 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelocate: Detection and Localization for Deepfake Videos with Randomly-Located Tampered Traces
Jan 24, 2024Deepfake videos are becoming increasingly realistic, showing subtle tampering traces on facial areasthat vary between frames. Consequently, many existing Deepfake detection methods struggle to detect unknown domain Deepfake videos while accurately locating the tampered region. To address thislimitation, we propose Delocate, a novel Deepfake detection model that can both recognize andlocalize unknown domain Deepfake videos. Ourmethod consists of two stages named recoveringand localization. In the recovering stage, the modelrandomly masks regions of interest (ROIs) and reconstructs real faces without tampering traces, resulting in a relatively good recovery effect for realfaces and a poor recovery effect for fake faces. Inthe localization stage, the output of the recoveryphase and the forgery ground truth mask serve assupervision to guide the forgery localization process. This process strategically emphasizes the recovery phase of fake faces with poor recovery, facilitating the localization of tampered regions. Ourextensive experiments on four widely used benchmark datasets demonstrate that Delocate not onlyexcels in localizing tampered areas but also enhances cross-domain detection performance.
Recap: Detecting Deepfake Video with Unpredictable Tampered Traces via Recovering Faces and Mapping Recovered Faces
Aug 19, 2023The exploitation of Deepfake techniques for malicious intentions has driven significant research interest in Deepfake detection. Deepfake manipulations frequently introduce random tampered traces, leading to unpredictable outcomes in different facial regions. However, existing detection methods heavily rely on specific forgery indicators, and as the forgery mode improves, these traces become increasingly randomized, resulting in a decline in the detection performance of methods reliant on specific forgery traces. To address the limitation, we propose Recap, a novel Deepfake detection model that exposes unspecific facial part inconsistencies by recovering faces and enlarges the differences between real and fake by mapping recovered faces. In the recovering stage, the model focuses on randomly masking regions of interest (ROIs) and reconstructing real faces without unpredictable tampered traces, resulting in a relatively good recovery effect for real faces while a poor recovery effect for fake faces. In the mapping stage, the output of the recovery phase serves as supervision to guide the facial mapping process. This mapping process strategically emphasizes the mapping of fake faces with poor recovery, leading to a further deterioration in their representation, while enhancing and refining the mapping of real faces with good representation. As a result, this approach significantly amplifies the discrepancies between real and fake videos. Our extensive experiments on standard benchmarks demonstrate that Recap is effective in multiple scenarios.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023
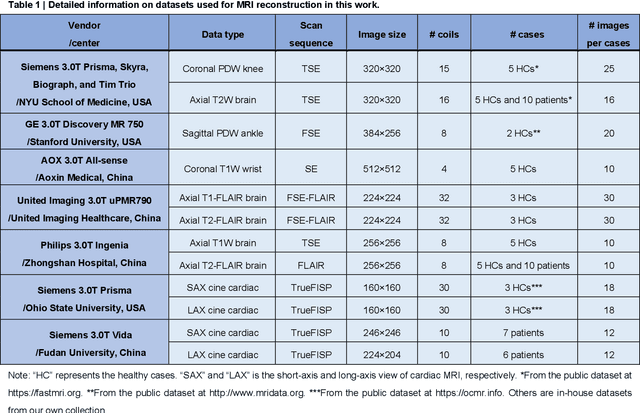
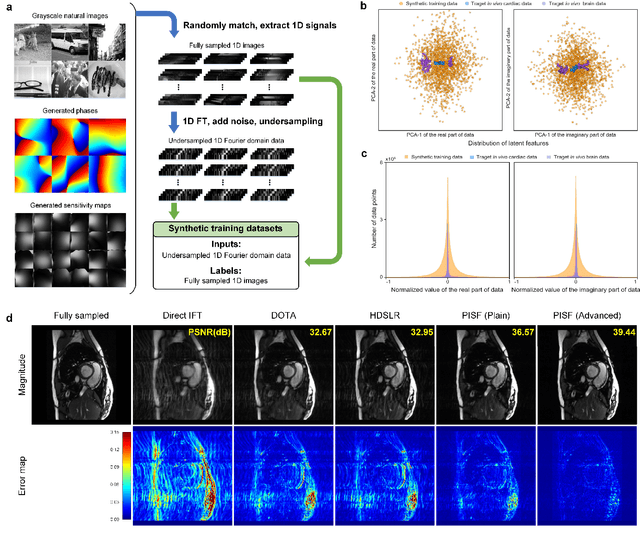
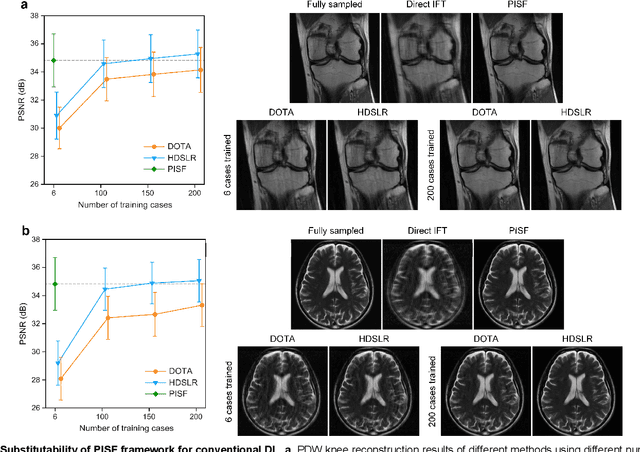
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.
