 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
Oct 02, 2025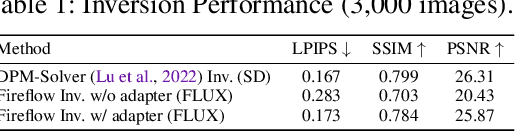
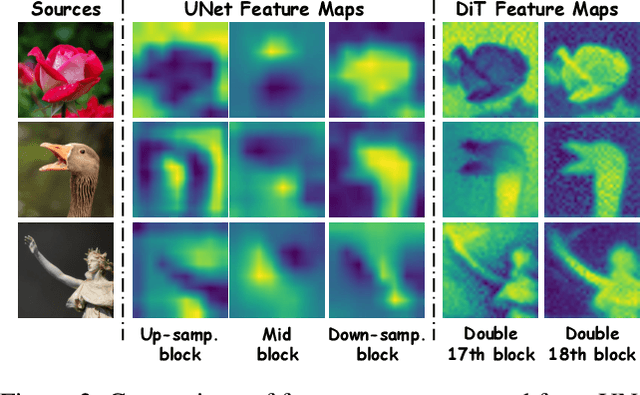
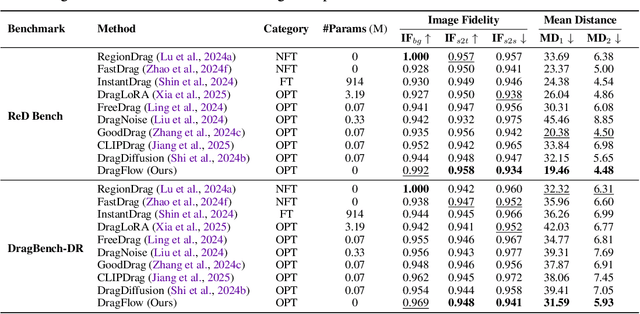
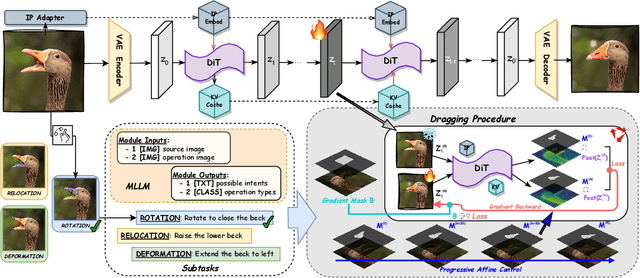
Drag-based image editing has long suffered from distortions in the target region, largely because the priors of earlier base models, Stable Diffusion, are insufficient to project optimized latents back onto the natural image manifold. With the shift from UNet-based DDPMs to more scalable DiT with flow matching (e.g., SD3.5, FLUX), generative priors have become significantly stronger, enabling advances across diverse editing tasks. However, drag-based editing has yet to benefit from these stronger priors. This work proposes the first framework to effectively harness FLUX's rich prior for drag-based editing, dubbed DragFlow, achieving substantial gains over baselines. We first show that directly applying point-based drag editing to DiTs performs poorly: unlike the highly compressed features of UNets, DiT features are insufficiently structured to provide reliable guidance for point-wise motion supervision. To overcome this limitation, DragFlow introduces a region-based editing paradigm, where affine transformations enable richer and more consistent feature supervision. Additionally, we integrate pretrained open-domain personalization adapters (e.g., IP-Adapter) to enhance subject consistency, while preserving background fidelity through gradient mask-based hard constraints. Multimodal large language models (MLLMs) are further employed to resolve task ambiguities. For evaluation, we curate a novel Region-based Dragging benchmark (ReD Bench) featuring region-level dragging instructions. Extensive experiments on DragBench-DR and ReD Bench show that DragFlow surpasses both point-based and region-based baselines, setting a new state-of-the-art in drag-based image editing. Code and datasets will be publicly available upon publication.
Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted Concepts
Apr 17, 2025Ensuring the ethical deployment of text-to-image models requires effective techniques to prevent the generation of harmful or inappropriate content. While concept erasure methods offer a promising solution, existing finetuning-based approaches suffer from notable limitations. Anchor-free methods risk disrupting sampling trajectories, leading to visual artifacts, while anchor-based methods rely on the heuristic selection of anchor concepts. To overcome these shortcomings, we introduce a finetuning framework, dubbed ANT, which Automatically guides deNoising Trajectories to avoid unwanted concepts. ANT is built on a key insight: reversing the condition direction of classifier-free guidance during mid-to-late denoising stages enables precise content modification without sacrificing early-stage structural integrity. This inspires a trajectory-aware objective that preserves the integrity of the early-stage score function field, which steers samples toward the natural image manifold, without relying on heuristic anchor concept selection. For single-concept erasure, we propose an augmentation-enhanced weight saliency map to precisely identify the critical parameters that most significantly contribute to the unwanted concept, enabling more thorough and efficient erasure. For multi-concept erasure, our objective function offers a versatile plug-and-play solution that significantly boosts performance. Extensive experiments demonstrate that ANT achieves state-of-the-art results in both single and multi-concept erasure, delivering high-quality, safe outputs without compromising the generative fidelity. Code is available at https://github.com/lileyang1210/ANT
Temporal-Guided Spiking Neural Networks for Event-Based Human Action Recognition
Mar 21, 2025



This paper explores the promising interplay between spiking neural networks (SNNs) and event-based cameras for privacy-preserving human action recognition (HAR). The unique feature of event cameras in capturing only the outlines of motion, combined with SNNs' proficiency in processing spatiotemporal data through spikes, establishes a highly synergistic compatibility for event-based HAR. Previous studies, however, have been limited by SNNs' ability to process long-term temporal information, essential for precise HAR. In this paper, we introduce two novel frameworks to address this: temporal segment-based SNN (\textit{TS-SNN}) and 3D convolutional SNN (\textit{3D-SNN}). The \textit{TS-SNN} extracts long-term temporal information by dividing actions into shorter segments, while the \textit{3D-SNN} replaces 2D spatial elements with 3D components to facilitate the transmission of temporal information. To promote further research in event-based HAR, we create a dataset, \textit{FallingDetection-CeleX}, collected using the high-resolution CeleX-V event camera $(1280 \times 800)$, comprising 7 distinct actions. Extensive experimental results show that our proposed frameworks surpass state-of-the-art SNN methods on our newly collected dataset and three other neuromorphic datasets, showcasing their effectiveness in handling long-range temporal information for event-based HAR.
All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian Splatting
Mar 10, 2025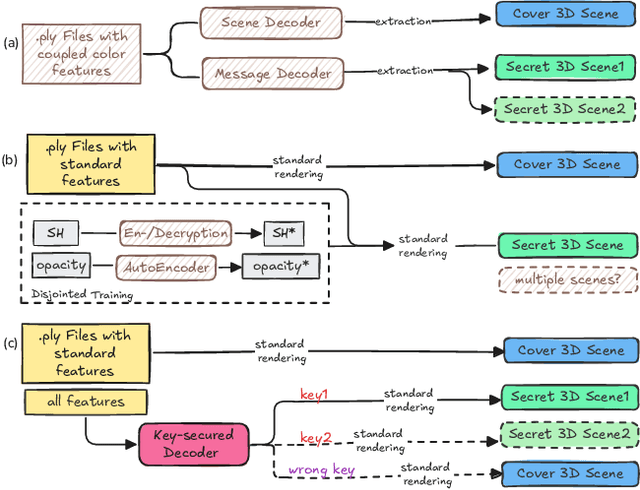



Recent advances in 3D Gaussian Splatting (3DGS) have revolutionized scene reconstruction, opening new possibilities for 3D steganography by hiding 3D secrets within 3D covers. The key challenge in steganography is ensuring imperceptibility while maintaining high-fidelity reconstruction. However, existing methods often suffer from detectability risks and utilize only suboptimal 3DGS features, limiting their full potential. We propose a novel end-to-end key-secured 3D steganography framework (KeySS) that jointly optimizes a 3DGS model and a key-secured decoder for secret reconstruction. Our approach reveals that Gaussian features contribute unequally to secret hiding. The framework incorporates a key-controllable mechanism enabling multi-secret hiding and unauthorized access prevention, while systematically exploring optimal feature update to balance fidelity and security. To rigorously evaluate steganographic imperceptibility beyond conventional 2D metrics, we introduce 3D-Sinkhorn distance analysis, which quantifies distributional differences between original and steganographic Gaussian parameters in the representation space. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both cover and secret reconstruction while maintaining high security levels, advancing the field of 3D steganography. Code is available at https://github.com/RY-Paper/KeySS
