 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning of Consistency and Inconsistency Information for Fake News Detection
Aug 15, 2024



The rapid advancement of social media platforms has significantly reduced the cost of information dissemination, yet it has also led to a proliferation of fake news, posing a threat to societal trust and credibility. Most of fake news detection research focused on integrating text and image information to represent the consistency of multiple modes in news content, while paying less attention to inconsistent information. Besides, existing methods that leveraged inconsistent information often caused one mode overshadowing another, leading to ineffective use of inconsistent clue. To address these issues, we propose an adaptive multi-modal feature fusion network (MFF-Net). Inspired by human judgment processes for determining truth and falsity in news, MFF-Net focuses on inconsistent parts when news content is generally consistent and consistent parts when it is generally inconsistent. Specifically, MFF-Net extracts semantic and global features from images and texts respectively, and learns consistency information between modes through a multiple feature fusion module. To deal with the problem of modal information being easily masked, we design a single modal feature filtering strategy to capture inconsistent information from corresponding modes separately. Finally, similarity scores are calculated based on global features with adaptive adjustments made to achieve weighted fusion of consistent and inconsistent features. Extensive experimental results demonstrate that MFF-Net outperforms state-of-the-art methods across three public news datasets derived from real social medias.
Rethinking Gradient Operator for Exposing AI-enabled Face Forgeries
May 02, 2022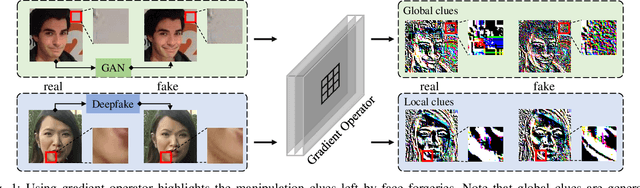

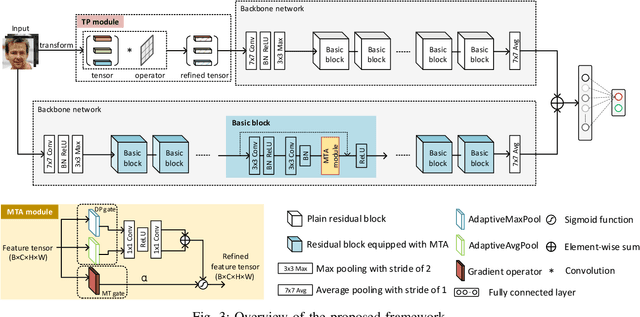

For image forensics, convolutional neural networks (CNNs) tend to learn content features rather than subtle manipulation traces, which limits forensic performance. Existing methods predominantly solve the above challenges by following a general pipeline, that is, subtracting the original pixel value from the predicted pixel value to make CNNs pay attention to the manipulation traces. However, due to the complicated learning mechanism, these methods may bring some unnecessary performance losses. In this work, we rethink the advantages of gradient operator in exposing face forgery, and design two plug-and-play modules by combining gradient operator with CNNs, namely tensor pre-processing (TP) and manipulation trace attention (MTA) module. Specifically, TP module refines the feature tensor of each channel in the network by gradient operator to highlight the manipulation traces and improve the feature representation. Moreover, MTA module considers two dimensions, namely channel and manipulation traces, to force the network to learn the distribution of manipulation traces. These two modules can be seamlessly integrated into CNNs for end-to-end training. Experiments show that the proposed network achieves better results than prior works on five public datasets. Especially, TP module greatly improves the accuracy by at least 4.60% compared with the existing pre-processing module only via simple tensor refinement. The code is available at: https://github.com/EricGzq/GocNet-pytorch.