 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGTR: Fine-Grained Multi-Table Retrieval via Hierarchical LLM Reasoning
Mar 13, 2026With the rapid advancement of large language models (LLMs), growing efforts have been made on LLM-based table retrieval. However, existing studies typically focus on single-table query, and implement it by similarity matching after encoding the entire table. These methods usually result in low accuracy due to their coarse-grained encoding which incorporates much query-irrelated data, and are also inefficient when dealing with large tables, failing to fully utilize the reasoning capabilities of LLM. Further, multi-table query is under-explored in retrieval tasks. To this end, we propose a hierarchical multi-table query method based on LLM: Fine-Grained Multi-Table Retrieval FGTR, a new retrieval paradigm that employs a human-like reasoning strategy. Through hierarchical reasoning, FGTR first identifies relevant schema elements and then retrieves the corresponding cell contents, ultimately constructing a concise and accurate sub-table that aligns with the given query. To comprehensively evaluate the performance of FGTR, we construct two new benchmark datasets based on Spider and BIRD . Experimental results show that FGTR outperforms previous state-of-the-art methods, improving the F_2 metric by 18% on Spider and 21% on BIRD, demonstrating its effectiveness in enhancing fine-grained retrieval and its potential to improve end-to-end performance on table-based downstream tasks.
GaussianImage++: Boosted Image Representation and Compression with 2D Gaussian Splatting
Dec 22, 2025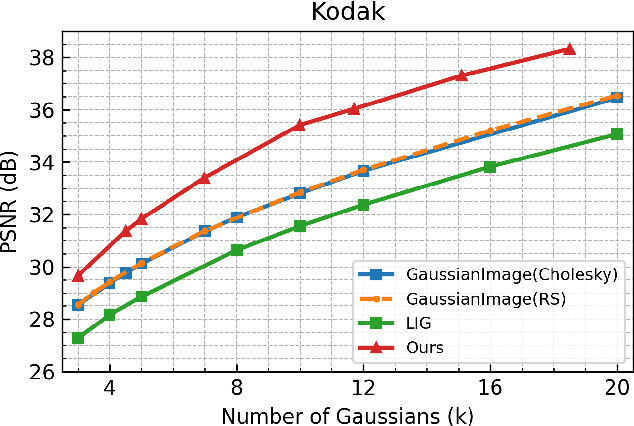
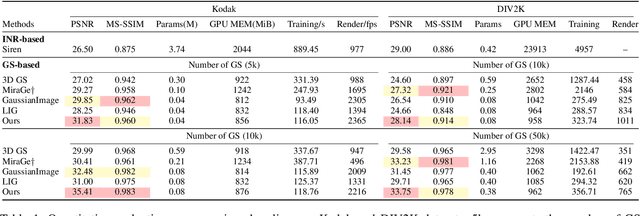
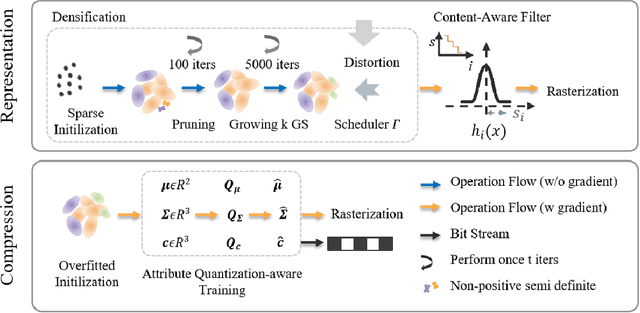

Implicit neural representations (INRs) have achieved remarkable success in image representation and compression, but they require substantial training time and memory. Meanwhile, recent 2D Gaussian Splatting (GS) methods (\textit{e.g.}, GaussianImage) offer promising alternatives through efficient primitive-based rendering. However, these methods require excessive Gaussian primitives to maintain high visual fidelity. To exploit the potential of GS-based approaches, we present GaussianImage++, which utilizes limited Gaussian primitives to achieve impressive representation and compression performance. Firstly, we introduce a distortion-driven densification mechanism. It progressively allocates Gaussian primitives according to signal intensity. Secondly, we employ context-aware Gaussian filters for each primitive, which assist in the densification to optimize Gaussian primitives based on varying image content. Thirdly, we integrate attribute-separated learnable scalar quantizers and quantization-aware training, enabling efficient compression of primitive attributes. Experimental results demonstrate the effectiveness of our method. In particular, GaussianImage++ outperforms GaussianImage and INRs-based COIN in representation and compression performance while maintaining real-time decoding and low memory usage.
