 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNiMark: A Non-intrusive Watermarking Framework against Screen-shooting Attacks
Jan 17, 2026Unauthorized screen-shooting poses a critical data leakage risk. Resisting screen-shooting attacks typically requires high-strength watermark embedding, inevitably degrading the cover image. To resolve the robustness-fidelity conflict, non-intrusive watermarking has emerged as a solution by constructing logical verification keys without altering the original content. However, existing non-intrusive schemes lack the capacity to withstand screen-shooting noise. While deep learning offers a potential remedy, we observe that directly applying it leads to a previously underexplored failure mode, the Structural Shortcut: networks tend to learn trivial identity mappings and neglect the image-watermark binding. Furthermore, even when logical binding is enforced, standard training strategies cannot fully bridge the noise gap, yielding suboptimal robustness against physical distortions. In this paper, we propose NiMark, an end-to-end framework addressing these challenges. First, to eliminate the structural shortcut, we introduce the Sigmoid-Gated XOR (SG-XOR) estimator to enable gradient propagation for the logical operation, effectively enforcing rigid image-watermark binding. Second, to overcome the robustness bottleneck, we devise a two-stage training strategy integrating a restorer to bridge the domain gap caused by screen-shooting noise. Experiments demonstrate that NiMark consistently outperforms representative state-of-the-art methods against both digital attacks and screen-shooting noise, while maintaining zero visual distortion.
DDNet: A Dual-Stream Graph Learning and Disentanglement Framework for Temporal Forgery Localization
Jan 05, 2026The rapid evolution of AIGC technology enables misleading viewers by tampering mere small segments within a video, rendering video-level detection inaccurate and unpersuasive. Consequently, temporal forgery localization (TFL), which aims to precisely pinpoint tampered segments, becomes critical. However, existing methods are often constrained by \emph{local view}, failing to capture global anomalies. To address this, we propose a \underline{d}ual-stream graph learning and \underline{d}isentanglement framework for temporal forgery localization (DDNet). By coordinating a \emph{Temporal Distance Stream} for local artifacts and a \emph{Semantic Content Stream} for long-range connections, DDNet prevents global cues from being drowned out by local smoothness. Furthermore, we introduce Trace Disentanglement and Adaptation (TDA) to isolate generic forgery fingerprints, alongside Cross-Level Feature Embedding (CLFE) to construct a robust feature foundation via deep fusion of hierarchical features. Experiments on ForgeryNet and TVIL benchmarks demonstrate that our method outperforms state-of-the-art approaches by approximately 9\% in AP@0.95, with significant improvements in cross-domain robustness.
Bridging the Semantic Gap for Categorical Data Clustering via Large Language Models
Jan 03, 2026Categorical data are prevalent in domains such as healthcare, marketing, and bioinformatics, where clustering serves as a fundamental tool for pattern discovery. A core challenge in categorical data clustering lies in measuring similarity among attribute values that lack inherent ordering or distance. Without appropriate similarity measures, values are often treated as equidistant, creating a semantic gap that obscures latent structures and degrades clustering quality. Although existing methods infer value relationships from within-dataset co-occurrence patterns, such inference becomes unreliable when samples are limited, leaving the semantic context of the data underexplored. To bridge this gap, we present ARISE (Attention-weighted Representation with Integrated Semantic Embeddings), which draws on external semantic knowledge from Large Language Models (LLMs) to construct semantic-aware representations that complement the metric space of categorical data for accurate clustering. That is, LLM is adopted to describe attribute values for representation enhancement, and the LLM-enhanced embeddings are combined with the original data to explore semantically prominent clusters. Experiments on eight benchmark datasets demonstrate consistent improvements over seven representative counterparts, with gains of 19-27%. Code is available at https://github.com/develop-yang/ARISE
