 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWBCAtt+: Fine-Grained Pixel-Level Morphological Annotations for White Blood Cell Images
May 19, 2026The microscopic examination of white blood cells (WBCs) plays a fundamental role in pathology and is essential for diagnosing blood disorders such as leukemia and anemia. To support further research on WBC images, multiple datasets have been proposed. However, they mainly annotate cell categories, and lack detailed morphological characteristics that pathologists use to explain their interpretations of cells. To address this gap, we introduce WBCAtt+, a novel dataset of WBC images densely annotated with 11 morphological attributes and five pixel-level cell components. With 113k image-level labels and 10k segmentation maps, WBCAtt+ is the first to provide comprehensive annotations for WBC images. Leveraging this dataset, we provide baseline models for attribute recognition and semantic segmentation. We also design an attribute recognition model to incorporate compositional structure of cells, further improving the recognition performance. Lastly, we showcase various applications enabled by our dataset, such as explainable AI models, including counterfactual example generation. \revision{The dataset and code are publicly available\footnote{https://doi.org/10.57967/hf/8143}}.
Digital Staining with Knowledge Distillation: A Unified Framework for Unpaired and Paired-But-Misaligned Data
Apr 14, 2025Staining is essential in cell imaging and medical diagnostics but poses significant challenges, including high cost, time consumption, labor intensity, and irreversible tissue alterations. Recent advances in deep learning have enabled digital staining through supervised model training. However, collecting large-scale, perfectly aligned pairs of stained and unstained images remains difficult. In this work, we propose a novel unsupervised deep learning framework for digital cell staining that reduces the need for extensive paired data using knowledge distillation. We explore two training schemes: (1) unpaired and (2) paired-but-misaligned settings. For the unpaired case, we introduce a two-stage pipeline, comprising light enhancement followed by colorization, as a teacher model. Subsequently, we obtain a student staining generator through knowledge distillation with hybrid non-reference losses. To leverage the pixel-wise information between adjacent sections, we further extend to the paired-but-misaligned setting, adding the Learning to Align module to utilize pixel-level information. Experiment results on our dataset demonstrate that our proposed unsupervised deep staining method can generate stained images with more accurate positions and shapes of the cell targets in both settings. Compared with competing methods, our method achieves improved results both qualitatively and quantitatively (e.g., NIQE and PSNR).We applied our digital staining method to the White Blood Cell (WBC) dataset, investigating its potential for medical applications.
Towards Robust and Reliable Concept Representations: Reliability-Enhanced Concept Embedding Model
Feb 03, 2025



Concept Bottleneck Models (CBMs) aim to enhance interpretability by predicting human-understandable concepts as intermediates for decision-making. However, these models often face challenges in ensuring reliable concept representations, which can propagate to downstream tasks and undermine robustness, especially under distribution shifts. Two inherent issues contribute to concept unreliability: sensitivity to concept-irrelevant features (e.g., background variations) and lack of semantic consistency for the same concept across different samples. To address these limitations, we propose the Reliability-Enhanced Concept Embedding Model (RECEM), which introduces a two-fold strategy: Concept-Level Disentanglement to separate irrelevant features from concept-relevant information and a Concept Mixup mechanism to ensure semantic alignment across samples. These mechanisms work together to improve concept reliability, enabling the model to focus on meaningful object attributes and generate faithful concept representations. Experimental results demonstrate that RECEM consistently outperforms existing baselines across multiple datasets, showing superior performance under background and domain shifts. These findings highlight the effectiveness of disentanglement and alignment strategies in enhancing both reliability and robustness in CBMs.
Discovering Hidden Visual Concepts Beyond Linguistic Input in Infant Learning
Jan 09, 2025Infants develop complex visual understanding rapidly, even preceding of the acquisition of linguistic inputs. As computer vision seeks to replicate the human vision system, understanding infant visual development may offer valuable insights. In this paper, we present an interdisciplinary study exploring this question: can a computational model that imitates the infant learning process develop broader visual concepts that extend beyond the vocabulary it has heard, similar to how infants naturally learn? To investigate this, we analyze a recently published model in Science by Vong et al.,which is trained on longitudinal, egocentric images of a single child paired with transcribed parental speech. We introduce a training-free framework that can discover visual concept neurons hidden in the model's internal representations. Our findings show that these neurons can classify objects outside its original vocabulary. Furthermore, we compare the visual representations in infant-like models with those in moder computer vision models, such as CLIP or ImageNet pre-trained model, highlighting key similarities and differences. Ultimately, our work bridges cognitive science and computer vision by analyzing the internal representations of a computational model trained on an infant's visual and linguistic inputs.