Deep Lossless Image Compression via Masked Sampling and Coarse-to-Fine Auto-Regression
Mar 14, 2025Learning-based lossless image compression employs pixel-based or subimage-based auto-regression for probability estimation, which achieves desirable performances. However, the existing works only consider context dependencies in one direction, namely, those symbols that appear before the current symbol in raster order. We believe that the dependencies between the current and future symbols should be further considered. In this work, we propose a deep lossless image compression via masked sampling and coarse-to-fine auto-regression. It combines lossy reconstruction and progressive residual compression, which fuses contexts from various directions and is more consistent with human perception. Specifically, the residuals are decomposed via $T$ iterative masked sampling, and each sampling consists of three steps: 1) probability estimation, 2) mask computation, and 3) arithmetic coding. The iterative process progressively refines our prediction and gradually presents a real image. Extensive experimental results show that compared with the existing traditional and learned lossless compression, our method achieves comparable compression performance on extensive datasets with competitive coding speed and more flexibility.
Robust Beamforming and Rate-Splitting Design for Next Generation Ultra-Reliable and Low-Latency Communications
Sep 19, 2022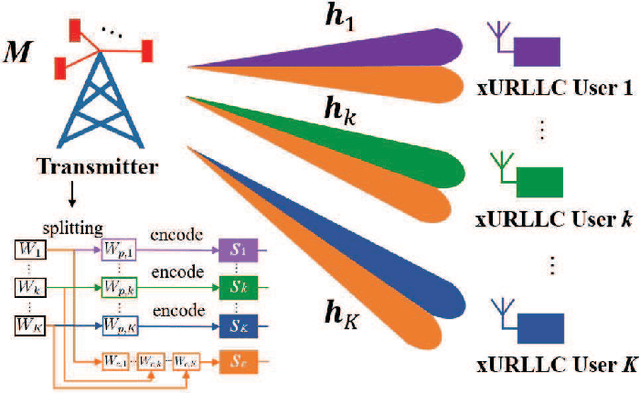
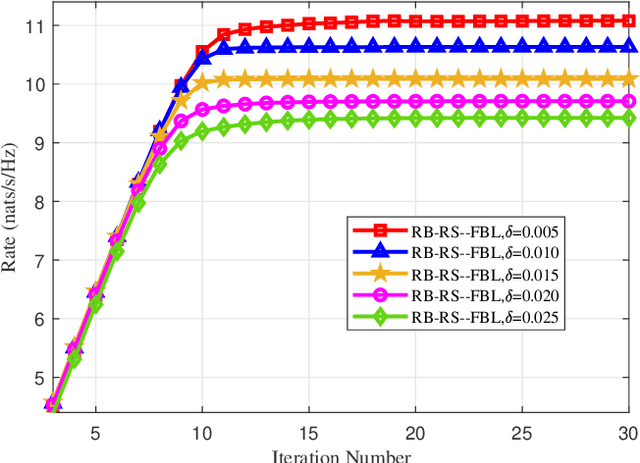


The next generation ultra-reliable and low-latency communications (xURLLC) need novel design to provide satisfactory services to the emerging mission-critical applications. To improve the spectrum efficiency and enhance the robustness of xURLLC, this paper proposes a robust beamforming and rate-splitting design in the finite blocklength (FBL) regime for downlink multi-user multi-antenna xURLLC systems. In the design, adaptive rate-splitting is introduced to flexibly handle the complex inter-user interference and thus improve the spectrum efficiency. Taking the imperfection of the channel state information at the transmitter (CSIT) into consideration, a max-min user rate problem is formulated to optimize the common and private beamforming vectors and the rate-splitting vector under the premise of ensuring the requirements of transmission latency and reliability of all the users. The optimization problem is intractable due to the non-convexity of the constraint set and the infinite constraints caused by CSIT uncertainties. To solve it, we convert the infinite constraints into finite ones by the S-Procedure method and transform the original problem into a difference of convex (DC) programming. A constrained concave convex procedure (CCCP) and the Gaussian randomization based iterative algorithm is proposed to obtain a local minimum. Simulation results confirm the convergence, robustness and effectiveness of the proposed robust beamforming and rate-splitting design in the FBL regime. It is also shown that the proposed robust design achieves considerable performance gain in the worst user rate compared with existing transmission schemes under various blocklength and block error rate requirements.
