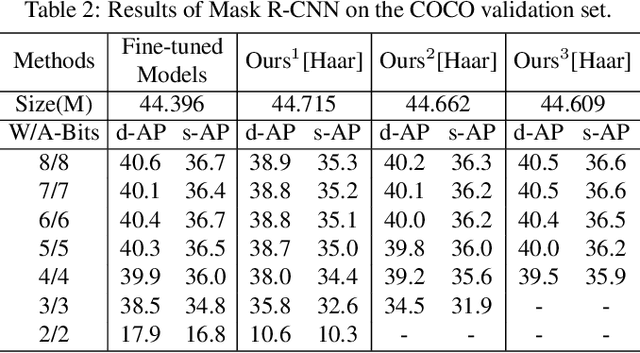
Model quantization can reduce the model size and computational latency, it has become an essential technique for the deployment of deep neural networks on resourceconstrained hardware (e.g., mobile phones and embedded devices). The existing quantization methods mainly consider the numerical elements of the weights and activation values, ignoring the relationship between elements. The decline of representation ability and information loss usually lead to the performance degradation. Inspired by the characteristics of images in the frequency domain, we propose a novel multiscale wavelet quantization (MWQ) method. This method decomposes original data into multiscale frequency components by wavelet transform, and then quantizes the components of different scales, respectively. It exploits the multiscale frequency and spatial information to alleviate the information loss caused by quantization in the spatial domain. Because of the flexibility of MWQ, we demonstrate three applications (e.g., model compression, quantized network optimization, and information enhancement) on the ImageNet and COCO datasets. Experimental results show that our method has stronger representation ability and can play an effective role in quantized neural networks.
Effective and Fast: A Novel Sequential Single Path Search for Mixed-Precision Quantization
Mar 04, 2021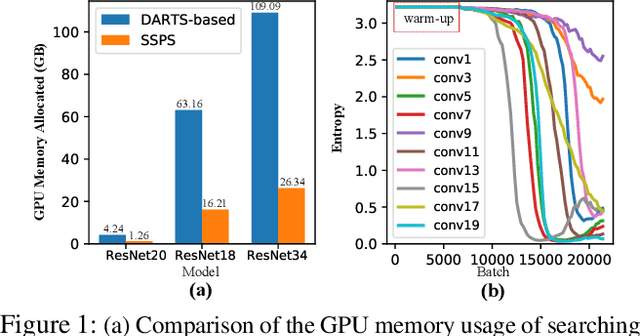
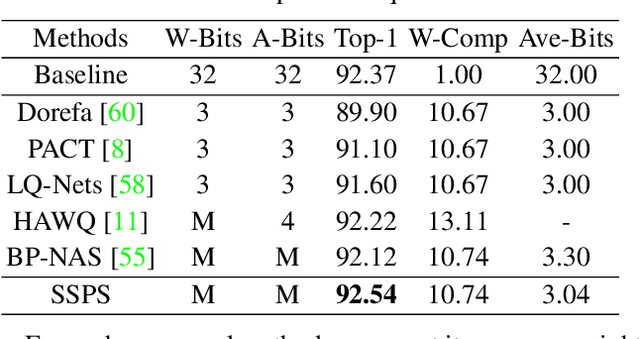
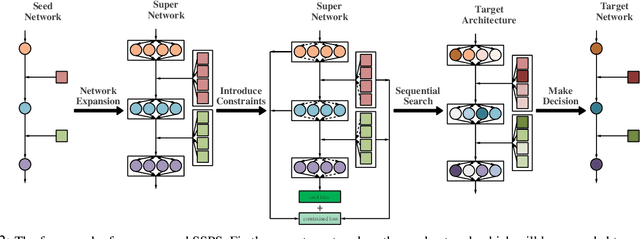
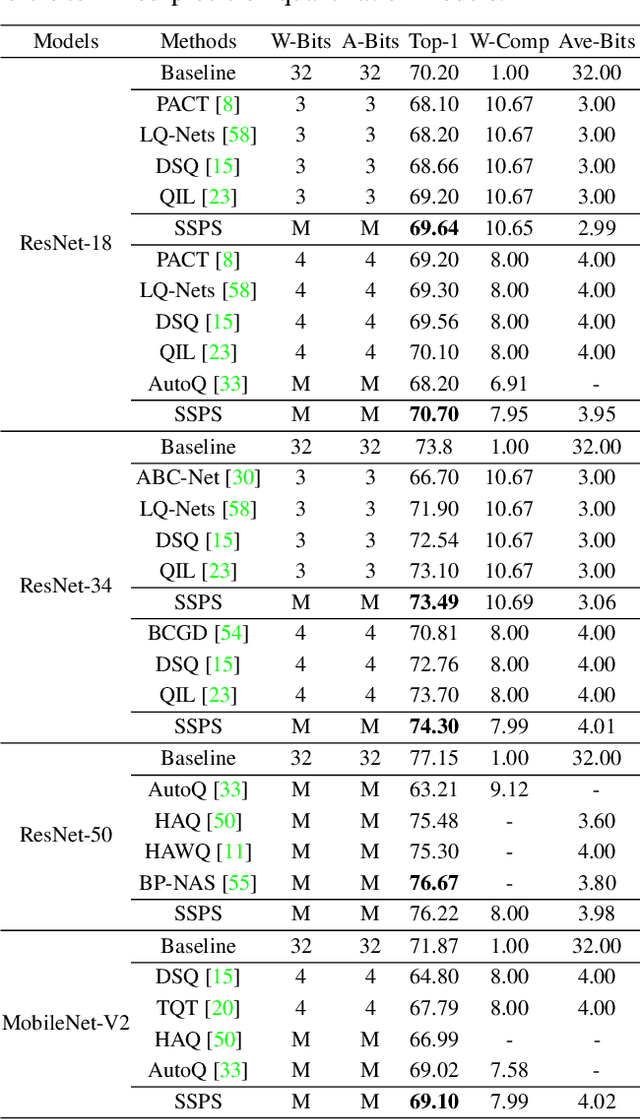
Since model quantization helps to reduce the model size and computation latency, it has been successfully applied in many applications of mobile phones, embedded devices and smart chips. The mixed-precision quantization model can match different quantization bit-precisions according to the sensitivity of different layers to achieve great performance. However, it is a difficult problem to quickly determine the quantization bit-precision of each layer in deep neural networks according to some constraints (e.g., hardware resources, energy consumption, model size and computation latency). To address this issue, we propose a novel sequential single path search (SSPS) method for mixed-precision quantization,in which the given constraints are introduced into its loss function to guide searching process. A single path search cell is used to combine a fully differentiable supernet, which can be optimized by gradient-based algorithms. Moreover, we sequentially determine the candidate precisions according to the selection certainties to exponentially reduce the search space and speed up the convergence of searching process. Experiments show that our method can efficiently search the mixed-precision models for different architectures (e.g., ResNet-20, 18, 34, 50 and MobileNet-V2) and datasets (e.g., CIFAR-10, ImageNet and COCO) under given constraints, and our experimental results verify that SSPS significantly outperforms their uniform counterparts.
Pixel DAG-Recurrent Neural Network for Spectral-Spatial Hyperspectral Image Classification
Jun 09, 2019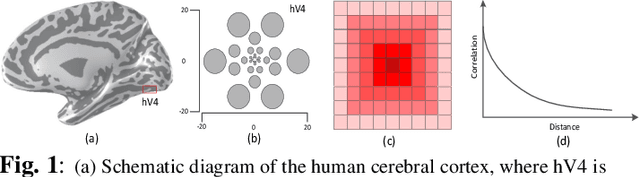
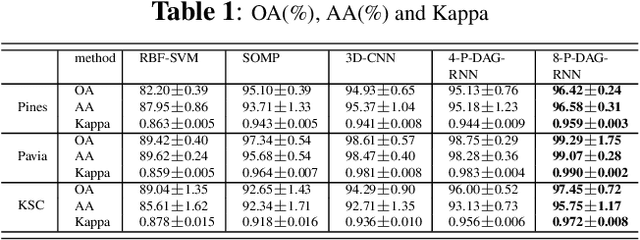
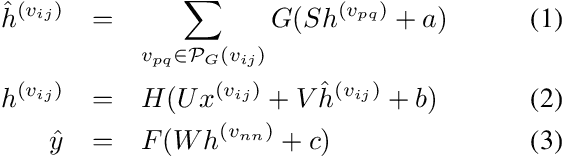
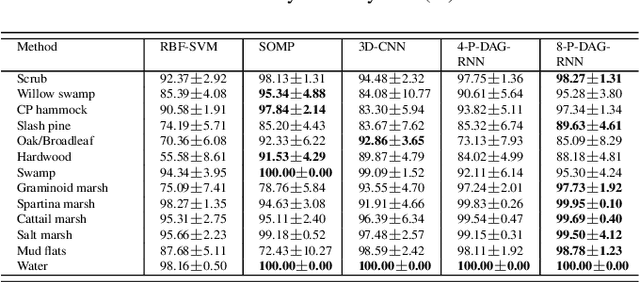
Exploiting rich spatial and spectral features contributes to improve the classification accuracy of hyperspectral images (HSIs). In this paper, based on the mechanism of the population receptive field (pRF) in human visual cortex, we further utilize the spatial correlation of pixels in images and propose pixel directed acyclic graph recurrent neural network (Pixel DAG-RNN) to extract and apply spectral-spatial features for HSIs classification. In our model, an undirected cyclic graph (UCG) is used to represent the relevance connectivity of pixels in an image patch, and four DAGs are used to approximate the spatial relationship of UCGs. In order to avoid overfitting, weight sharing and dropout are adopted. The higher classification performance of our model on HSIs classification has been verified by experiments on three benchmark data sets.