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Dec 29, 2024Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (\textit{e.g.}, SD v1.4). In this work, we introduce \logopic \textbf{EraseAnything}, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
OFTSR: One-Step Flow for Image Super-Resolution with Tunable Fidelity-Realism Trade-offs
Dec 12, 2024



Recent advances in diffusion and flow-based generative models have demonstrated remarkable success in image restoration tasks, achieving superior perceptual quality compared to traditional deep learning approaches. However, these methods either require numerous sampling steps to generate high-quality images, resulting in significant computational overhead, or rely on model distillation, which usually imposes a fixed fidelity-realism trade-off and thus lacks flexibility. In this paper, we introduce OFTSR, a novel flow-based framework for one-step image super-resolution that can produce outputs with tunable levels of fidelity and realism. Our approach first trains a conditional flow-based super-resolution model to serve as a teacher model. We then distill this teacher model by applying a specialized constraint. Specifically, we force the predictions from our one-step student model for same input to lie on the same sampling ODE trajectory of the teacher model. This alignment ensures that the student model's single-step predictions from initial states match the teacher's predictions from a closer intermediate state. Through extensive experiments on challenging datasets including FFHQ (256$\times$256), DIV2K, and ImageNet (256$\times$256), we demonstrate that OFTSR achieves state-of-the-art performance for one-step image super-resolution, while having the ability to flexibly tune the fidelity-realism trade-off. Code and pre-trained models are available at https://github.com/yuanzhi-zhu/OFTSR and https://huggingface.co/Yuanzhi/OFTSR, respectively.
Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Advances
Oct 24, 2024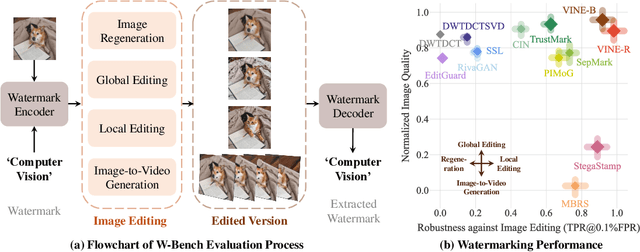
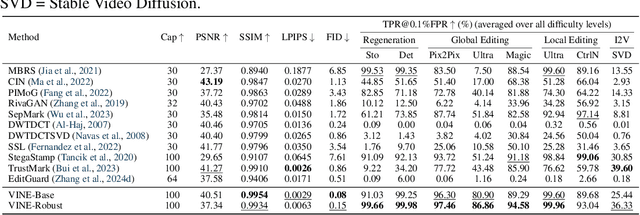
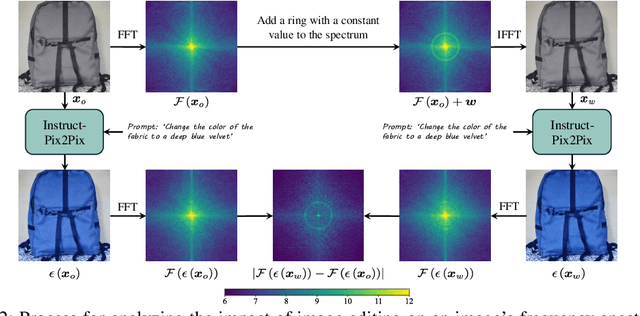
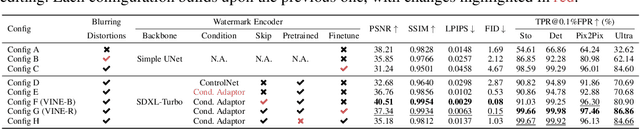
Current image watermarking methods are vulnerable to advanced image editing techniques enabled by large-scale text-to-image models. These models can distort embedded watermarks during editing, posing significant challenges to copyright protection. In this work, we introduce W-Bench, the first comprehensive benchmark designed to evaluate the robustness of watermarking methods against a wide range of image editing techniques, including image regeneration, global editing, local editing, and image-to-video generation. Through extensive evaluations of eleven representative watermarking methods against prevalent editing techniques, we demonstrate that most methods fail to detect watermarks after such edits. To address this limitation, we propose VINE, a watermarking method that significantly enhances robustness against various image editing techniques while maintaining high image quality. Our approach involves two key innovations: (1) we analyze the frequency characteristics of image editing and identify that blurring distortions exhibit similar frequency properties, which allows us to use them as surrogate attacks during training to bolster watermark robustness; (2) we leverage a large-scale pretrained diffusion model SDXL-Turbo, adapting it for the watermarking task to achieve more imperceptible and robust watermark embedding. Experimental results show that our method achieves outstanding watermarking performance under various image editing techniques, outperforming existing methods in both image quality and robustness. Code is available at https://github.com/Shilin-LU/VINE.