BABD: A Bitcoin Address Behavior Dataset for Address Behavior Pattern Analysis
Apr 21, 2022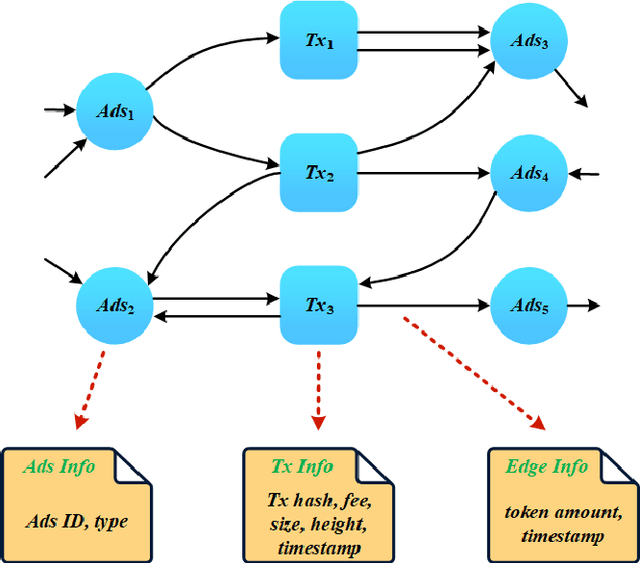
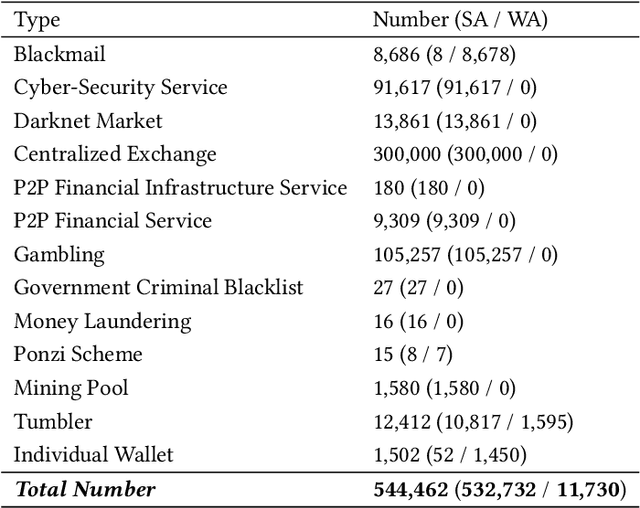
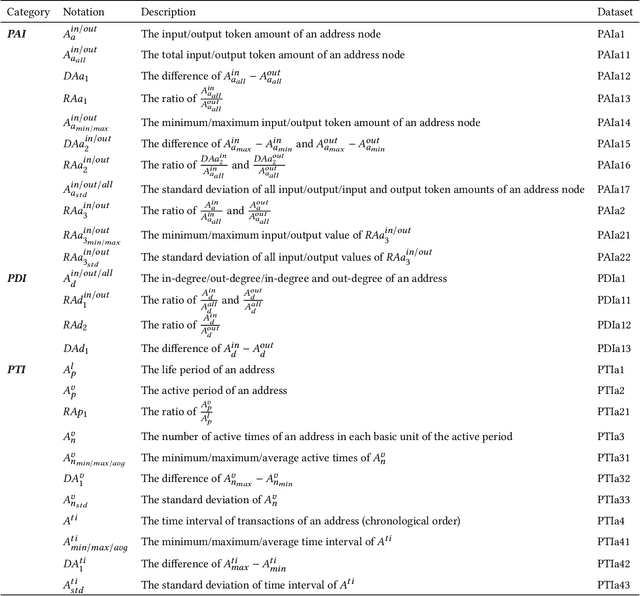
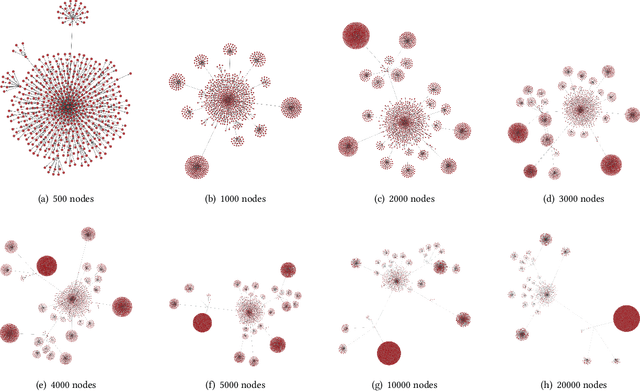
Cryptocurrencies are no longer just the preferred option for cybercriminal activities on darknets, due to the increasing adoption in mainstream applications. This is partly due to the transparency associated with the underpinning ledgers, where any individual can access the record of a transaction record on the public ledger. In this paper, we build a dataset comprising Bitcoin transactions between 12 July 2019 and 26 May 2021. This dataset (hereafter referred to as BABD-13) contains 13 types of Bitcoin addresses, 5 categories of indicators with 148 features, and 544,462 labeled data. We then use our proposed dataset on common machine learning models, namely: k-nearest neighbors algorithm, decision tree, random forest, multilayer perceptron, and XGBoost. The results show that the accuracy rates of these machine learning models on our proposed dataset are between 93.24% and 96.71%. We also analyze the proposed features and their relationships from the experiments, and propose a k-hop subgraph generation algorithm to extract a k-hop subgraph from the entire Bitcoin transaction graph constructed by the directed heterogeneous multigraph starting from a specific Bitcoin address node (e.g., a known transaction associated with a criminal investigation).
A Lightweight Privacy-Preserving Scheme Using Label-based Pixel Block Mixing for Image Classification in Deep Learning
