 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-weighted Centered Kernel Alignment for Knowledge Distillation in Large Audio-Language Models Applied to Speech Emotion Recognition
Feb 02, 2026The emergence of Large Audio-Language Models (LALMs) has advanced Speech Emotion Recognition (SER), but their size limits deployment in resource-constrained environments. While Knowledge Distillation is effective for LALM compression, existing methods remain underexplored in distilling the cross-modal projection module (Projector), and often struggle with alignment due to differences in feature dimensions. We propose PL-Distill, a KD framework that combines Projector-Level Distillation (PDist) to align audio embeddings and Logits-Level Distillation (LDist) to align output logits. PDist introduces Attention-weighted Centered Kernel Alignment, a novel approach we propose to highlight important time steps and address dimension mismatches. Meanwhile, LDist minimizes the Kullback-Leibler divergence between teacher and student logits from audio and text modalities. On IEMOCAP, RAVDESS, and SAVEE, PL-Distill compresses an 8.4B-parameter teacher to a compact 1.1B-parameter student, consistently outperforming the teacher, state-of-the-art pretrained models, and other KD baselines across all metrics.
EMO-RL: Emotion-Rule-Based Reinforcement Learning Enhanced Audio-Language Model for Generalized Speech Emotion Recognition
Sep 19, 2025Although Large Audio-Language Models (LALMs) have exhibited outstanding performance in auditory understanding, their performance in affective computing scenarios, particularly in emotion recognition, reasoning, and subtle sentiment differentiation, remains suboptimal. Recent advances in Reinforcement Learning (RL) have shown promise in improving LALMs' reasoning abilities. However, two critical challenges hinder the direct application of RL techniques to Speech Emotion Recognition (SER) tasks: (1) convergence instability caused by ambiguous emotional boundaries and (2) limited reasoning ability when using relatively small models (e.g., 7B-parameter architectures). To overcome these limitations, we introduce EMO-RL, a novel framework incorporating reinforcement learning with two key innovations: Emotion Similarity-Weighted Reward (ESWR) and Explicit Structured Reasoning (ESR). Built upon pretrained LALMs, our method employs group-relative policy optimization with emotion constraints. Comprehensive experiments demonstrate that our EMO-RL training strategies can significantly enhance the emotional reasoning capabilities of LALMs, attaining state-of-the-art results on both the MELD and IEMOCAP datasets, and cross-dataset experiments prove the strong superiority of generalization.
Generalized Audio Deepfake Detection Using Frame-level Latent Information Entropy
Apr 15, 2025



Generalizability, the capacity of a robust model to perform effectively on unseen data, is crucial for audio deepfake detection due to the rapid evolution of text-to-speech (TTS) and voice conversion (VC) technologies. A promising approach to differentiate between bonafide and spoof samples lies in identifying intrinsic disparities to enhance model generalizability. From an information-theoretic perspective, we hypothesize the information content is one of the intrinsic differences: bonafide sample represents a dense, information-rich sampling of the real world, whereas spoof sample is typically derived from lower-dimensional, less informative representations. To implement this, we introduce frame-level latent information entropy detector(f-InfoED), a framework that extracts distinctive information entropy from latent representations at the frame level to identify audio deepfakes. Furthermore, we present AdaLAM, which extends large pre-trained audio models with trainable adapters for enhanced feature extraction. To facilitate comprehensive evaluation, the audio deepfake forensics 2024 (ADFF 2024) dataset was built by the latest TTS and VC methods. Extensive experiments demonstrate that our proposed approach achieves state-of-the-art performance and exhibits remarkable generalization capabilities. Further analytical studies confirms the efficacy of AdaLAM in extracting discriminative audio features and f-InfoED in leveraging latent entropy information for more generalized deepfake detection.
ACCon: Angle-Compensated Contrastive Regularizer for Deep Regression
Jan 13, 2025



In deep regression, capturing the relationship among continuous labels in feature space is a fundamental challenge that has attracted increasing interest. Addressing this issue can prevent models from converging to suboptimal solutions across various regression tasks, leading to improved performance, especially for imbalanced regression and under limited sample sizes. However, existing approaches often rely on order-aware representation learning or distance-based weighting. In this paper, we hypothesize a linear negative correlation between label distances and representation similarities in regression tasks. To implement this, we propose an angle-compensated contrastive regularizer for deep regression, which adjusts the cosine distance between anchor and negative samples within the contrastive learning framework. Our method offers a plug-and-play compatible solution that extends most existing contrastive learning methods for regression tasks. Extensive experiments and theoretical analysis demonstrate that our proposed angle-compensated contrastive regularizer not only achieves competitive regression performance but also excels in data efficiency and effectiveness on imbalanced datasets.
Retrieval-Augmented Audio Deepfake Detection
Apr 23, 2024



