 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Privacy-Preserving Scheme Using Label-based Pixel Block Mixing for Image Classification in Deep Learning
Paper and Code
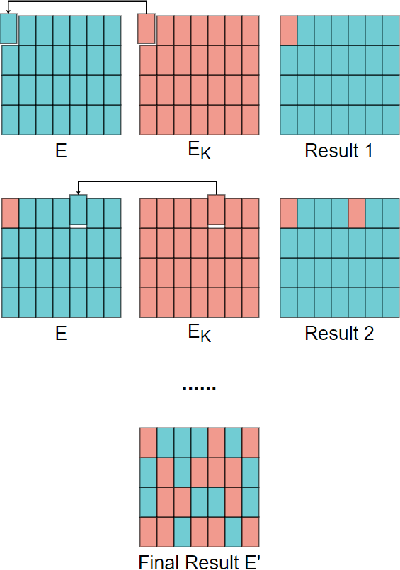
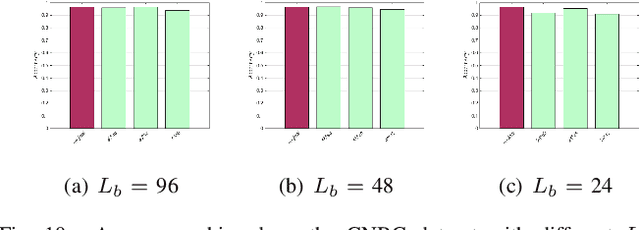
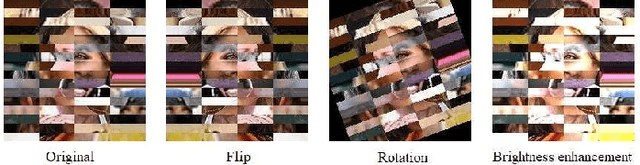
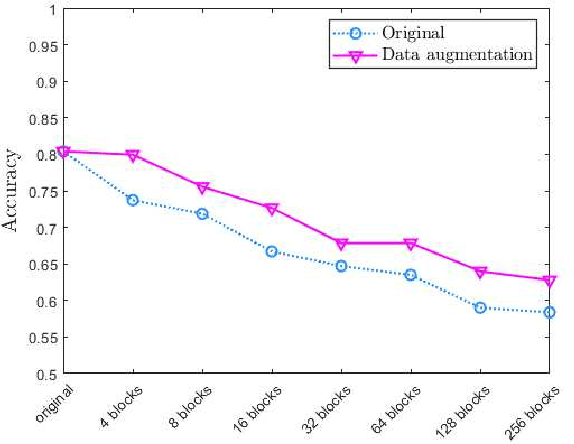
To ensure the privacy of sensitive data used in the training of deep learning models, a number of privacy-preserving methods have been designed by the research community. However, existing schemes are generally designed to work with textual data, or are not efficient when a large number of images is used for training. Hence, in this paper we propose a lightweight and efficient approach to preserve image privacy while maintaining the availability of the training set. Specifically, we design the pixel block mixing algorithm for image classification privacy preservation in deep learning. To evaluate its utility, we use the mixed training set to train the ResNet50, VGG16, InceptionV3 and DenseNet121 models on the WIKI dataset and the CNBC face dataset. Experimental findings on the testing set show that our scheme preserves image privacy while maintaining the availability of the training set in the deep learning models. Additionally, the experimental results demonstrate that we achieve good performance for the VGG16 model on the WIKI dataset and both ResNet50 and DenseNet121 on the CNBC dataset. The pixel block algorithm achieves fairly high efficiency in the mixing of the images, and it is computationally challenging for the attackers to restore the mixed training set to the original training set. Moreover, data augmentation can be applied to the mixed training set to improve the training's effectiveness.