Semi-supervised Complex-valued GAN for Polarimetric SAR Image Classification
Jun 09, 2019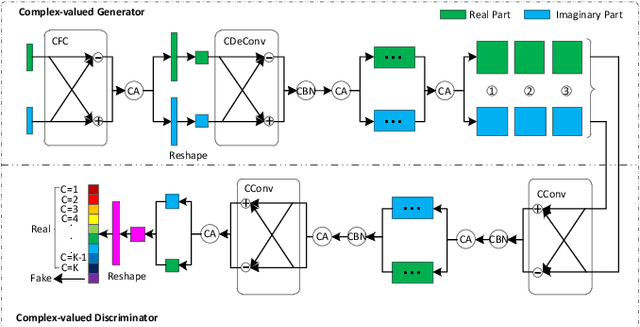
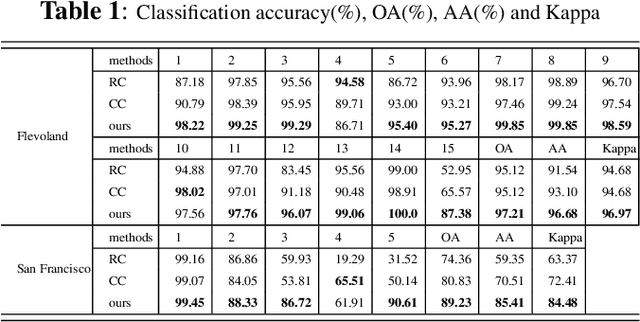
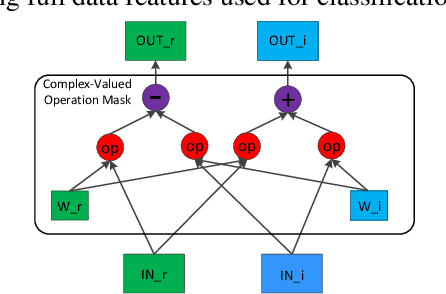
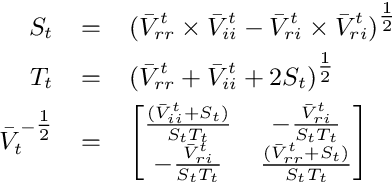
Polarimetric synthetic aperture radar (PolSAR) images are widely used in disaster detection and military reconnaissance and so on. However, their interpretation faces some challenges, e.g., deficiency of labeled data, inadequate utilization of data information and so on. In this paper, a complex-valued generative adversarial network (GAN) is proposed for the first time to address these issues. The complex number form of model complies with the physical mechanism of PolSAR data and in favor of utilizing and retaining amplitude and phase information of PolSAR data. GAN architecture and semi-supervised learning are combined to handle deficiency of labeled data. GAN expands training data and semi-supervised learning is used to train network with generated, labeled and unlabeled data. Experimental results on two benchmark data sets show that our model outperforms existing state-of-the-art models, especially for conditions with fewer labeled data.
Multi-Precision Quantized Neural Networks via Encoding Decomposition of -1 and +1
May 31, 2019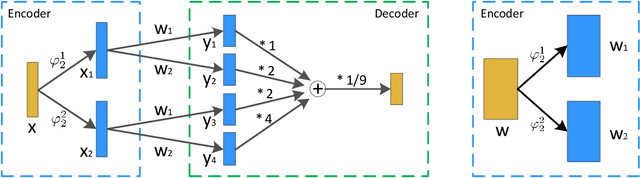


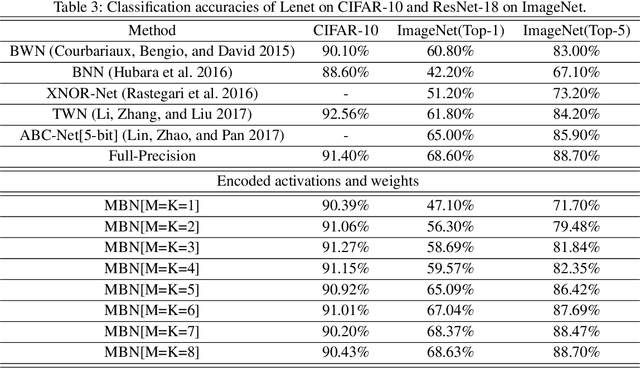
The training of deep neural networks (DNNs) requires intensive resources both for computation and for storage performance. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which seriously limits their applicability in industry applications. To address this issue, we propose a novel encoding scheme of using {-1,+1} to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. Based on our method, users can easily achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is very suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on both large-scale image classification tasks (e.g., ImageNet) and object detection tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its full-precision counterparts.