 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Adversarial Rewriting Exposes Architectural Vulnerabilities in Black-Box NLP Pipelines
Apr 26, 2026Multi-component natural language processing (NLP) pipelines are increasingly deployed for high-stakes decisions, yet no existing adversarial method can test their robustness under realistic conditions: binary-only feedback, no gradient access, and strict query budgets. We formalize this strict black-box threat model and propose a two-agent evasion framework operating in a semantic perturbation space. An Attacker Agent generates meaning-preserving rewrites while a Prompt Optimization Agent refines the attack strategy using only binary decision feedback within a 10-query budget. Evaluated against four evidence-based misinformation detection pipelines, the framework achieves evasion rates of 19.95 to 40.34% on modern large language model (LLM) based systems, compared to at most 3.90% for token-level perturbation baselines that rely on surrogate models because they cannot operate under our threat model. A legacy system relying on static lexical retrieval exhibits near-total vulnerability 97.02%, establishing a lower bound that exposes how architectural choices govern the attack surface. Evasion effectiveness is associated with three architectural properties: evidence retrieval mechanism, retrieval-inference coupling, and baseline classification accuracy. The iterative prompt optimization yields the largest marginal gains against the most robust targets, confirming that adaptive strategy discovery is essential when evasion is non-trivial. Analysis of successful rewrites reveals four exploitation patterns, each targeting failures at distinct pipeline stages. A pattern-informed defense reduces the evasion rate by up to 65.18%.
Feature-Selective Representation Misdirection for Machine Unlearning
Dec 18, 2025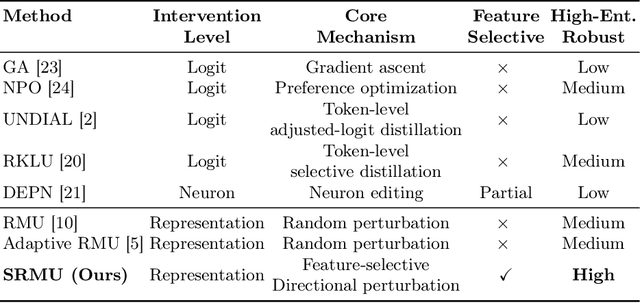



As large language models (LLMs) are increasingly adopted in safety-critical and regulated sectors, the retention of sensitive or prohibited knowledge introduces escalating risks, ranging from privacy leakage to regulatory non-compliance to to potential misuse, and so on. Recent studies suggest that machine unlearning can help ensure deployed models comply with evolving legal, safety, and governance requirements. However, current unlearning techniques assume clean separation between forget and retain datasets, which is challenging in operational settings characterized by highly entangled distributions. In such scenarios, perturbation-based methods often degrade general model utility or fail to ensure safety. To address this, we propose Selective Representation Misdirection for Unlearning (SRMU), a novel principled activation-editing framework that enforces feature-aware and directionally controlled perturbations. Unlike indiscriminate model weights perturbations, SRMU employs a structured misdirection vector with an activation importance map. The goal is to allow SRMU selectively suppresses harmful representations while preserving the utility on benign ones. Experiments are conducted on the widely used WMDP benchmark across low- and high-entanglement configurations. Empirical results reveal that SRMU delivers state-of-the-art unlearning performance with minimal utility losses, and remains effective under 20-30\% overlap where existing baselines collapse. SRMU provides a robust foundation for safety-driven model governance, privacy compliance, and controlled knowledge removal in the emerging LLM-based applications. We release the replication package at https://figshare.com/s/d5931192a8824de26aff.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
Beyond Text-to-SQL for IoT Defense: A Comprehensive Framework for Querying and Classifying IoT Threats
Jun 25, 2024Recognizing the promise of natural language interfaces to databases, prior studies have emphasized the development of text-to-SQL systems. While substantial progress has been made in this field, existing research has concentrated on generating SQL statements from text queries. The broader challenge, however, lies in inferring new information about the returned data. Our research makes two major contributions to address this gap. First, we introduce a novel Internet-of-Things (IoT) text-to-SQL dataset comprising 10,985 text-SQL pairs and 239,398 rows of network traffic activity. The dataset contains additional query types limited in prior text-to-SQL datasets, notably temporal-related queries. Our dataset is sourced from a smart building's IoT ecosystem exploring sensor read and network traffic data. Second, our dataset allows two-stage processing, where the returned data (network traffic) from a generated SQL can be categorized as malicious or not. Our results show that joint training to query and infer information about the data can improve overall text-to-SQL performance, nearly matching substantially larger models. We also show that current large language models (e.g., GPT3.5) struggle to infer new information about returned data, thus our dataset provides a novel test bed for integrating complex domain-specific reasoning into LLMs.