May 19, 2021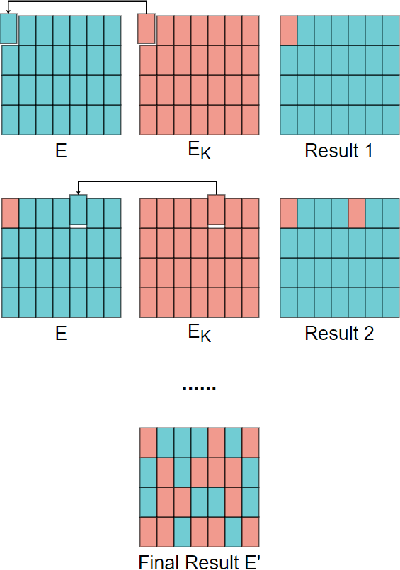
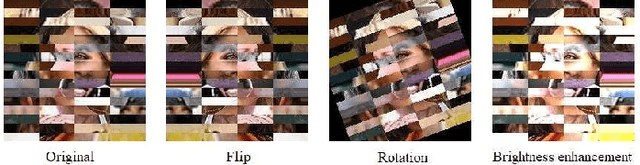
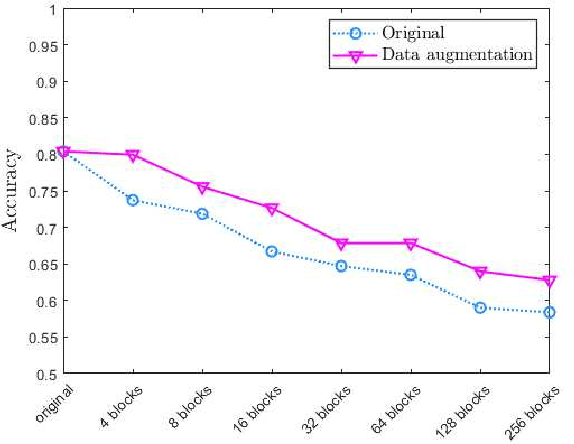
To ensure the privacy of sensitive data used in the training of deep learning models, a number of privacy-preserving methods have been designed by the research community. However, existing schemes are generally designed to work with textual data, or are not efficient when a large number of images is used for training. Hence, in this paper we propose a lightweight and efficient approach to preserve image privacy while maintaining the availability of the training set. Specifically, we design the pixel block mixing algorithm for image classification privacy preservation in deep learning. To evaluate its utility, we use the mixed training set to train the ResNet50, VGG16, InceptionV3 and DenseNet121 models on the WIKI dataset and the CNBC face dataset. Experimental findings on the testing set show that our scheme preserves image privacy while maintaining the availability of the training set in the deep learning models. Additionally, the experimental results demonstrate that we achieve good performance for the VGG16 model on the WIKI dataset and both ResNet50 and DenseNet121 on the CNBC dataset. The pixel block algorithm achieves fairly high efficiency in the mixing of the images, and it is computationally challenging for the attackers to restore the mixed training set to the original training set. Moreover, data augmentation can be applied to the mixed training set to improve the training's effectiveness.