MACE: Mass Concept Erasure in Diffusion Models
Mar 10, 2024

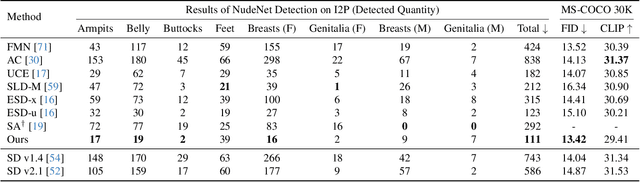
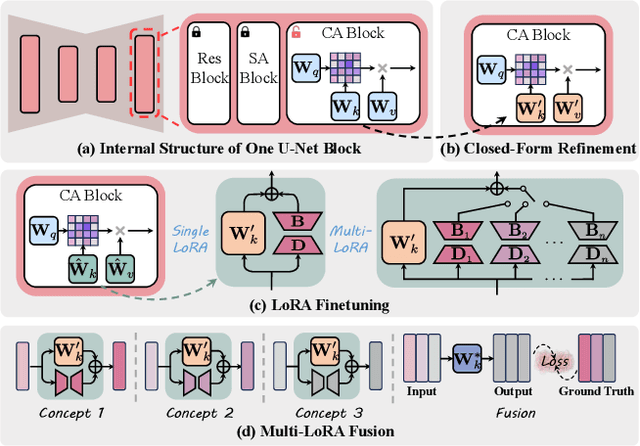
The rapid expansion of large-scale text-to-image diffusion models has raised growing concerns regarding their potential misuse in creating harmful or misleading content. In this paper, we introduce MACE, a finetuning framework for the task of mass concept erasure. This task aims to prevent models from generating images that embody unwanted concepts when prompted. Existing concept erasure methods are typically restricted to handling fewer than five concepts simultaneously and struggle to find a balance between erasing concept synonyms (generality) and maintaining unrelated concepts (specificity). In contrast, MACE differs by successfully scaling the erasure scope up to 100 concepts and by achieving an effective balance between generality and specificity. This is achieved by leveraging closed-form cross-attention refinement along with LoRA finetuning, collectively eliminating the information of undesirable concepts. Furthermore, MACE integrates multiple LoRAs without mutual interference. We conduct extensive evaluations of MACE against prior methods across four different tasks: object erasure, celebrity erasure, explicit content erasure, and artistic style erasure. Our results reveal that MACE surpasses prior methods in all evaluated tasks. Code is available at https://github.com/Shilin-LU/MACE.