A2-DIDM: Privacy-preserving Accumulator-enabled Auditing for Distributed Identity of DNN Model
May 07, 2024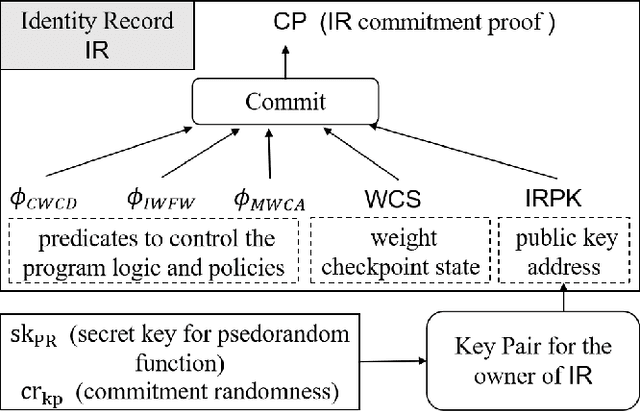



Recent booming development of Generative Artificial Intelligence (GenAI) has facilitated an emerging model commercialization for the purpose of reinforcement on model performance, such as licensing or trading Deep Neural Network (DNN) models. However, DNN model trading may trigger concerns of the unauthorized replications or misuses over the model, so that the benefit of the model ownership will be violated. Model identity auditing is a challenging issue in protecting intellectual property of DNN models and verifying the integrity and ownership of models for guaranteeing trusts in transactions is one of the critical obstacles. In this paper, we focus on the above issue and propose a novel Accumulator-enabled Auditing for Distributed Identity of DNN Model (A2-DIDM) that utilizes blockchain and zero-knowledge techniques to protect data and function privacy while ensuring the lightweight on-chain ownership verification. The proposed model presents a scheme of identity records via configuring model weight checkpoints with corresponding zero-knowledge proofs, which incorporates predicates to capture incremental state changes in model weight checkpoints. Our scheme ensures both computational integrity of DNN training process and programmability, so that the uniqueness of the weight checkpoint sequence in a DNN model is preserved, ensuring the correctness of the model identity auditing. In addition, A2-DIDM also addresses privacy protections in distributed identity via a proposed method of accumulators. We systematically analyze the security and robustness of our proposed model and further evaluate the effectiveness and usability of auditing DNN model identities.
Holistic Evaluation Metrics: Use Case Sensitive Evaluation Metrics for Federated Learning
May 03, 2024A large number of federated learning (FL) algorithms have been proposed for different applications and from varying perspectives. However, the evaluation of such approaches often relies on a single metric (e.g., accuracy). Such a practice fails to account for the unique demands and diverse requirements of different use cases. Thus, how to comprehensively evaluate an FL algorithm and determine the most suitable candidate for a designated use case remains an open question. To mitigate this research gap, we introduce the Holistic Evaluation Metrics (HEM) for FL in this work. Specifically, we collectively focus on three primary use cases, which are Internet of Things (IoT), smart devices, and institutions. The evaluation metric encompasses various aspects including accuracy, convergence, computational efficiency, fairness, and personalization. We then assign a respective importance vector for each use case, reflecting their distinct performance requirements and priorities. The HEM index is finally generated by integrating these metric components with their respective importance vectors. Through evaluating different FL algorithms in these three prevalent use cases, our experimental results demonstrate that HEM can effectively assess and identify the FL algorithms best suited to particular scenarios. We anticipate this work sheds light on the evaluation process for pragmatic FL algorithms in real-world applications.