Efficiently Constructing Adversarial Examples by Feature Watermarking
Aug 14, 2020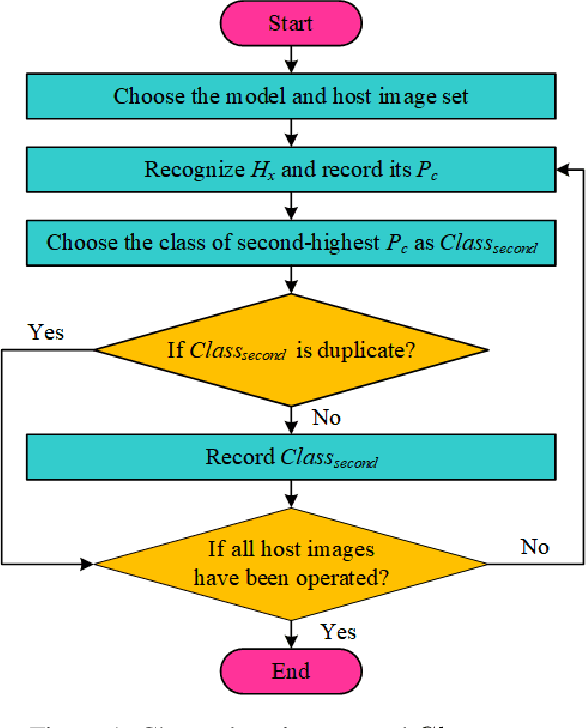

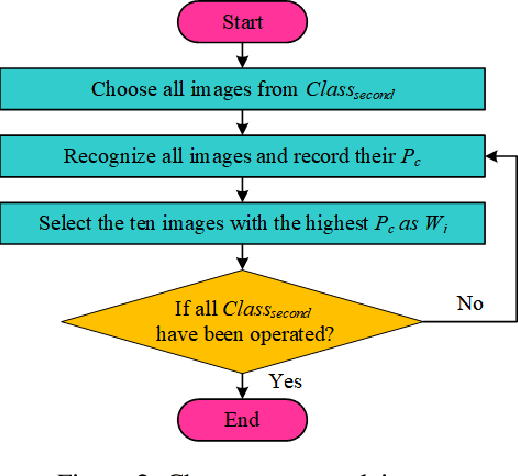
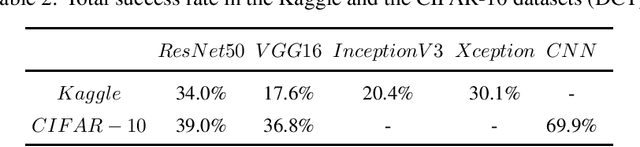
With the increasing attentions of deep learning models, attacks are also upcoming for such models. For example, an attacker may carefully construct images in specific ways (also referred to as adversarial examples) aiming to mislead the deep learning models to output incorrect classification results. Similarly, many efforts are proposed to detect and mitigate adversarial examples, usually for certain dedicated attacks. In this paper, we propose a novel digital watermark based method to generate adversarial examples for deep learning models. Specifically, partial main features of the watermark image are embedded into the host image invisibly, aiming to tamper and damage the recognition capabilities of the deep learning models. We devise an efficient mechanism to select host images and watermark images, and utilize the improved discrete wavelet transform (DWT) based Patchwork watermarking algorithm and the modified discrete cosine transform (DCT) based Patchwork watermarking algorithm. The experimental results showed that our scheme is able to generate a large number of adversarial examples efficiently. In addition, we find that using the extracted features of the image as the watermark images, can increase the success rate of an attack under certain conditions with minimal changes to the host image. To ensure repeatability, reproducibility, and code sharing, the source code is available on GitHub
