 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Final Component of Generator Architectures for AI-Generated Image Detection
Jan 28, 2026With the rapid proliferation of powerful image generators, accurate detection of AI-generated images has become essential for maintaining a trustworthy online environment. However, existing deepfake detectors often generalize poorly to images produced by unseen generators. Notably, despite being trained under vastly different paradigms, such as diffusion or autoregressive modeling, many modern image generators share common final architectural components that serve as the last stage for converting intermediate representations into images. Motivated by this insight, we propose to "contaminate" real images using the generator's final component and train a detector to distinguish them from the original real images. We further introduce a taxonomy based on generators' final components and categorize 21 widely used generators accordingly, enabling a comprehensive investigation of our method's generalization capability. Using only 100 samples from each of three representative categories, our detector-fine-tuned on the DINOv3 backbone-achieves an average accuracy of 98.83% across 22 testing sets from unseen generators.
MACE: Mass Concept Erasure in Diffusion Models
Mar 10, 2024

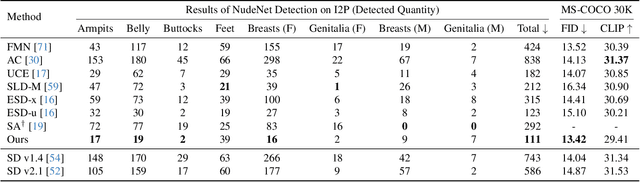
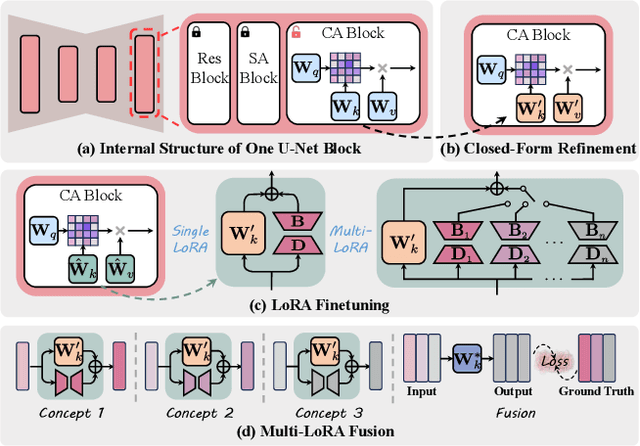
The rapid expansion of large-scale text-to-image diffusion models has raised growing concerns regarding their potential misuse in creating harmful or misleading content. In this paper, we introduce MACE, a finetuning framework for the task of mass concept erasure. This task aims to prevent models from generating images that embody unwanted concepts when prompted. Existing concept erasure methods are typically restricted to handling fewer than five concepts simultaneously and struggle to find a balance between erasing concept synonyms (generality) and maintaining unrelated concepts (specificity). In contrast, MACE differs by successfully scaling the erasure scope up to 100 concepts and by achieving an effective balance between generality and specificity. This is achieved by leveraging closed-form cross-attention refinement along with LoRA finetuning, collectively eliminating the information of undesirable concepts. Furthermore, MACE integrates multiple LoRAs without mutual interference. We conduct extensive evaluations of MACE against prior methods across four different tasks: object erasure, celebrity erasure, explicit content erasure, and artistic style erasure. Our results reveal that MACE surpasses prior methods in all evaluated tasks. Code is available at https://github.com/Shilin-LU/MACE.
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
Jul 25, 2023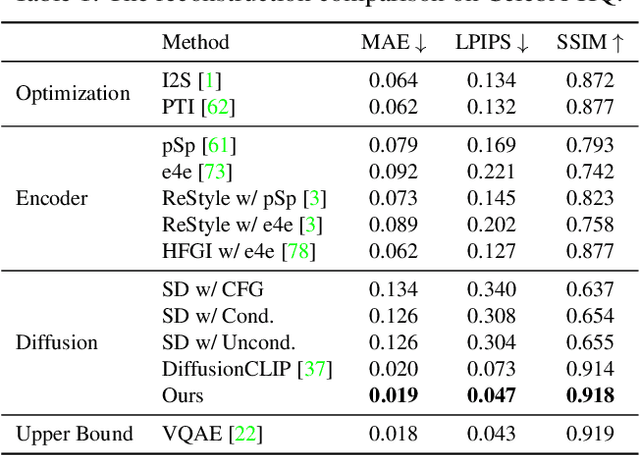
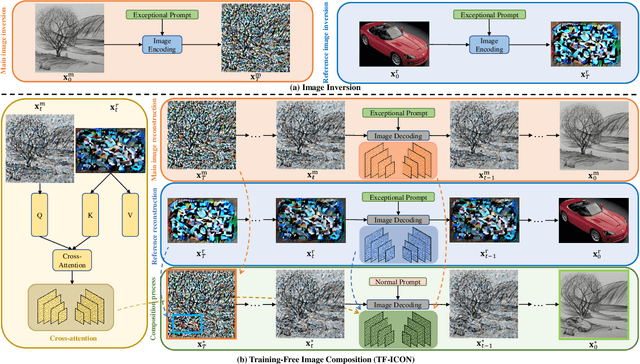
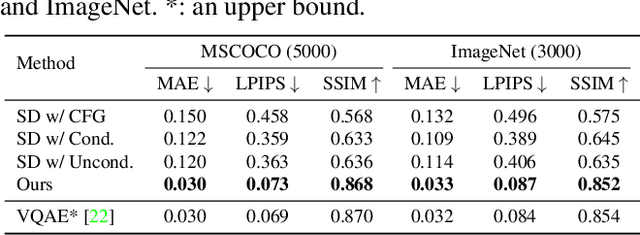

Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains. Code is available at https://github.com/Shilin-LU/TF-ICON