 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleeperMark: Towards Robust Watermark against Fine-Tuning Text-to-image Diffusion Models
Dec 06, 2024



Recent advances in large-scale text-to-image (T2I) diffusion models have enabled a variety of downstream applications, including style customization, subject-driven personalization, and conditional generation. As T2I models require extensive data and computational resources for training, they constitute highly valued intellectual property (IP) for their legitimate owners, yet making them incentive targets for unauthorized fine-tuning by adversaries seeking to leverage these models for customized, usually profitable applications. Existing IP protection methods for diffusion models generally involve embedding watermark patterns and then verifying ownership through generated outputs examination, or inspecting the model's feature space. However, these techniques are inherently ineffective in practical scenarios when the watermarked model undergoes fine-tuning, and the feature space is inaccessible during verification ((i.e., black-box setting). The model is prone to forgetting the previously learned watermark knowledge when it adapts to a new task. To address this challenge, we propose SleeperMark, a novel framework designed to embed resilient watermarks into T2I diffusion models. SleeperMark explicitly guides the model to disentangle the watermark information from the semantic concepts it learns, allowing the model to retain the embedded watermark while continuing to be fine-tuned to new downstream tasks. Our extensive experiments demonstrate the effectiveness of SleeperMark across various types of diffusion models, including latent diffusion models (e.g., Stable Diffusion) and pixel diffusion models (e.g., DeepFloyd-IF), showing robustness against downstream fine-tuning and various attacks at both the image and model levels, with minimal impact on the model's generative capability. The code is available at https://github.com/taco-group/SleeperMark.
MACE: Mass Concept Erasure in Diffusion Models
Mar 10, 2024

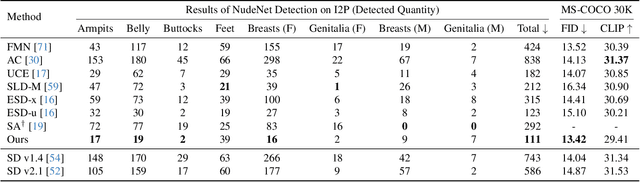
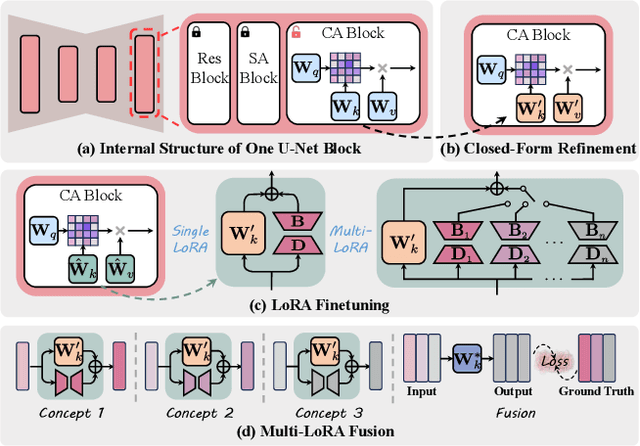
The rapid expansion of large-scale text-to-image diffusion models has raised growing concerns regarding their potential misuse in creating harmful or misleading content. In this paper, we introduce MACE, a finetuning framework for the task of mass concept erasure. This task aims to prevent models from generating images that embody unwanted concepts when prompted. Existing concept erasure methods are typically restricted to handling fewer than five concepts simultaneously and struggle to find a balance between erasing concept synonyms (generality) and maintaining unrelated concepts (specificity). In contrast, MACE differs by successfully scaling the erasure scope up to 100 concepts and by achieving an effective balance between generality and specificity. This is achieved by leveraging closed-form cross-attention refinement along with LoRA finetuning, collectively eliminating the information of undesirable concepts. Furthermore, MACE integrates multiple LoRAs without mutual interference. We conduct extensive evaluations of MACE against prior methods across four different tasks: object erasure, celebrity erasure, explicit content erasure, and artistic style erasure. Our results reveal that MACE surpasses prior methods in all evaluated tasks. Code is available at https://github.com/Shilin-LU/MACE.