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
OpenPath: Open-Set Active Learning for Pathology Image Classification via Pre-trained Vision-Language Models
Jun 18, 2025Pathology image classification plays a crucial role in accurate medical diagnosis and treatment planning. Training high-performance models for this task typically requires large-scale annotated datasets, which are both expensive and time-consuming to acquire. Active Learning (AL) offers a solution by iteratively selecting the most informative samples for annotation, thereby reducing the labeling effort. However, most AL methods are designed under the assumption of a closed-set scenario, where all the unannotated images belong to target classes. In real-world clinical environments, the unlabeled pool often contains a substantial amount of Out-Of-Distribution (OOD) data, leading to low efficiency of annotation in traditional AL methods. Furthermore, most existing AL methods start with random selection in the first query round, leading to a significant waste of labeling costs in open-set scenarios. To address these challenges, we propose OpenPath, a novel open-set active learning approach for pathological image classification leveraging a pre-trained Vision-Language Model (VLM). In the first query, we propose task-specific prompts that combine target and relevant non-target class prompts to effectively select In-Distribution (ID) and informative samples from the unlabeled pool. In subsequent queries, Diverse Informative ID Sampling (DIS) that includes Prototype-based ID candidate Selection (PIS) and Entropy-Guided Stochastic Sampling (EGSS) is proposed to ensure both purity and informativeness in a query, avoiding the selection of OOD samples. Experiments on two public pathology image datasets show that OpenPath significantly enhances the model's performance due to its high purity of selected samples, and outperforms several state-of-the-art open-set AL methods. The code is available at \href{https://github.com/HiLab-git/OpenPath}{https://github.com/HiLab-git/OpenPath}..
Sim-to-Real: An Unsupervised Noise Layer for Screen-Camera Watermarking Robustness
Apr 26, 2025Unauthorized screen capturing and dissemination pose severe security threats such as data leakage and information theft. Several studies propose robust watermarking methods to track the copyright of Screen-Camera (SC) images, facilitating post-hoc certification against infringement. These techniques typically employ heuristic mathematical modeling or supervised neural network fitting as the noise layer, to enhance watermarking robustness against SC. However, both strategies cannot fundamentally achieve an effective approximation of SC noise. Mathematical simulation suffers from biased approximations due to the incomplete decomposition of the noise and the absence of interdependence among the noise components. Supervised networks require paired data to train the noise-fitting model, and it is difficult for the model to learn all the features of the noise. To address the above issues, we propose Simulation-to-Real (S2R). Specifically, an unsupervised noise layer employs unpaired data to learn the discrepancy between the modeling simulated noise distribution and the real-world SC noise distribution, rather than directly learning the mapping from sharp images to real-world images. Learning this transformation from simulation to reality is inherently simpler, as it primarily involves bridging the gap in noise distributions, instead of the complex task of reconstructing fine-grained image details. Extensive experimental results validate the efficacy of the proposed method, demonstrating superior watermark robustness and generalization compared to those of state-of-the-art methods.