Integrating Clinical Knowledge into Concept Bottleneck Models
Jul 09, 2024Concept bottleneck models (CBMs), which predict human-interpretable concepts (e.g., nucleus shapes in cell images) before predicting the final output (e.g., cell type), provide insights into the decision-making processes of the model. However, training CBMs solely in a data-driven manner can introduce undesirable biases, which may compromise prediction performance, especially when the trained models are evaluated on out-of-domain images (e.g., those acquired using different devices). To mitigate this challenge, we propose integrating clinical knowledge to refine CBMs, better aligning them with clinicians' decision-making processes. Specifically, we guide the model to prioritize the concepts that clinicians also prioritize. We validate our approach on two datasets of medical images: white blood cell and skin images. Empirical validation demonstrates that incorporating medical guidance enhances the model's classification performance on unseen datasets with varying preparation methods, thereby increasing its real-world applicability.
Evolving Storytelling: Benchmarks and Methods for New Character Customization with Diffusion Models
May 20, 2024Diffusion-based models for story visualization have shown promise in generating content-coherent images for storytelling tasks. However, how to effectively integrate new characters into existing narratives while maintaining character consistency remains an open problem, particularly with limited data. Two major limitations hinder the progress: (1) the absence of a suitable benchmark due to potential character leakage and inconsistent text labeling, and (2) the challenge of distinguishing between new and old characters, leading to ambiguous results. To address these challenges, we introduce the NewEpisode benchmark, comprising refined datasets designed to evaluate generative models' adaptability in generating new stories with fresh characters using just a single example story. The refined dataset involves refined text prompts and eliminates character leakage. Additionally, to mitigate the character confusion of generated results, we propose EpicEvo, a method that customizes a diffusion-based visual story generation model with a single story featuring the new characters seamlessly integrating them into established character dynamics. EpicEvo introduces a novel adversarial character alignment module to align the generated images progressively in the diffusive process, with exemplar images of new characters, while applying knowledge distillation to prevent forgetting of characters and background details. Our evaluation quantitatively demonstrates that EpicEvo outperforms existing baselines on the NewEpisode benchmark, and qualitative studies confirm its superior customization of visual story generation in diffusion models. In summary, EpicEvo provides an effective way to incorporate new characters using only one example story, unlocking new possibilities for applications such as serialized cartoons.
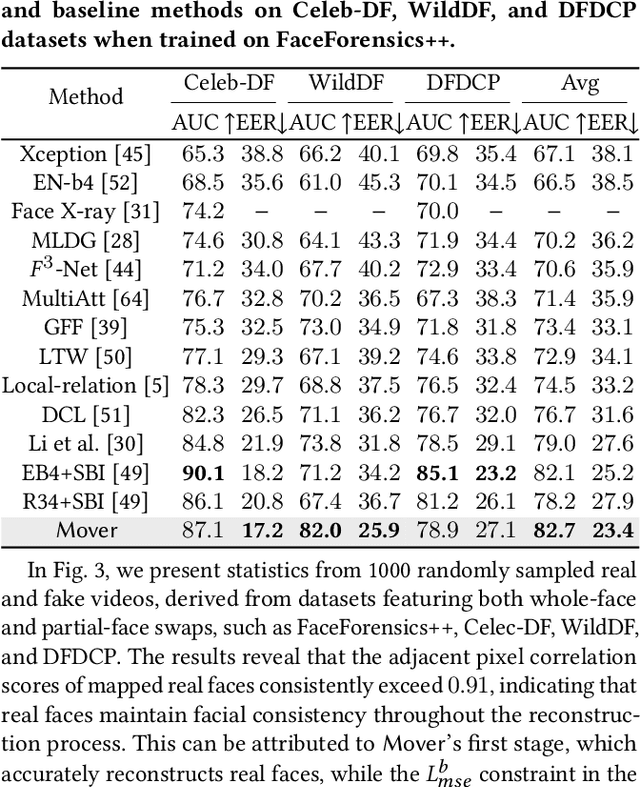
Delocate: Detection and Localization for Deepfake Videos with Randomly-Located Tampered Traces
Jan 24, 2024Deepfake videos are becoming increasingly realistic, showing subtle tampering traces on facial areasthat vary between frames. Consequently, many existing Deepfake detection methods struggle to detect unknown domain Deepfake videos while accurately locating the tampered region. To address thislimitation, we propose Delocate, a novel Deepfake detection model that can both recognize andlocalize unknown domain Deepfake videos. Ourmethod consists of two stages named recoveringand localization. In the recovering stage, the modelrandomly masks regions of interest (ROIs) and reconstructs real faces without tampering traces, resulting in a relatively good recovery effect for realfaces and a poor recovery effect for fake faces. Inthe localization stage, the output of the recoveryphase and the forgery ground truth mask serve assupervision to guide the forgery localization process. This process strategically emphasizes the recovery phase of fake faces with poor recovery, facilitating the localization of tampered regions. Ourextensive experiments on four widely used benchmark datasets demonstrate that Delocate not onlyexcels in localizing tampered areas but also enhances cross-domain detection performance.
