 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering and Mitigating Destructive Multi-Embedding Attacks in Deepfake Proactive Forensics
Aug 24, 2025With the rapid evolution of deepfake technologies and the wide dissemination of digital media, personal privacy is facing increasingly serious security threats. Deepfake proactive forensics, which involves embedding imperceptible watermarks to enable reliable source tracking, serves as a crucial defense against these threats. Although existing methods show strong forensic ability, they rely on an idealized assumption of single watermark embedding, which proves impractical in real-world scenarios. In this paper, we formally define and demonstrate the existence of Multi-Embedding Attacks (MEA) for the first time. When a previously protected image undergoes additional rounds of watermark embedding, the original forensic watermark can be destroyed or removed, rendering the entire proactive forensic mechanism ineffective. To address this vulnerability, we propose a general training paradigm named Adversarial Interference Simulation (AIS). Rather than modifying the network architecture, AIS explicitly simulates MEA scenarios during fine-tuning and introduces a resilience-driven loss function to enforce the learning of sparse and stable watermark representations. Our method enables the model to maintain the ability to extract the original watermark correctly even after a second embedding. Extensive experiments demonstrate that our plug-and-play AIS training paradigm significantly enhances the robustness of various existing methods against MEA.
Bridging Semantic Logic Gaps: A Cognition-Inspired Multimodal Boundary-Preserving Network for Image Manipulation Localization
Aug 10, 2025The existing image manipulation localization (IML) models mainly relies on visual cues, but ignores the semantic logical relationships between content features. In fact, the content semantics conveyed by real images often conform to human cognitive laws. However, image manipulation technology usually destroys the internal relationship between content features, thus leaving semantic clues for IML. In this paper, we propose a cognition-inspired multimodal boundary-preserving network (CMB-Net). Specifically, CMB-Net utilizes large language models (LLMs) to analyze manipulated regions within images and generate prompt-based textual information to compensate for the lack of semantic relationships in the visual information. Considering that the erroneous texts induced by hallucination from LLMs will damage the accuracy of IML, we propose an image-text central ambiguity module (ITCAM). It assigns weights to the text features by quantifying the ambiguity between text and image features, thereby ensuring the beneficial impact of textual information. We also propose an image-text interaction module (ITIM) that aligns visual and text features using a correlation matrix for fine-grained interaction. Finally, inspired by invertible neural networks, we propose a restoration edge decoder (RED) that mutually generates input and output features to preserve boundary information in manipulated regions without loss. Extensive experiments show that CMB-Net outperforms most existing IML models.
Beyond Fully Supervised Pixel Annotations: Scribble-Driven Weakly-Supervised Framework for Image Manipulation Localization
Jul 17, 2025Deep learning-based image manipulation localization (IML) methods have achieved remarkable performance in recent years, but typically rely on large-scale pixel-level annotated datasets. To address the challenge of acquiring high-quality annotations, some recent weakly supervised methods utilize image-level labels to segment manipulated regions. However, the performance is still limited due to insufficient supervision signals. In this study, we explore a form of weak supervision that improves the annotation efficiency and detection performance, namely scribble annotation supervision. We re-annotated mainstream IML datasets with scribble labels and propose the first scribble-based IML (Sc-IML) dataset. Additionally, we propose the first scribble-based weakly supervised IML framework. Specifically, we employ self-supervised training with a structural consistency loss to encourage the model to produce consistent predictions under multi-scale and augmented inputs. In addition, we propose a prior-aware feature modulation module (PFMM) that adaptively integrates prior information from both manipulated and authentic regions for dynamic feature adjustment, further enhancing feature discriminability and prediction consistency in complex scenes. We also propose a gated adaptive fusion module (GAFM) that utilizes gating mechanisms to regulate information flow during feature fusion, guiding the model toward emphasizing potential tampered regions. Finally, we propose a confidence-aware entropy minimization loss (${\mathcal{L}}_{ {CEM }}$). This loss dynamically regularizes predictions in weakly annotated or unlabeled regions based on model uncertainty, effectively suppressing unreliable predictions. Experimental results show that our method outperforms existing fully supervised approaches in terms of average performance both in-distribution and out-of-distribution.
