 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Guided Spiking Neural Networks for Event-Based Human Action Recognition
Mar 21, 2025



This paper explores the promising interplay between spiking neural networks (SNNs) and event-based cameras for privacy-preserving human action recognition (HAR). The unique feature of event cameras in capturing only the outlines of motion, combined with SNNs' proficiency in processing spatiotemporal data through spikes, establishes a highly synergistic compatibility for event-based HAR. Previous studies, however, have been limited by SNNs' ability to process long-term temporal information, essential for precise HAR. In this paper, we introduce two novel frameworks to address this: temporal segment-based SNN (\textit{TS-SNN}) and 3D convolutional SNN (\textit{3D-SNN}). The \textit{TS-SNN} extracts long-term temporal information by dividing actions into shorter segments, while the \textit{3D-SNN} replaces 2D spatial elements with 3D components to facilitate the transmission of temporal information. To promote further research in event-based HAR, we create a dataset, \textit{FallingDetection-CeleX}, collected using the high-resolution CeleX-V event camera $(1280 \times 800)$, comprising 7 distinct actions. Extensive experimental results show that our proposed frameworks surpass state-of-the-art SNN methods on our newly collected dataset and three other neuromorphic datasets, showcasing their effectiveness in handling long-range temporal information for event-based HAR.
Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild
Dec 01, 2024



Given a natural language query, video moment retrieval aims to localize the described temporal moment in an untrimmed video. A major challenge of this task is its heavy dependence on labor-intensive annotations for training. Unlike existing works that directly train models on manually curated data, we propose a novel paradigm to reduce annotation costs: pretraining the model on unlabeled, real-world videos. To support this, we introduce Video Moment Retrieval Pretraining (Vid-Morp), a large-scale dataset collected with minimal human intervention, consisting of over 50K videos captured in the wild and 200K pseudo annotations. Direct pretraining on these imperfect pseudo annotations, however, presents significant challenges, including mismatched sentence-video pairs and imprecise temporal boundaries. To address these issues, we propose the ReCorrect algorithm, which comprises two main phases: semantics-guided refinement and memory-consensus correction. The semantics-guided refinement enhances the pseudo labels by leveraging semantic similarity with video frames to clean out unpaired data and make initial adjustments to temporal boundaries. In the following memory-consensus correction phase, a memory bank tracks the model predictions, progressively correcting the temporal boundaries based on consensus within the memory. Comprehensive experiments demonstrate ReCorrect's strong generalization abilities across multiple downstream settings. Zero-shot ReCorrect achieves over 75% and 80% of the best fully-supervised performance on two benchmarks, while unsupervised ReCorrect reaches about 85% on both. The code, dataset, and pretrained models are available at https://github.com/baopj/Vid-Morp.
Skeleton Cloud Colorization for Unsupervised 3D Action Representation Learning
Aug 09, 2021

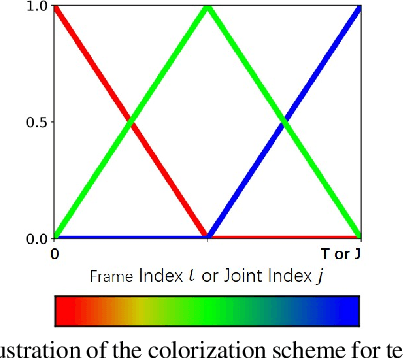
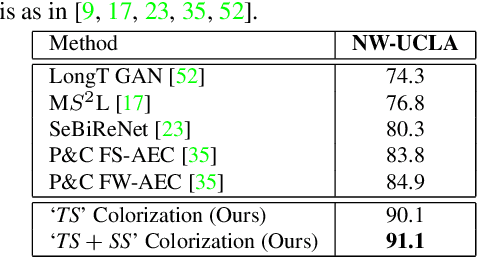
Skeleton-based human action recognition has attracted increasing attention in recent years. However, most of the existing works focus on supervised learning which requiring a large number of annotated action sequences that are often expensive to collect. We investigate unsupervised representation learning for skeleton action recognition, and design a novel skeleton cloud colorization technique that is capable of learning skeleton representations from unlabeled skeleton sequence data. Specifically, we represent a skeleton action sequence as a 3D skeleton cloud and colorize each point in the cloud according to its temporal and spatial orders in the original (unannotated) skeleton sequence. Leveraging the colorized skeleton point cloud, we design an auto-encoder framework that can learn spatial-temporal features from the artificial color labels of skeleton joints effectively. We evaluate our skeleton cloud colorization approach with action classifiers trained under different configurations, including unsupervised, semi-supervised and fully-supervised settings. Extensive experiments on NTU RGB+D and NW-UCLA datasets show that the proposed method outperforms existing unsupervised and semi-supervised 3D action recognition methods by large margins, and it achieves competitive performance in supervised 3D action recognition as well.