Deep Complementary Joint Model for Complex Scene Registration and Few-shot Segmentation on Medical Images
Aug 03, 2020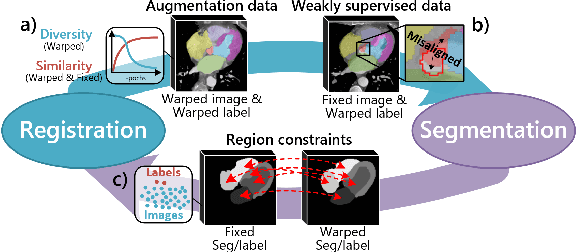

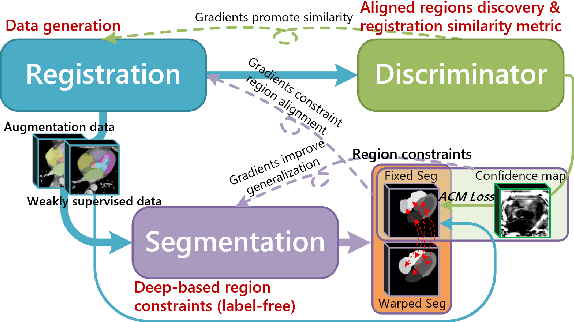
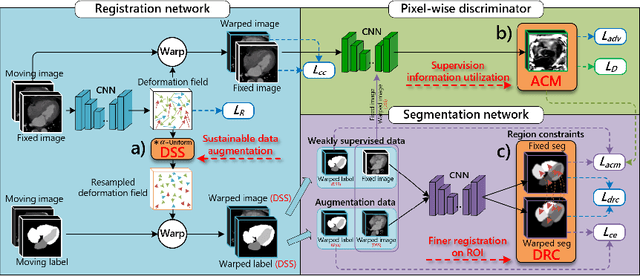
Deep learning-based medical image registration and segmentation joint models utilize the complementarity (augmentation data or weakly supervised data from registration, region constraints from segmentation) to bring mutual improvement in complex scene and few-shot situation. However, further adoption of the joint models are hindered: 1) the diversity of augmentation data is reduced limiting the further enhancement of segmentation, 2) misaligned regions in weakly supervised data disturb the training process, 3) lack of label-based region constraints in few-shot situation limits the registration performance. We propose a novel Deep Complementary Joint Model (DeepRS) for complex scene registration and few-shot segmentation. We embed a perturbation factor in the registration to increase the activity of deformation thus maintaining the augmentation data diversity. We take a pixel-wise discriminator to extract alignment confidence maps which highlight aligned regions in weakly supervised data so the misaligned regions' disturbance will be suppressed via weighting. The outputs from segmentation model are utilized to implement deep-based region constraints thus relieving the label requirements and bringing fine registration. Extensive experiments on the CT dataset of MM-WHS 2017 Challenge show great advantages of our DeepRS that outperforms the existing state-of-the-art models.