A Causal Convolutional Low-rank Representation Model for Imputation of Water Quality Data
Apr 21, 2025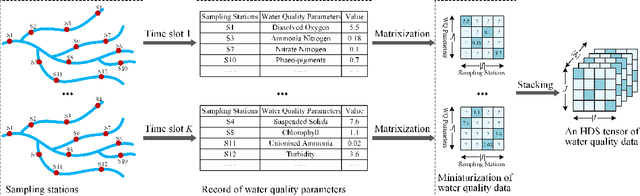
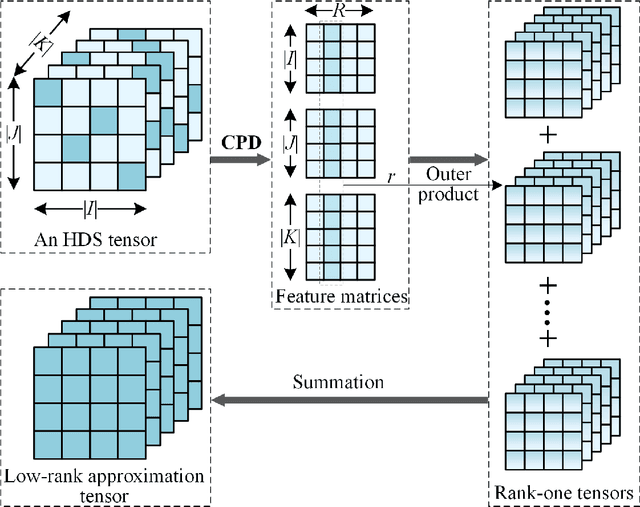

The monitoring of water quality is a crucial part of environmental protection, and a large number of monitors are widely deployed to monitor water quality. Due to unavoidable factors such as data acquisition breakdowns, sensors and communication failures, water quality monitoring data suffers from missing values over time, resulting in High-Dimensional and Sparse (HDS) Water Quality Data (WQD). The simple and rough filling of the missing values leads to inaccurate results and affects the implementation of relevant measures. Therefore, this paper proposes a Causal convolutional Low-rank Representation (CLR) model for imputing missing WQD to improve the completeness of the WQD, which employs a two-fold idea: a) applying causal convolutional operation to consider the temporal dependence of the low-rank representation, thus incorporating temporal information to improve the imputation accuracy; and b) implementing a hyperparameters adaptation scheme to automatically adjust the best hyperparameters during model training, thereby reducing the tedious manual adjustment of hyper-parameters. Experimental studies on three real-world water quality datasets demonstrate that the proposed CLR model is superior to some of the existing state-of-the-art imputation models in terms of imputation accuracy and time cost, as well as indicating that the proposed model provides more reliable decision support for environmental monitoring.
Academic Network Representation via Prediction-Sampling Incorporated Tensor Factorization
Apr 11, 2025



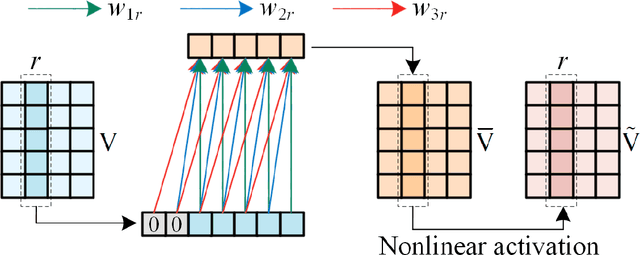
Accurate representation to an academic network is of great significance to academic relationship mining like predicting scientific impact. A Latent Factorization of Tensors (LFT) model is one of the most effective models for learning the representation of a target network. However, an academic network is often High-Dimensional and Incomplete (HDI) because the relationships among numerous network entities are impossible to be fully explored, making it difficult for an LFT model to learn accurate representation of the academic network. To address this issue, this paper proposes a Prediction-sampling-based Latent Factorization of Tensors (PLFT) model with two ideas: 1) constructing a cascade LFT architecture to enhance model representation learning ability via learning academic network hierarchical features, and 2) introducing a nonlinear activation-incorporated predicting-sampling strategy to more accurately learn the network representation via generating new academic network data layer by layer. Experimental results from the three real-world academic network datasets show that the PLFT model outperforms existing models when predicting the unexplored relationships among network entities.