GE-AdvGAN: Improving the transferability of adversarial samples by gradient editing-based adversarial generative model
Jan 30, 2024Adversarial generative models, such as Generative Adversarial Networks (GANs), are widely applied for generating various types of data, i.e., images, text, and audio. Accordingly, its promising performance has led to the GAN-based adversarial attack methods in the white-box and black-box attack scenarios. The importance of transferable black-box attacks lies in their ability to be effective across different models and settings, more closely aligning with real-world applications. However, it remains challenging to retain the performance in terms of transferable adversarial examples for such methods. Meanwhile, we observe that some enhanced gradient-based transferable adversarial attack algorithms require prolonged time for adversarial sample generation. Thus, in this work, we propose a novel algorithm named GE-AdvGAN to enhance the transferability of adversarial samples whilst improving the algorithm's efficiency. The main approach is via optimising the training process of the generator parameters. With the functional and characteristic similarity analysis, we introduce a novel gradient editing (GE) mechanism and verify its feasibility in generating transferable samples on various models. Moreover, by exploring the frequency domain information to determine the gradient editing direction, GE-AdvGAN can generate highly transferable adversarial samples while minimizing the execution time in comparison to the state-of-the-art transferable adversarial attack algorithms. The performance of GE-AdvGAN is comprehensively evaluated by large-scale experiments on different datasets, which results demonstrate the superiority of our algorithm. The code for our algorithm is available at: https://github.com/LMBTough/GE-advGAN
FairCompass: Operationalising Fairness in Machine Learning
Dec 27, 2023As artificial intelligence (AI) increasingly becomes an integral part of our societal and individual activities, there is a growing imperative to develop responsible AI solutions. Despite a diverse assortment of machine learning fairness solutions is proposed in the literature, there is reportedly a lack of practical implementation of these tools in real-world applications. Industry experts have participated in thorough discussions on the challenges associated with operationalising fairness in the development of machine learning-empowered solutions, in which a shift toward human-centred approaches is promptly advocated to mitigate the limitations of existing techniques. In this work, we propose a human-in-the-loop approach for fairness auditing, presenting a mixed visual analytical system (hereafter referred to as 'FairCompass'), which integrates both subgroup discovery technique and the decision tree-based schema for end users. Moreover, we innovatively integrate an Exploration, Guidance and Informed Analysis loop, to facilitate the use of the Knowledge Generation Model for Visual Analytics in FairCompass. We evaluate the effectiveness of FairCompass for fairness auditing in a real-world scenario, and the findings demonstrate the system's potential for real-world deployability. We anticipate this work will address the current gaps in research for fairness and facilitate the operationalisation of fairness in machine learning systems.
MFABA: A More Faithful and Accelerated Boundary-based Attribution Method for Deep Neural Networks
Dec 21, 2023



To better understand the output of deep neural networks (DNN), attribution based methods have been an important approach for model interpretability, which assign a score for each input dimension to indicate its importance towards the model outcome. Notably, the attribution methods use the axioms of sensitivity and implementation invariance to ensure the validity and reliability of attribution results. Yet, the existing attribution methods present challenges for effective interpretation and efficient computation. In this work, we introduce MFABA, an attribution algorithm that adheres to axioms, as a novel method for interpreting DNN. Additionally, we provide the theoretical proof and in-depth analysis for MFABA algorithm, and conduct a large scale experiment. The results demonstrate its superiority by achieving over 101.5142 times faster speed than the state-of-the-art attribution algorithms. The effectiveness of MFABA is thoroughly evaluated through the statistical analysis in comparison to other methods, and the full implementation package is open-source at: https://github.com/LMBTough/MFABA
Towards Understanding the Generalization of Medical Text-to-SQL Models and Datasets
Mar 22, 2023
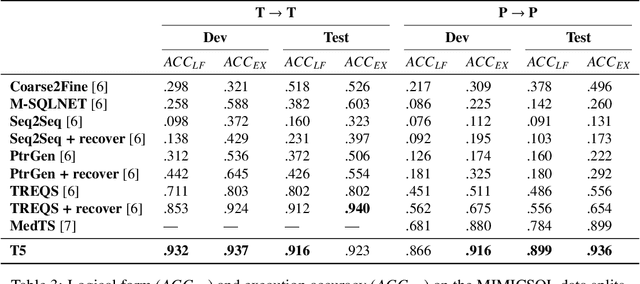
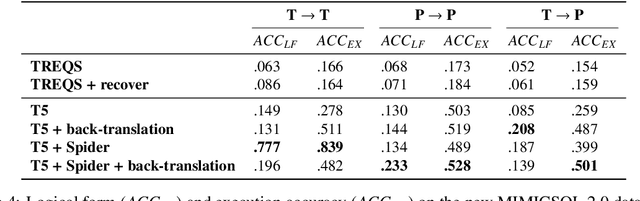
Electronic medical records (EMRs) are stored in relational databases. It can be challenging to access the required information if the user is unfamiliar with the database schema or general database fundamentals. Hence, researchers have explored text-to-SQL generation methods that provide healthcare professionals direct access to EMR data without needing a database expert. However, currently available datasets have been essentially "solved" with state-of-the-art models achieving accuracy greater than or near 90%. In this paper, we show that there is still a long way to go before solving text-to-SQL generation in the medical domain. To show this, we create new splits of the existing medical text-to-SQL dataset MIMICSQL that better measure the generalizability of the resulting models. We evaluate state-of-the-art language models on our new split showing substantial drops in performance with accuracy dropping from up to 92% to 28%, thus showing substantial room for improvement. Moreover, we introduce a novel data augmentation approach to improve the generalizability of the language models. Overall, this paper is the first step towards developing more robust text-to-SQL models in the medical domain.\footnote{The dataset and code will be released upon acceptance.