 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimBase: A Simple Baseline for Temporal Video Grounding
Paper and Code
Nov 12, 2024
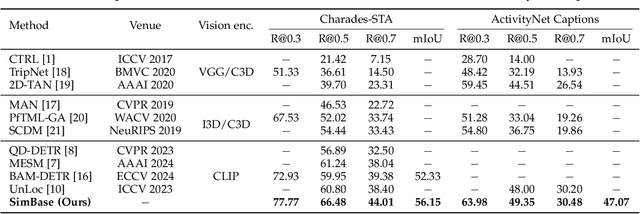
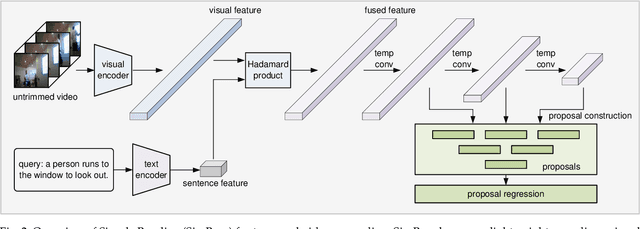
This paper presents SimBase, a simple yet effective baseline for temporal video grounding. While recent advances in temporal grounding have led to impressive performance, they have also driven network architectures toward greater complexity, with a range of methods to (1) capture temporal relationships and (2) achieve effective multimodal fusion. In contrast, this paper explores the question: How effective can a simplified approach be? To investigate, we design SimBase, a network that leverages lightweight, one-dimensional temporal convolutional layers instead of complex temporal structures. For cross-modal interaction, SimBase only employs an element-wise product instead of intricate multimodal fusion. Remarkably, SimBase achieves state-of-the-art results on two large-scale datasets. As a simple yet powerful baseline, we hope SimBase will spark new ideas and streamline future evaluations in temporal video grounding.