DiffMark: Diffusion-based Robust Watermark Against Deepfakes
Jul 02, 2025Deepfakes pose significant security and privacy threats through malicious facial manipulations. While robust watermarking can aid in authenticity verification and source tracking, existing methods often lack the sufficient robustness against Deepfake manipulations. Diffusion models have demonstrated remarkable performance in image generation, enabling the seamless fusion of watermark with image during generation. In this study, we propose a novel robust watermarking framework based on diffusion model, called DiffMark. By modifying the training and sampling scheme, we take the facial image and watermark as conditions to guide the diffusion model to progressively denoise and generate corresponding watermarked image. In the construction of facial condition, we weight the facial image by a timestep-dependent factor that gradually reduces the guidance intensity with the decrease of noise, thus better adapting to the sampling process of diffusion model. To achieve the fusion of watermark condition, we introduce a cross information fusion (CIF) module that leverages a learnable embedding table to adaptively extract watermark features and integrates them with image features via cross-attention. To enhance the robustness of the watermark against Deepfake manipulations, we integrate a frozen autoencoder during training phase to simulate Deepfake manipulations. Additionally, we introduce Deepfake-resistant guidance that employs specific Deepfake model to adversarially guide the diffusion sampling process to generate more robust watermarked images. Experimental results demonstrate the effectiveness of the proposed DiffMark on typical Deepfakes. Our code will be available at https://github.com/vpsg-research/DiffMark.
WaveGuard: Robust Deepfake Detection and Source Tracing via Dual-Tree Complex Wavelet and Graph Neural Networks
May 14, 2025Deepfake technology poses increasing risks such as privacy invasion and identity theft. To address these threats, we propose WaveGuard, a proactive watermarking framework that enhances robustness and imperceptibility via frequency-domain embedding and graph-based structural consistency. Specifically, we embed watermarks into high-frequency sub-bands using Dual-Tree Complex Wavelet Transform (DT-CWT) and employ a Structural Consistency Graph Neural Network (SC-GNN) to preserve visual quality. We also design an attention module to refine embedding precision. Experimental results on face swap and reenactment tasks demonstrate that WaveGuard outperforms state-of-the-art methods in both robustness and visual quality. Code is available at https://github.com/vpsg-research/WaveGuard.
Deep Lossless Image Compression via Masked Sampling and Coarse-to-Fine Auto-Regression
Mar 14, 2025Learning-based lossless image compression employs pixel-based or subimage-based auto-regression for probability estimation, which achieves desirable performances. However, the existing works only consider context dependencies in one direction, namely, those symbols that appear before the current symbol in raster order. We believe that the dependencies between the current and future symbols should be further considered. In this work, we propose a deep lossless image compression via masked sampling and coarse-to-fine auto-regression. It combines lossy reconstruction and progressive residual compression, which fuses contexts from various directions and is more consistent with human perception. Specifically, the residuals are decomposed via $T$ iterative masked sampling, and each sampling consists of three steps: 1) probability estimation, 2) mask computation, and 3) arithmetic coding. The iterative process progressively refines our prediction and gradually presents a real image. Extensive experimental results show that compared with the existing traditional and learned lossless compression, our method achieves comparable compression performance on extensive datasets with competitive coding speed and more flexibility.