With recent advances in speech synthesis including text-to-speech (TTS) and voice conversion (VC) systems enabling the generation of ultra-realistic audio deepfakes, there is growing concern about their potential misuse. However, most deepfake (DF) detection methods rely solely on the fuzzy knowledge learned by a single model, resulting in performance bottlenecks and transparency issues. Inspired by retrieval-augmented generation (RAG), we propose a retrieval-augmented detection (RAD) framework that augments test samples with similar retrieved samples for enhanced detection. We also extend the multi-fusion attentive classifier to integrate it with our proposed RAD framework. Extensive experiments show the superior performance of the proposed RAD framework over baseline methods, achieving state-of-the-art results on the ASVspoof 2021 DF set and competitive results on the 2019 and 2021 LA sets. Further sample analysis indicates that the retriever consistently retrieves samples mostly from the same speaker with acoustic characteristics highly consistent with the query audio, thereby improving detection performance.
Cooperative vs. Teleoperation Control of the Steady Hand Eye Robot with Adaptive Sclera Force Control: A Comparative Study
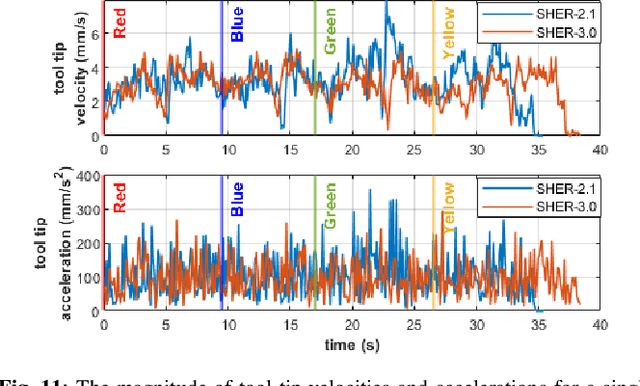
Dec 04, 2023A surgeon's physiological hand tremor can significantly impact the outcome of delicate and precise retinal surgery, such as retinal vein cannulation (RVC) and epiretinal membrane peeling. Robot-assisted eye surgery technology provides ophthalmologists with advanced capabilities such as hand tremor cancellation, hand motion scaling, and safety constraints that enable them to perform these otherwise challenging and high-risk surgeries with high precision and safety. Steady-Hand Eye Robot (SHER) with cooperative control mode can filter out surgeon's hand tremor, yet another important safety feature, that is, minimizing the contact force between the surgical instrument and sclera surface for avoiding tissue damage cannot be met in this control mode. Also, other capabilities, such as hand motion scaling and haptic feedback, require a teleoperation control framework. In this work, for the first time, we implemented a teleoperation control mode incorporated with an adaptive sclera force control algorithm using a PHANTOM Omni haptic device and a force-sensing surgical instrument equipped with Fiber Bragg Grating (FBG) sensors attached to the SHER 2.1 end-effector. This adaptive sclera force control algorithm allows the robot to dynamically minimize the tool-sclera contact force. Moreover, for the first time, we compared the performance of the proposed adaptive teleoperation mode with the cooperative mode by conducting a vessel-following experiment inside an eye phantom under a microscope.
HiFi-Syn: Hierarchical Granularity Discrimination for High-Fidelity Synthesis of MR Images with Structure Preservation
Nov 21, 2023



Synthesizing medical images while preserving their structural information is crucial in medical research. In such scenarios, the preservation of anatomical content becomes especially important. Although recent advances have been made by incorporating instance-level information to guide translation, these methods overlook the spatial coherence of structural-level representation and the anatomical invariance of content during translation. To address these issues, we introduce hierarchical granularity discrimination, which exploits various levels of semantic information present in medical images. Our strategy utilizes three levels of discrimination granularity: pixel-level discrimination using a Brain Memory Bank, structure-level discrimination on each brain structure with a re-weighting strategy to focus on hard samples, and global-level discrimination to ensure anatomical consistency during translation. The image translation performance of our strategy has been evaluated on three independent datasets (UK Biobank, IXI, and BraTS 2018), and it has outperformed state-of-the-art algorithms. Particularly, our model excels not only in synthesizing normal structures but also in handling abnormal (pathological) structures, such as brain tumors, despite the variations in contrast observed across different imaging modalities due to their pathological characteristics. The diagnostic value of synthesized MR images containing brain tumors has been evaluated by radiologists. This indicates that our model may offer an alternative solution in scenarios where specific MR modalities of patients are unavailable. Extensive experiments further demonstrate the versatility of our method, providing unique insights into medical image translation.
Human-Robot Interaction in Retinal Surgery: A Comparative Study of Serial and Parallel Cooperative Robots
Apr 01, 2023


