 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Precision Quantized Neural Networks via Encoding Decomposition of -1 and +1
Paper and Code
May 31, 2019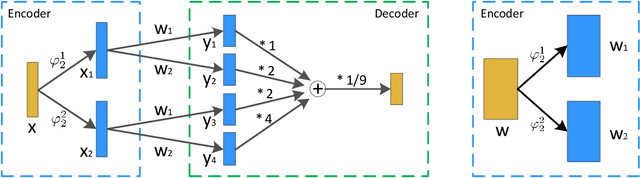


The training of deep neural networks (DNNs) requires intensive resources both for computation and for storage performance. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which seriously limits their applicability in industry applications. To address this issue, we propose a novel encoding scheme of using {-1,+1} to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. Based on our method, users can easily achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is very suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on both large-scale image classification tasks (e.g., ImageNet) and object detection tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its full-precision counterparts.