Rethinking Gradient Operator for Exposing AI-enabled Face Forgeries
May 02, 2022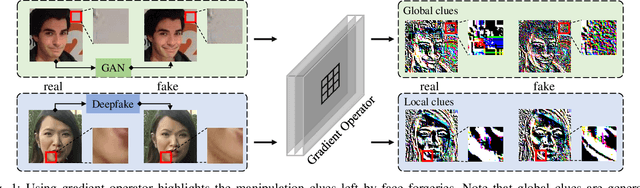

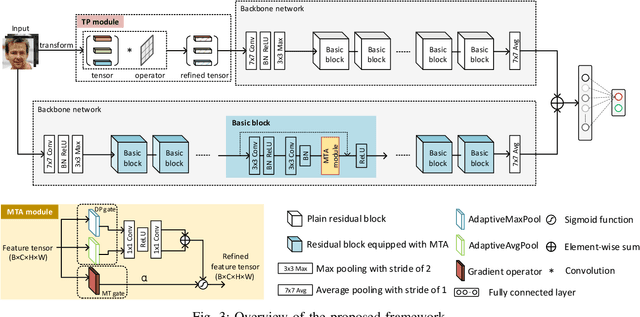

For image forensics, convolutional neural networks (CNNs) tend to learn content features rather than subtle manipulation traces, which limits forensic performance. Existing methods predominantly solve the above challenges by following a general pipeline, that is, subtracting the original pixel value from the predicted pixel value to make CNNs pay attention to the manipulation traces. However, due to the complicated learning mechanism, these methods may bring some unnecessary performance losses. In this work, we rethink the advantages of gradient operator in exposing face forgery, and design two plug-and-play modules by combining gradient operator with CNNs, namely tensor pre-processing (TP) and manipulation trace attention (MTA) module. Specifically, TP module refines the feature tensor of each channel in the network by gradient operator to highlight the manipulation traces and improve the feature representation. Moreover, MTA module considers two dimensions, namely channel and manipulation traces, to force the network to learn the distribution of manipulation traces. These two modules can be seamlessly integrated into CNNs for end-to-end training. Experiments show that the proposed network achieves better results than prior works on five public datasets. Especially, TP module greatly improves the accuracy by at least 4.60% compared with the existing pre-processing module only via simple tensor refinement. The code is available at: https://github.com/EricGzq/GocNet-pytorch.
Exposing Deepfake Face Forgeries with Guided Residuals
May 02, 2022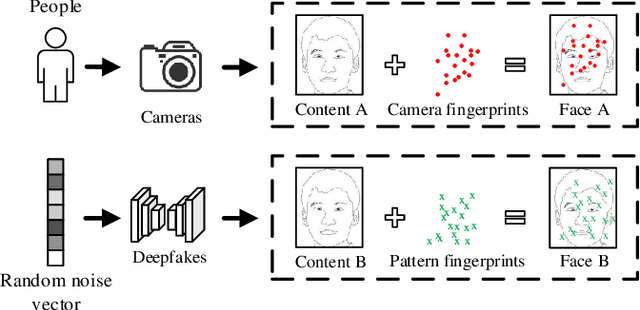

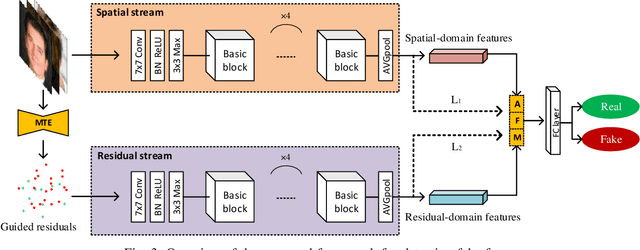
Residual-domain feature is very useful for Deepfake detection because it suppresses irrelevant content features and preserves key manipulation traces. However, inappropriate residual prediction will bring side effects on detection accuracy. In addition, residual-domain features are easily affected by image operations such as compression. Most existing works exploit either spatial-domain features or residual-domain features, while neglecting that two types of features are mutually correlated. In this paper, we propose a guided residuals network, namely GRnet, which fuses spatial-domain and residual-domain features in a mutually reinforcing way, to expose face images generated by Deepfake. Different from existing prediction based residual extraction methods, we propose a manipulation trace extractor (MTE) to directly remove the content features and preserve manipulation traces. MTE is a fine-grained method that can avoid the potential bias caused by inappropriate prediction. Moreover, an attention fusion mechanism (AFM) is designed to selectively emphasize feature channel maps and adaptively allocate the weights for two streams. The experimental results show that the proposed GRnet achieves better performances than the state-of-the-art works on four public fake face datasets including HFF, FaceForensics++, DFDC and Celeb-DF. Especially, GRnet achieves an average accuracy of 97.72% on the HFF dataset, which is at least 5.25% higher than the existing works.