DeepfakeMAE: Facial Part Consistency Aware Masked Autoencoder for Deepfake Video Detection
Mar 03, 2023
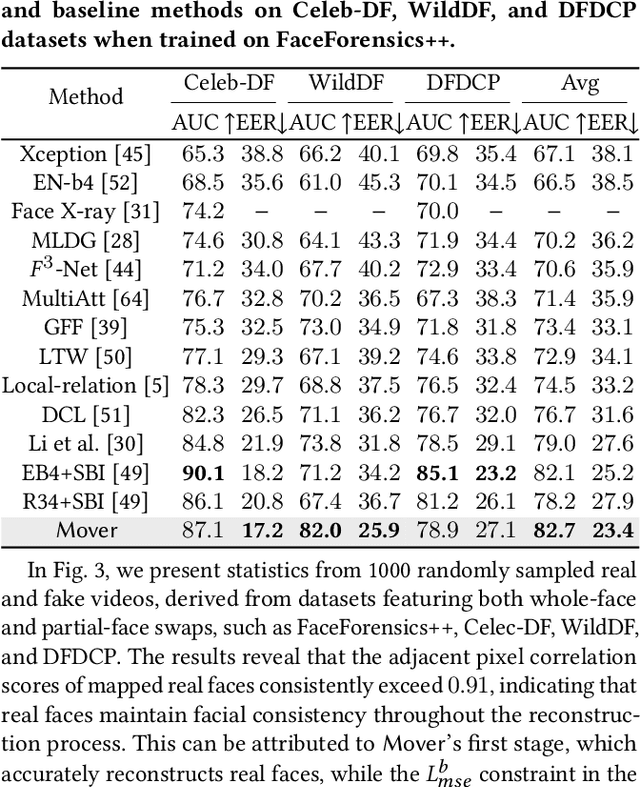


Deepfake techniques have been used maliciously, resulting in strong research interests in developing Deepfake detection methods. Deepfake often manipulates the video content by tampering with some facial parts. However, this manipulation usually breaks the consistency among facial parts, e.g., Deepfake may change smiling lips to upset, but the eyes are still smiling. Existing works propose to spot inconsistency on some specific facial parts (e.g., lips), but they may perform poorly if new Deepfake techniques focus on the specific facial parts used by the detector. Thus, this paper proposes a new Deepfake detection model, DeepfakeMAE, which can utilize the consistencies among all facial parts. Specifically, given a real face image, we first pretrain a masked autoencoder to learn facial part consistency by randomly masking some facial parts and reconstructing missing areas based on the remaining facial parts. Furthermore, to maximize the discrepancy between real and fake videos, we propose a novel model with dual networks that utilize the pretrained encoder and decoder, respectively. 1) The pretrained encoder is finetuned for capturing the overall information of the given video. 2) The pretrained decoder is utilized for distinguishing real and fake videos based on the motivation that DeepfakeMAE's reconstruction should be more similar to a real face image than a fake one. Our extensive experiments on standard benchmarks demonstrate that DeepfakeMAE is highly effective and especially outperforms the previous state-of-the-art method by 3.1% AUC on average in cross-dataset detection.