Semi-supervised learning method based on predefined evenly-distributed class centroids
Jan 13, 2020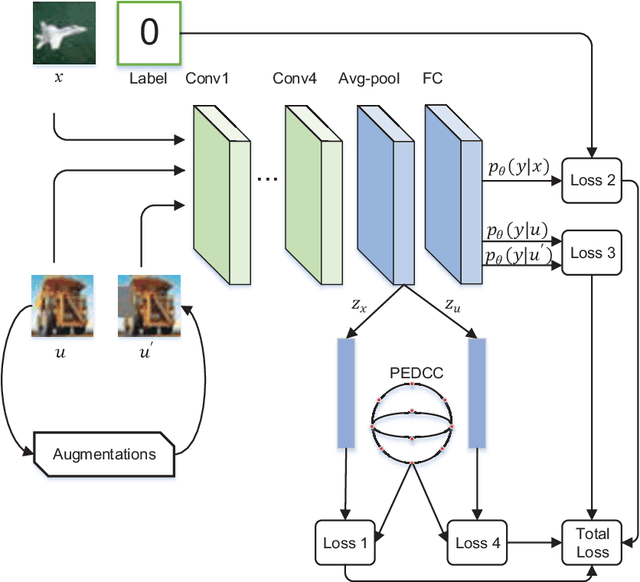
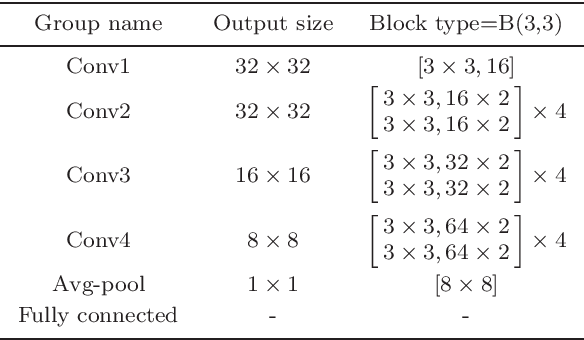
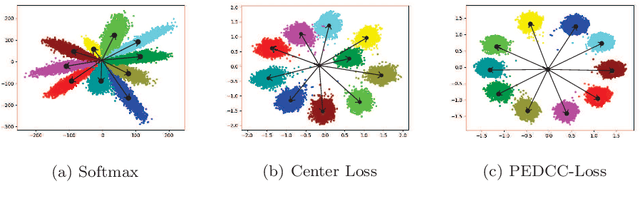

Compared to supervised learning, semi-supervised learning reduces the dependence of deep learning on a large number of labeled samples. In this work, we use a small number of labeled samples and perform data augmentation on unlabeled samples to achieve image classification. Our method constrains all samples to the predefined evenly-distributed class centroids (PEDCC) by the corresponding loss function. Specifically, the PEDCC-Loss for labeled samples, and the maximum mean discrepancy loss for unlabeled samples are used to make the feature distribution closer to the distribution of PEDCC. Our method ensures that the inter-class distance is large and the intra-class distance is small enough to make the classification boundaries between different classes clearer. Meanwhile, for unlabeled samples, we also use KL divergence to constrain the consistency of the network predictions between unlabeled and augmented samples. Our semi-supervised learning method achieves the state-of-the-art results, with 4000 labeled samples on CIFAR10 and 1000 labeled samples on SVHN, and the accuracy is 95.10% and 97.58% respectively.