Recap: Detecting Deepfake Video with Unpredictable Tampered Traces via Recovering Faces and Mapping Recovered Faces
Aug 19, 2023The exploitation of Deepfake techniques for malicious intentions has driven significant research interest in Deepfake detection. Deepfake manipulations frequently introduce random tampered traces, leading to unpredictable outcomes in different facial regions. However, existing detection methods heavily rely on specific forgery indicators, and as the forgery mode improves, these traces become increasingly randomized, resulting in a decline in the detection performance of methods reliant on specific forgery traces. To address the limitation, we propose Recap, a novel Deepfake detection model that exposes unspecific facial part inconsistencies by recovering faces and enlarges the differences between real and fake by mapping recovered faces. In the recovering stage, the model focuses on randomly masking regions of interest (ROIs) and reconstructing real faces without unpredictable tampered traces, resulting in a relatively good recovery effect for real faces while a poor recovery effect for fake faces. In the mapping stage, the output of the recovery phase serves as supervision to guide the facial mapping process. This mapping process strategically emphasizes the mapping of fake faces with poor recovery, leading to a further deterioration in their representation, while enhancing and refining the mapping of real faces with good representation. As a result, this approach significantly amplifies the discrepancies between real and fake videos. Our extensive experiments on standard benchmarks demonstrate that Recap is effective in multiple scenarios.
WBCAtt: A White Blood Cell Dataset Annotated with Detailed Morphological Attributes
Jun 23, 2023



The examination of blood samples at a microscopic level plays a fundamental role in clinical diagnostics, influencing a wide range of medical conditions. For instance, an in-depth study of White Blood Cells (WBCs), a crucial component of our blood, is essential for diagnosing blood-related diseases such as leukemia and anemia. While multiple datasets containing WBC images have been proposed, they mostly focus on cell categorization, often lacking the necessary morphological details to explain such categorizations, despite the importance of explainable artificial intelligence (XAI) in medical domains. This paper seeks to address this limitation by introducing comprehensive annotations for WBC images. Through collaboration with pathologists, a thorough literature review, and manual inspection of microscopic images, we have identified 11 morphological attributes associated with the cell and its components (nucleus, cytoplasm, and granules). We then annotated ten thousand WBC images with these attributes. Moreover, we conduct experiments to predict these attributes from images, providing insights beyond basic WBC classification. As the first public dataset to offer such extensive annotations, we also illustrate specific applications that can benefit from our attribute annotations. Overall, our dataset paves the way for interpreting WBC recognition models, further advancing XAI in the fields of pathology and hematology.
DeepfakeMAE: Facial Part Consistency Aware Masked Autoencoder for Deepfake Video Detection
Mar 03, 2023


Deepfake techniques have been used maliciously, resulting in strong research interests in developing Deepfake detection methods. Deepfake often manipulates the video content by tampering with some facial parts. However, this manipulation usually breaks the consistency among facial parts, e.g., Deepfake may change smiling lips to upset, but the eyes are still smiling. Existing works propose to spot inconsistency on some specific facial parts (e.g., lips), but they may perform poorly if new Deepfake techniques focus on the specific facial parts used by the detector. Thus, this paper proposes a new Deepfake detection model, DeepfakeMAE, which can utilize the consistencies among all facial parts. Specifically, given a real face image, we first pretrain a masked autoencoder to learn facial part consistency by randomly masking some facial parts and reconstructing missing areas based on the remaining facial parts. Furthermore, to maximize the discrepancy between real and fake videos, we propose a novel model with dual networks that utilize the pretrained encoder and decoder, respectively. 1) The pretrained encoder is finetuned for capturing the overall information of the given video. 2) The pretrained decoder is utilized for distinguishing real and fake videos based on the motivation that DeepfakeMAE's reconstruction should be more similar to a real face image than a fake one. Our extensive experiments on standard benchmarks demonstrate that DeepfakeMAE is highly effective and especially outperforms the previous state-of-the-art method by 3.1% AUC on average in cross-dataset detection.