Fake Face Detection via Adaptive Residuals Extraction Network
May 11, 2020
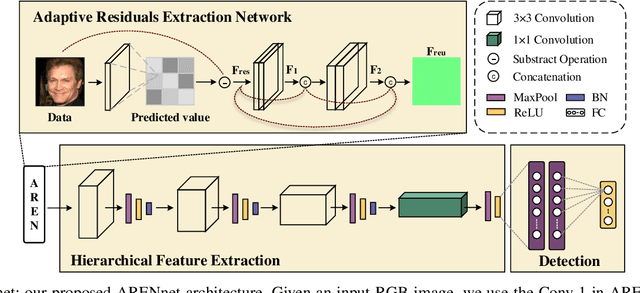

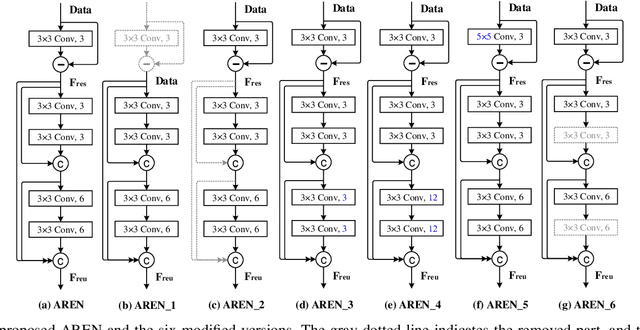
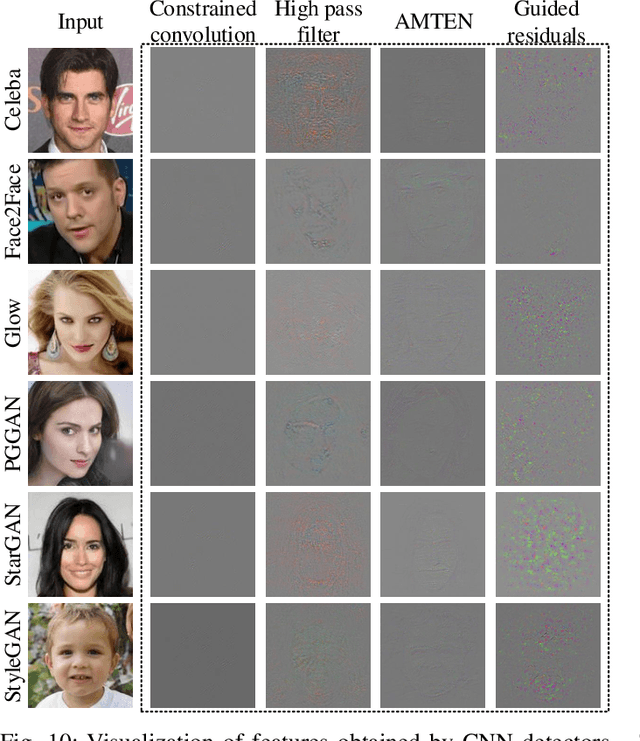
With the proliferation of face image manipulation (FIM) techniques such as Face2Face and Deepfake, more fake face images are spreading over the internet, which brings serious challenges to public confidence. Face image forgery detection has made considerable progresses in exposing specific FIM, but it is still in scarcity of a robust fake face detector to expose face image forgeries under complex scenarios. Due to the relatively fixed structure, convolutional neural network (CNN) tends to learn image content representations. However, CNN should learn subtle tampering artifacts for image forensics tasks. We propose an adaptive residuals extraction network (AREN), which serves as pre-processing to suppress image content and highlight tampering artifacts. AREN exploits an adaptive convolution layer to predict image residuals, which are reused in subsequent layers to maximize manipulation artifacts by updating weights during the back-propagation pass. A fake face detector, namely ARENnet, is constructed by integrating AREN with CNN. Experimental results prove that the proposed AREN achieves desirable pre-processing. When detecting fake face images generated by various FIM techniques, ARENnet achieves an average accuracy up to 98.52%, which outperforms the state-of-the-art works. When detecting face images with unknown post-processing operations, the detector also achieves an average accuracy of 95.17%.