 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffMOD: Progressive Diffusion Point Denoising for Moving Object Detection in Remote Sensing
Apr 14, 2025
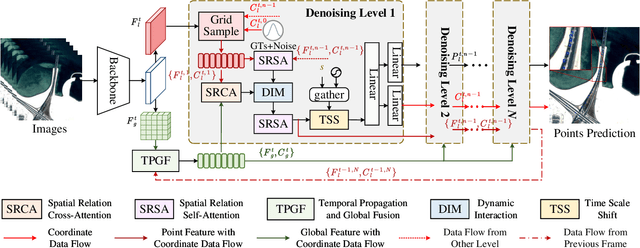
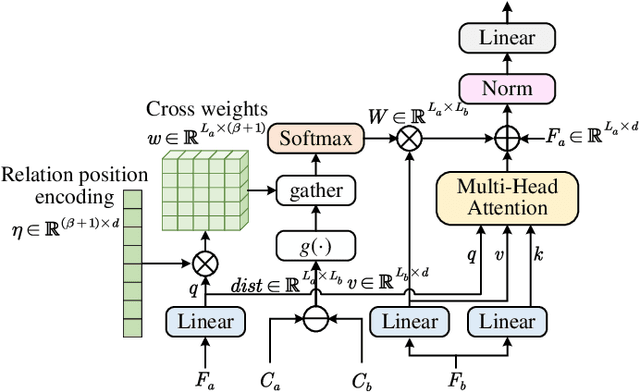
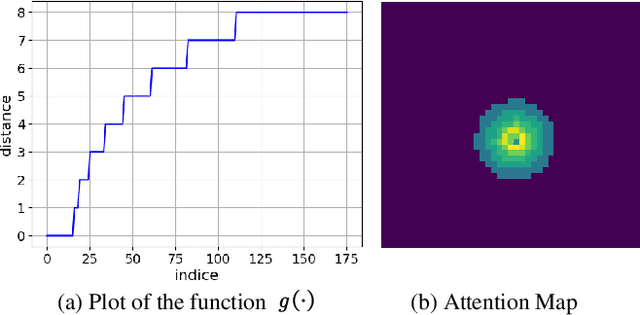
Moving object detection (MOD) in remote sensing is significantly challenged by low resolution, extremely small object sizes, and complex noise interference. Current deep learning-based MOD methods rely on probability density estimation, which restricts flexible information interaction between objects and across temporal frames. To flexibly capture high-order inter-object and temporal relationships, we propose a point-based MOD in remote sensing. Inspired by diffusion models, the network optimization is formulated as a progressive denoising process that iteratively recovers moving object centers from sparse noisy points. Specifically, we sample scattered features from the backbone outputs as atomic units for subsequent processing, while global feature embeddings are aggregated to compensate for the limited coverage of sparse point features. By modeling spatial relative positions and semantic affinities, Spatial Relation Aggregation Attention is designed to enable high-order interactions among point-level features for enhanced object representation. To enhance temporal consistency, the Temporal Propagation and Global Fusion module is designed, which leverages an implicit memory reasoning mechanism for robust cross-frame feature integration. To align with the progressive denoising process, we propose a progressive MinK optimal transport assignment strategy that establishes specialized learning objectives at each denoising level. Additionally, we introduce a missing loss function to counteract the clustering tendency of denoised points around salient objects. Experiments on the RsData remote sensing MOD dataset show that our MOD method based on scattered point denoising can more effectively explore potential relationships between sparse moving objects and improve the detection capability and temporal consistency.
One Model for All Quantization: A Quantized Network Supporting Hot-Swap Bit-Width Adjustment
May 04, 2021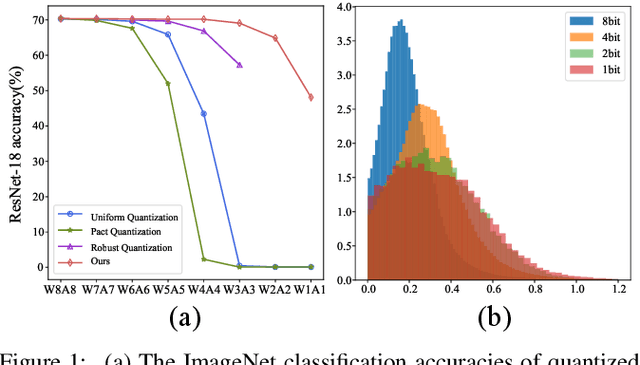
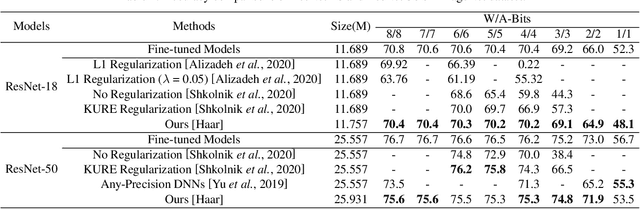
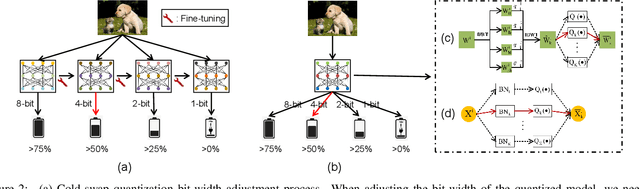
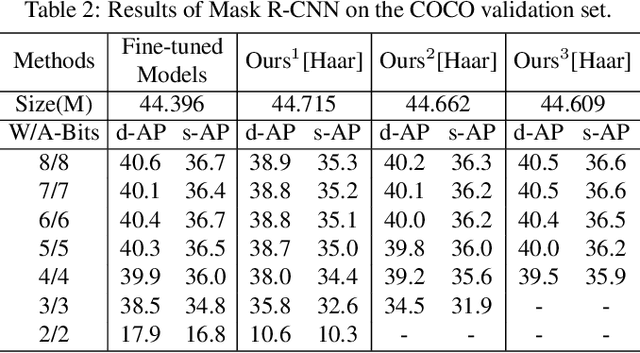
As an effective technique to achieve the implementation of deep neural networks in edge devices, model quantization has been successfully applied in many practical applications. No matter the methods of quantization aware training (QAT) or post-training quantization (PTQ), they all depend on the target bit-widths. When the precision of quantization is adjusted, it is necessary to fine-tune the quantized model or minimize the quantization noise, which brings inconvenience in practical applications. In this work, we propose a method to train a model for all quantization that supports diverse bit-widths (e.g., form 8-bit to 1-bit) to satisfy the online quantization bit-width adjustment. It is hot-swappable that can provide specific quantization strategies for different candidates through multiscale quantization. We use wavelet decomposition and reconstruction to increase the diversity of weights, thus significantly improving the performance of each quantization candidate, especially at ultra-low bit-widths (e.g., 3-bit, 2-bit, and 1-bit). Experimental results on ImageNet and COCO show that our method can achieve accuracy comparable performance to dedicated models trained at the same precision.