Cooperative robots for intraocular surgery allow surgeons to perform vitreoretinal surgery with high precision and stability. Several robot structural designs have shown capabilities to perform these surgeries. This research investigates the comparative performance of a serial and parallel cooperative-controlled robot in completing a retinal vessel-following task, with a focus on human-robot interaction performance and user experience. Our results indicate that despite differences in robot structure and interaction forces and torques, the two robots exhibited similar levels of performance in terms of general robot-to-patient interaction and average operating time. These findings have implications for the development and implementation of surgical robotics, suggesting that both serial and parallel cooperative-controlled robots can be effective for vitreoretinal surgery tasks.
Denoising of 3D MR images using a voxel-wise hybrid residual MLP-CNN model to improve small lesion diagnostic confidence
Sep 28, 2022Small lesions in magnetic resonance imaging (MRI) images are crucial for clinical diagnosis of many kinds of diseases. However, the MRI quality can be easily degraded by various noise, which can greatly affect the accuracy of diagnosis of small lesion. Although some methods for denoising MR images have been proposed, task-specific denoising methods for improving the diagnosis confidence of small lesions are lacking. In this work, we propose a voxel-wise hybrid residual MLP-CNN model to denoise three-dimensional (3D) MR images with small lesions. We combine basic deep learning architecture, MLP and CNN, to obtain an appropriate inherent bias for the image denoising and integrate each output layers in MLP and CNN by adding residual connections to leverage long-range information. We evaluate the proposed method on 720 T2-FLAIR brain images with small lesions at different noise levels. The results show the superiority of our method in both quantitative and visual evaluations on testing dataset compared to state-of-the-art methods. Moreover, two experienced radiologists agreed that at moderate and high noise levels, our method outperforms other methods in terms of recovery of small lesions and overall image denoising quality. The implementation of our method is available at https://github.com/laowangbobo/Residual_MLP_CNN_Mixer.
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-shot Multi-speaker Text-to-Speech
Feb 22, 2022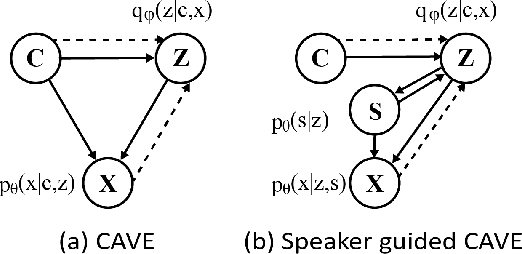
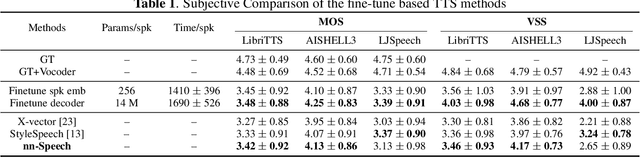
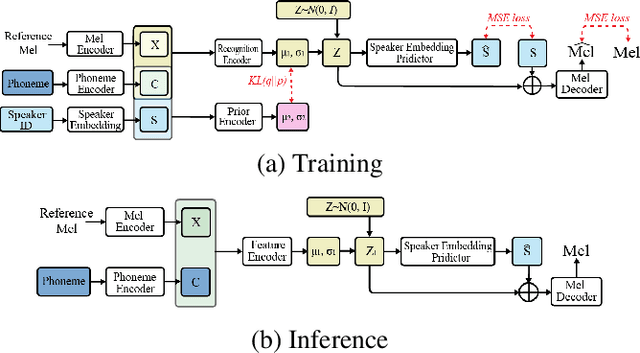
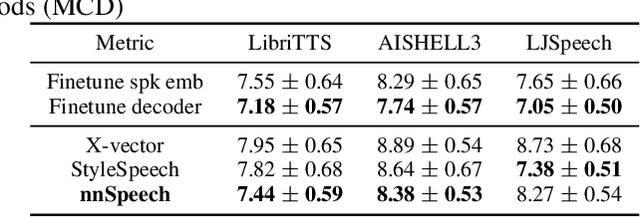
Multi-speaker text-to-speech (TTS) using a few adaption data is a challenge in practical applications. To address that, we propose a zero-shot multi-speaker TTS, named nnSpeech, that could synthesis a new speaker voice without fine-tuning and using only one adaption utterance. Compared with using a speaker representation module to extract the characteristics of new speakers, our method bases on a speaker-guided conditional variational autoencoder and can generate a variable Z, which contains both speaker characteristics and content information. The latent variable Z distribution is approximated by another variable conditioned on reference mel-spectrogram and phoneme. Experiments on the English corpus, Mandarin corpus, and cross-dataset proves that our model could generate natural and similar speech with only one adaption speech.