 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE.M.Ground: A Temporal Grounding Vid-LLM with Holistic Event Perception and Matching
Feb 05, 2026Despite recent advances in Video Large Language Models (Vid-LLMs), Temporal Video Grounding (TVG), which aims to precisely localize time segments corresponding to query events, remains a significant challenge. Existing methods often match start and end frames by comparing frame features with two separate tokens, relying heavily on exact timestamps. However, this approach fails to capture the event's semantic continuity and integrity, leading to ambiguities. To address this, we propose E.M.Ground, a novel Vid-LLM for TVG that focuses on holistic and coherent event perception. E.M.Ground introduces three key innovations: (i) a special <event> token that aggregates information from all frames of a query event, preserving semantic continuity for accurate event matching; (ii) Savitzky-Golay smoothing to reduce noise in token-to-frame similarities across timestamps, improving prediction accuracy; (iii) multi-grained frame feature aggregation to enhance matching reliability and temporal understanding, compensating for compression-induced information loss. Extensive experiments on benchmark datasets show that E.M.Ground consistently outperforms state-of-the-art Vid-LLMs by significant margins.
Boosting SAM for Cross-Domain Few-Shot Segmentation via Conditional Point Sparsification
Feb 05, 2026Motivated by the success of the Segment Anything Model (SAM) in promptable segmentation, recent studies leverage SAM to develop training-free solutions for few-shot segmentation, which aims to predict object masks in the target image based on a few reference exemplars. These SAM-based methods typically rely on point matching between reference and target images and use the matched dense points as prompts for mask prediction. However, we observe that dense points perform poorly in Cross-Domain Few-Shot Segmentation (CD-FSS), where target images are from medical or satellite domains. We attribute this issue to large domain shifts that disrupt the point-image interactions learned by SAM, and find that point density plays a crucial role under such conditions. To address this challenge, we propose Conditional Point Sparsification (CPS), a training-free approach that adaptively guides SAM interactions for cross-domain images based on reference exemplars. Leveraging ground-truth masks, the reference images provide reliable guidance for adaptively sparsifying dense matched points, enabling more accurate segmentation results. Extensive experiments demonstrate that CPS outperforms existing training-free SAM-based methods across diverse CD-FSS datasets.
Cross-Domain Few-Shot Segmentation via Multi-view Progressive Adaptation
Feb 05, 2026Cross-Domain Few-Shot Segmentation aims to segment categories in data-scarce domains conditioned on a few exemplars. Typical methods first establish few-shot capability in a large-scale source domain and then adapt it to target domains. However, due to the limited quantity and diversity of target samples, existing methods still exhibit constrained performance. Moreover, the source-trained model's initially weak few-shot capability in target domains, coupled with substantial domain gaps, severely hinders the effective utilization of target samples and further impedes adaptation. To this end, we propose Multi-view Progressive Adaptation, which progressively adapts few-shot capability to target domains from both data and strategy perspectives. (i) From the data perspective, we introduce Hybrid Progressive Augmentation, which progressively generates more diverse and complex views through cumulative strong augmentations, thereby creating increasingly challenging learning scenarios. (ii) From the strategy perspective, we design Dual-chain Multi-view Prediction, which fully leverages these progressively complex views through sequential and parallel learning paths under extensive supervision. By jointly enforcing prediction consistency across diverse and complex views, MPA achieves both robust and accurate adaptation to target domains. Extensive experiments demonstrate that MPA effectively adapts few-shot capability to target domains, outperforming state-of-the-art methods by a large margin (+7.0%).
ForensicsSAM: Toward Robust and Unified Image Forgery Detection and Localization Resisting to Adversarial Attack
Aug 10, 2025Parameter-efficient fine-tuning (PEFT) has emerged as a popular strategy for adapting large vision foundation models, such as the Segment Anything Model (SAM) and LLaVA, to downstream tasks like image forgery detection and localization (IFDL). However, existing PEFT-based approaches overlook their vulnerability to adversarial attacks. In this paper, we show that highly transferable adversarial images can be crafted solely via the upstream model, without accessing the downstream model or training data, significantly degrading the IFDL performance. To address this, we propose ForensicsSAM, a unified IFDL framework with built-in adversarial robustness. Our design is guided by three key ideas: (1) To compensate for the lack of forgery-relevant knowledge in the frozen image encoder, we inject forgery experts into each transformer block to enhance its ability to capture forgery artifacts. These forgery experts are always activated and shared across any input images. (2) To detect adversarial images, we design an light-weight adversary detector that learns to capture structured, task-specific artifact in RGB domain, enabling reliable discrimination across various attack methods. (3) To resist adversarial attacks, we inject adversary experts into the global attention layers and MLP modules to progressively correct feature shifts induced by adversarial noise. These adversary experts are adaptively activated by the adversary detector, thereby avoiding unnecessary interference with clean images. Extensive experiments across multiple benchmarks demonstrate that ForensicsSAM achieves superior resistance to various adversarial attack methods, while also delivering state-of-the-art performance in image-level forgery detection and pixel-level forgery localization. The resource is available at https://github.com/siriusPRX/ForensicsSAM.
SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusion
Aug 07, 2025Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model's coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
Prototype-Driven Structure Synergy Network for Remote Sensing Images Segmentation
Aug 06, 2025
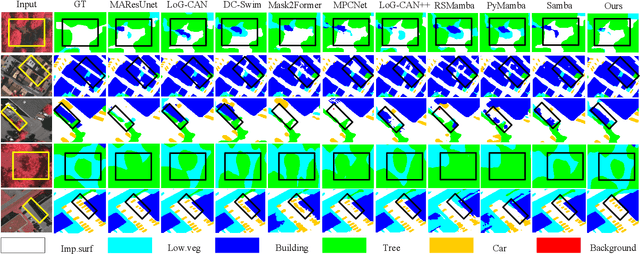
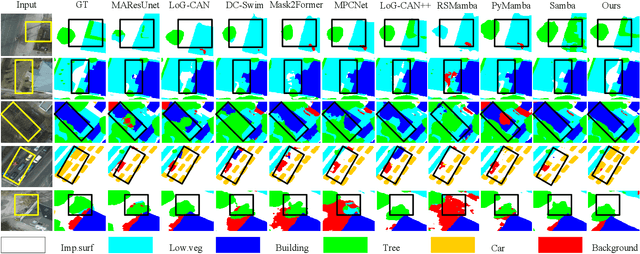
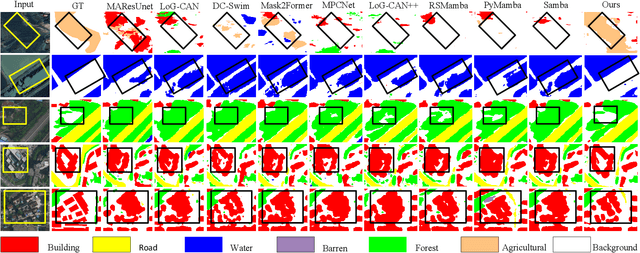
In the semantic segmentation of remote sensing images, acquiring complete ground objects is critical for achieving precise analysis. However, this task is severely hindered by two major challenges: high intra-class variance and high inter-class similarity. Traditional methods often yield incomplete segmentation results due to their inability to effectively unify class representations and distinguish between similar features. Even emerging class-guided approaches are limited by coarse class prototype representations and a neglect of target structural information. Therefore, this paper proposes a Prototype-Driven Structure Synergy Network (PDSSNet). The design of this network is based on a core concept, a complete ground object is jointly defined by its invariant class semantics and its variant spatial structure. To implement this, we have designed three key modules. First, the Adaptive Prototype Extraction Module (APEM) ensures semantic accuracy from the source by encoding the ground truth to extract unbiased class prototypes. Subsequently, the designed Semantic-Structure Coordination Module (SSCM) follows a hierarchical semantics-first, structure-second principle. This involves first establishing a global semantic cognition, then leveraging structural information to constrain and refine the semantic representation, thereby ensuring the integrity of class information. Finally, the Channel Similarity Adjustment Module (CSAM) employs a dynamic step-size adjustment mechanism to focus on discriminative features between classes. Extensive experiments demonstrate that PDSSNet outperforms state-of-the-art methods. The source code is available at https://github.com/wangjunyi-1/PDSSNet.
Temporal Unlearnable Examples: Preventing Personal Video Data from Unauthorized Exploitation by Object Tracking
Jul 10, 2025With the rise of social media, vast amounts of user-uploaded videos (e.g., YouTube) are utilized as training data for Visual Object Tracking (VOT). However, the VOT community has largely overlooked video data-privacy issues, as many private videos have been collected and used for training commercial models without authorization. To alleviate these issues, this paper presents the first investigation on preventing personal video data from unauthorized exploitation by deep trackers. Existing methods for preventing unauthorized data use primarily focus on image-based tasks (e.g., image classification), directly applying them to videos reveals several limitations, including inefficiency, limited effectiveness, and poor generalizability. To address these issues, we propose a novel generative framework for generating Temporal Unlearnable Examples (TUEs), and whose efficient computation makes it scalable for usage on large-scale video datasets. The trackers trained w/ TUEs heavily rely on unlearnable noises for temporal matching, ignoring the original data structure and thus ensuring training video data-privacy. To enhance the effectiveness of TUEs, we introduce a temporal contrastive loss, which further corrupts the learning of existing trackers when using our TUEs for training. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in video data-privacy protection, with strong transferability across VOT models, datasets, and temporal matching tasks.