Short-term load forecasting using optimized LSTM networks based on EMD
Aug 16, 2018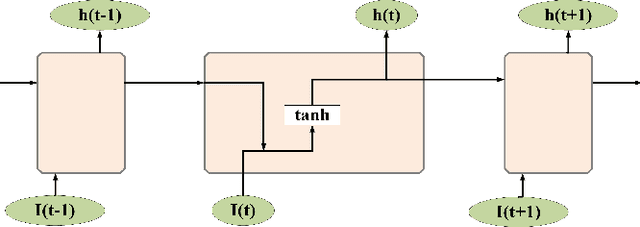
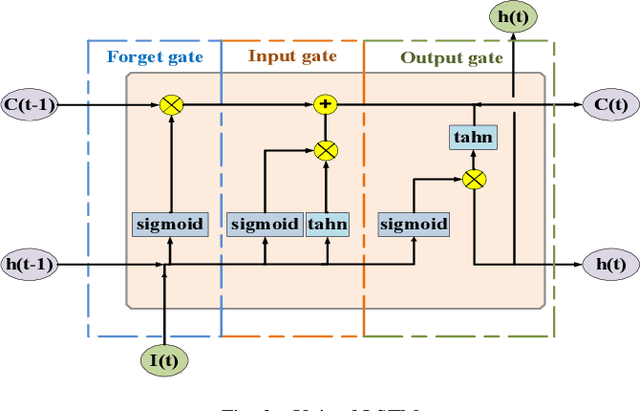
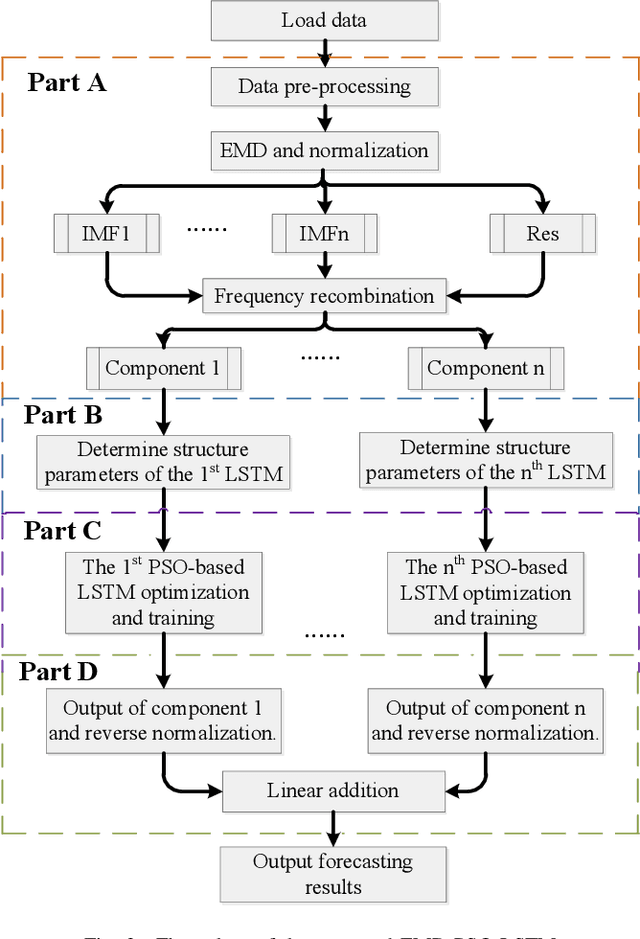
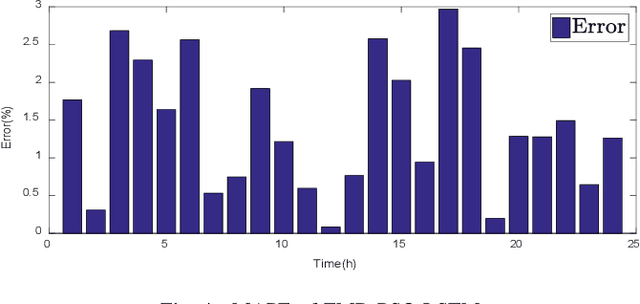
Short-term load forecasting is one of the crucial sections in smart grid. Precise forecasting enables system operators to make reliable unit commitment and power dispatching decisions. With the advent of big data, a number of artificial intelligence techniques such as back propagation, support vector machine have been used to predict the load of the next day. Nevertheless, due to the noise of raw data and the randomness of power load, forecasting errors of existing approaches are relatively large. In this study, a short-term load forecasting method is proposed on the basis of empirical mode decomposition and long short-term memory networks, the parameters of which are optimized by a particle swarm optimization algorithm. Essentially, empirical mode decomposition can decompose the original time series of historical data into relatively stationary components and long short-term memory network is able to emphasize as well as model the timing of data, the joint use of which is expected to effectively apply the characteristics of data itself, so as to improve the predictive accuracy. The effectiveness of this research is exemplified on a realistic data set, the experimental results of which show that the proposed method has higher forecasting accuracy and applicability, as compared with existing methods.