FDDM: Frequency-Decomposed Diffusion Model for Rectum Cancer Dose Prediction in Radiotherapy
Oct 10, 2024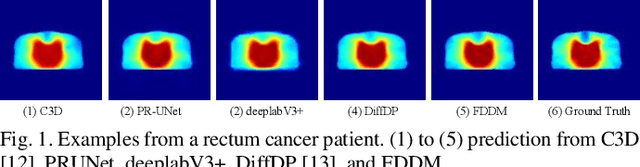
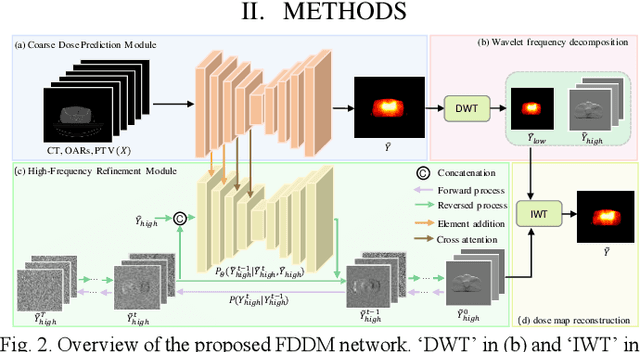
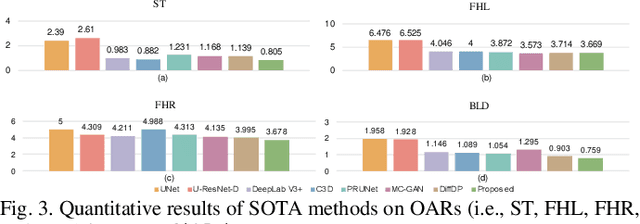
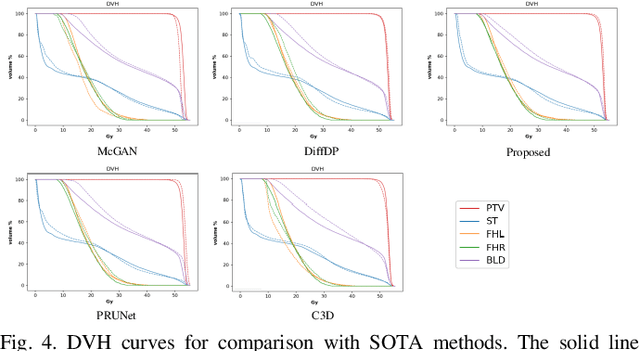
Accurate dose distribution prediction is crucial in the radiotherapy planning. Although previous methods based on convolutional neural network have shown promising performance, they have the problem of over-smoothing, leading to prediction without important high-frequency details. Recently, diffusion model has achieved great success in computer vision, which excels in generating images with more high-frequency details, yet suffers from time-consuming and extensive computational resource consumption. To alleviate these problems, we propose Frequency-Decomposed Diffusion Model (FDDM) that refines the high-frequency subbands of the dose map. To be specific, we design a Coarse Dose Prediction Module (CDPM) to first predict a coarse dose map and then utilize discrete wavelet transform to decompose the coarse dose map into a low-frequency subband and three high?frequency subbands. There is a notable difference between the coarse predicted results and ground truth in high?frequency subbands. Therefore, we design a diffusion-based module called High-Frequency Refinement Module (HFRM) that performs diffusion operation in the high?frequency components of the dose map instead of the original dose map. Extensive experiments on an in-house dataset verify the effectiveness of our approach.
An Adaptive Latent Factorization of Tensors Model for Embedding Dynamic Communication Network
Aug 29, 2024



The Dynamic Communication Network (DCN) describes the interactions over time among various communication nodes, and it is widely used in Big-data applications as a data source. As the number of communication nodes increases and temporal slots accumulate, each node interacts in with only a few nodes in a given temporal slot, the DCN can be represented by an High-Dimensional Sparse (HDS) tensor. In order to extract rich behavioral patterns from an HDS tensor in DCN, this paper proposes an Adaptive Temporal-dependent Tensor low-rank representation (ATT) model. It adopts a three-fold approach: a) designing a temporal-dependent method to reconstruct temporal feature matrix, thereby precisely represent the data by capturing the temporal patterns; b) achieving hyper-parameters adaptation of the model via the Differential Evolutionary Algorithms (DEA) to avoid tedious hyper-parameters tuning; c) employing nonnegative learning schemes for the model parameters to effectively handle an the nonnegativity inherent in HDS data. The experimental results on four real-world DCNs demonstrate that the proposed ATT model significantly outperforms several state-of-the-art models in both prediction errors and convergence rounds.