Active Adversarial Noise Suppression for Image Forgery Localization
Jun 15, 2025Recent advances in deep learning have significantly propelled the development of image forgery localization. However, existing models remain highly vulnerable to adversarial attacks: imperceptible noise added to forged images can severely mislead these models. In this paper, we address this challenge with an Adversarial Noise Suppression Module (ANSM) that generate a defensive perturbation to suppress the attack effect of adversarial noise. We observe that forgery-relevant features extracted from adversarial and original forged images exhibit distinct distributions. To bridge this gap, we introduce Forgery-relevant Features Alignment (FFA) as a first-stage training strategy, which reduces distributional discrepancies by minimizing the channel-wise Kullback-Leibler divergence between these features. To further refine the defensive perturbation, we design a second-stage training strategy, termed Mask-guided Refinement (MgR), which incorporates a dual-mask constraint. MgR ensures that the perturbation remains effective for both adversarial and original forged images, recovering forgery localization accuracy to their original level. Extensive experiments across various attack algorithms demonstrate that our method significantly restores the forgery localization model's performance on adversarial images. Notably, when ANSM is applied to original forged images, the performance remains nearly unaffected. To our best knowledge, this is the first report of adversarial defense in image forgery localization tasks. We have released the source code and anti-forensics dataset.
MTL-UE: Learning to Learn Nothing for Multi-Task Learning
May 08, 2025Most existing unlearnable strategies focus on preventing unauthorized users from training single-task learning (STL) models with personal data. Nevertheless, the paradigm has recently shifted towards multi-task data and multi-task learning (MTL), targeting generalist and foundation models that can handle multiple tasks simultaneously. Despite their growing importance, MTL data and models have been largely neglected while pursuing unlearnable strategies. This paper presents MTL-UE, the first unified framework for generating unlearnable examples for multi-task data and MTL models. Instead of optimizing perturbations for each sample, we design a generator-based structure that introduces label priors and class-wise feature embeddings which leads to much better attacking performance. In addition, MTL-UE incorporates intra-task and inter-task embedding regularization to increase inter-class separation and suppress intra-class variance which enhances the attack robustness greatly. Furthermore, MTL-UE is versatile with good supports for dense prediction tasks in MTL. It is also plug-and-play allowing integrating existing surrogate-dependent unlearnable methods with little adaptation. Extensive experiments show that MTL-UE achieves superior attacking performance consistently across 4 MTL datasets, 3 base UE methods, 5 model backbones, and 5 MTL task-weighting strategies.
Open-set Anomaly Segmentation in Complex Scenarios
Apr 28, 2025Precise segmentation of out-of-distribution (OoD) objects, herein referred to as anomalies, is crucial for the reliable deployment of semantic segmentation models in open-set, safety-critical applications, such as autonomous driving. Current anomalous segmentation benchmarks predominantly focus on favorable weather conditions, resulting in untrustworthy evaluations that overlook the risks posed by diverse meteorological conditions in open-set environments, such as low illumination, dense fog, and heavy rain. To bridge this gap, this paper introduces the ComsAmy, a challenging benchmark specifically designed for open-set anomaly segmentation in complex scenarios. ComsAmy encompasses a wide spectrum of adverse weather conditions, dynamic driving environments, and diverse anomaly types to comprehensively evaluate the model performance in realistic open-world scenarios. Our extensive evaluation of several state-of-the-art anomalous segmentation models reveals that existing methods demonstrate significant deficiencies in such challenging scenarios, highlighting their serious safety risks for real-world deployment. To solve that, we propose a novel energy-entropy learning (EEL) strategy that integrates the complementary information from energy and entropy to bolster the robustness of anomaly segmentation under complex open-world environments. Additionally, a diffusion-based anomalous training data synthesizer is proposed to generate diverse and high-quality anomalous images to enhance the existing copy-paste training data synthesizer. Extensive experimental results on both public and ComsAmy benchmarks demonstrate that our proposed diffusion-based synthesizer with energy and entropy learning (DiffEEL) serves as an effective and generalizable plug-and-play method to enhance existing models, yielding an average improvement of around 4.96% in $\rm{AUPRC}$ and 9.87% in $\rm{FPR}_{95}$.