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
Jul 25, 2023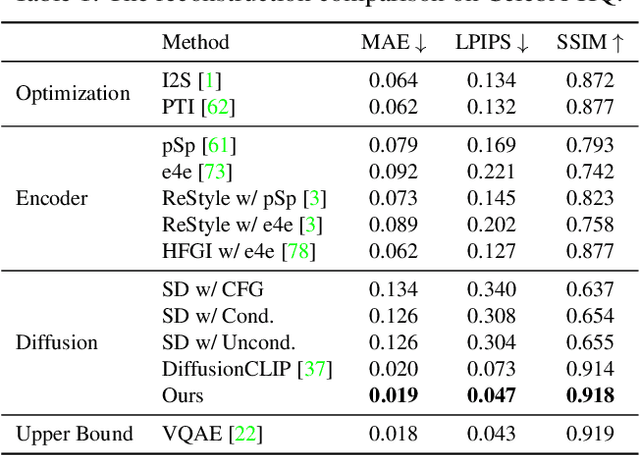
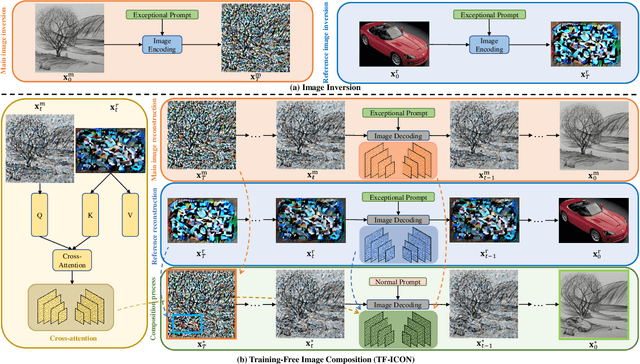
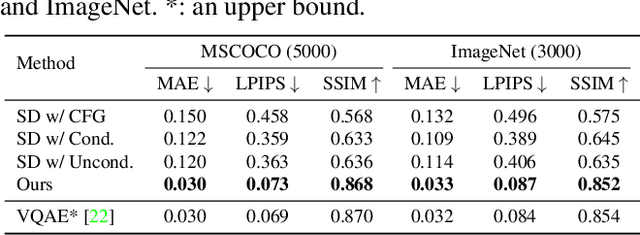

Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains. Code is available at https://github.com/Shilin-LU/TF-ICON
Copy-Move Image Forgery Detection Based on Evolving Circular Domains Coverage
Sep 09, 2021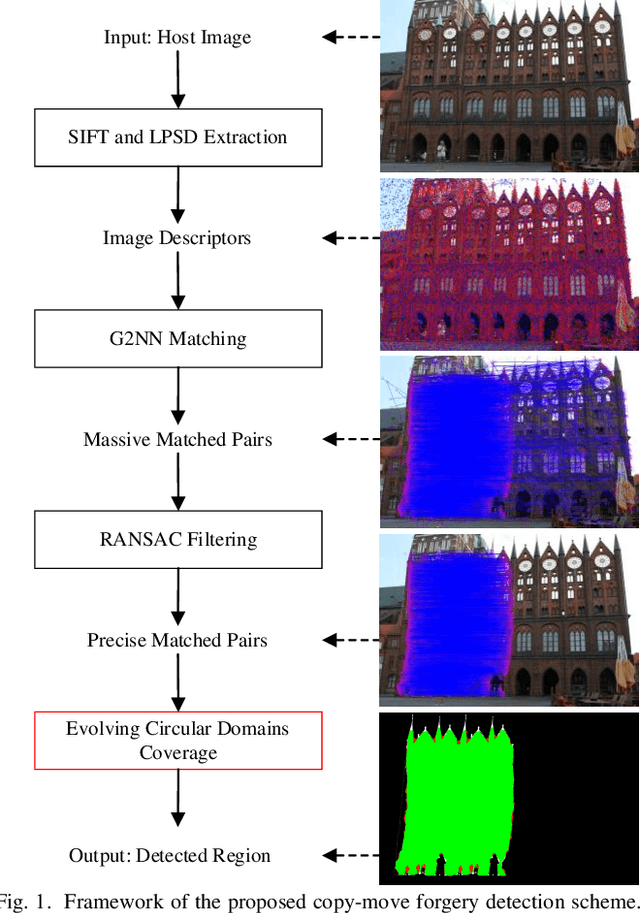
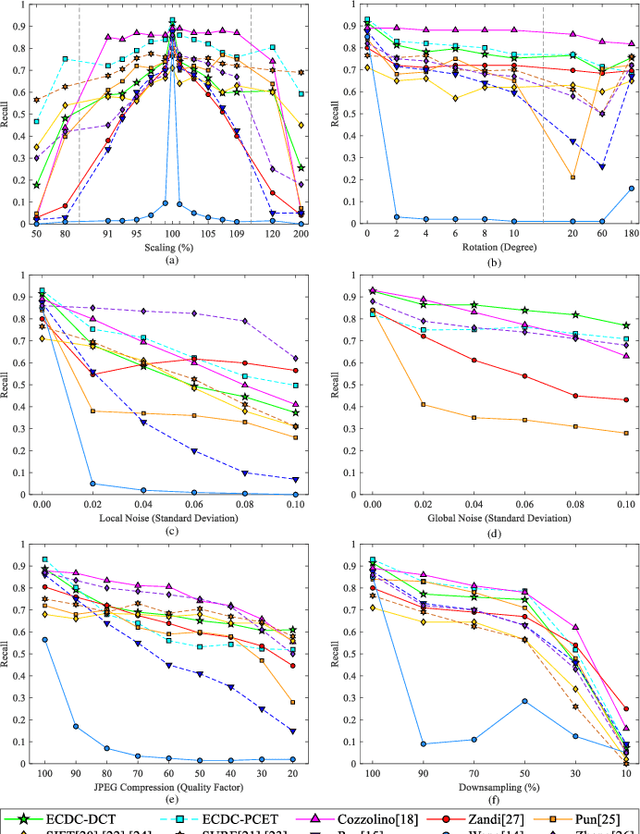
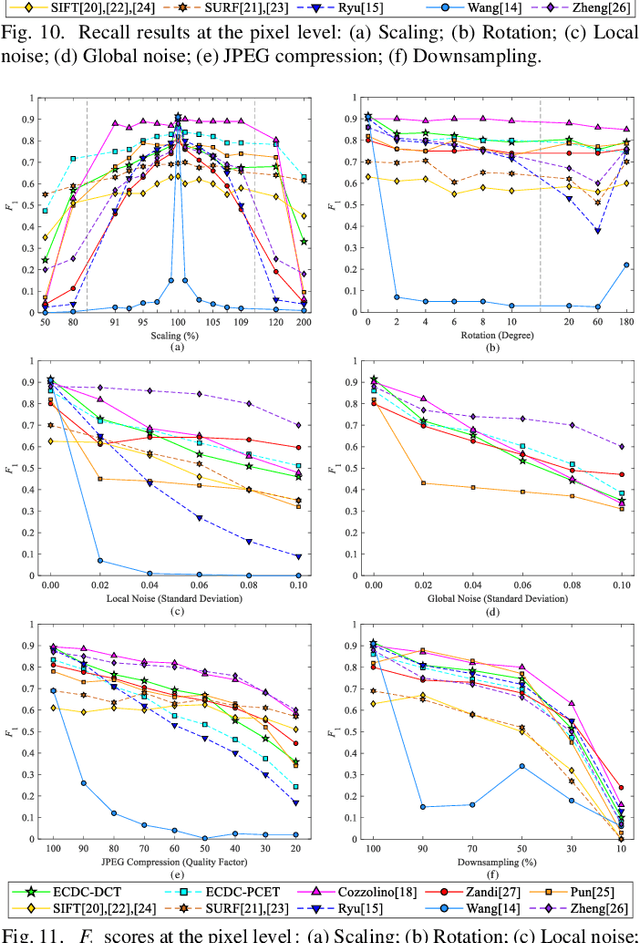

The aim of this paper is to improve the accuracy of copy-move forgery detection (CMFD) in image forensics by proposing a novel scheme. The proposed scheme integrates both block-based and keypoint-based forgery detection methods. Firstly, speed-up robust feature (SURF) descriptor in log-polar space and scale invariant feature transform (SIFT) descriptor are extracted from an entire forged image. Secondly, generalized 2 nearest neighbor (g2NN) is employed to get massive matched pairs. Then, random sample consensus (RANSAC) algorithm is employed to filter out mismatched pairs, thus allowing rough localization of the counterfeit areas. To present more accurately these forgery areas more accurately, we propose an efficient and accurate algorithm, evolving circular domains coverage (ECDC), to cover present them. This algorithm aims to find satisfactory threshold areas by extracting block features from jointly evolving circular domains, which are centered on the matched pairs. Finally, morphological operation is applied to refine the detected forgery areas. The experimental results indicate that the proposed CMFD scheme can achieve better detection performance under various attacks compared with other state-of-the-art CMFD schemes.